15 Ecology
Prerequisites
This chapter assumes you have a strong grasp of geographic data analysis and processing, covered in Chapters 2 to 5. The chapter makes use of bridges to GIS software, and spatial cross-validation, covered in Chapters 10 and 12, respectively.
The chapter uses the following packages:
library(sf)
library(terra)
library(dplyr)
library(data.table) # fast data frame manipulation (used by mlr3)
library(mlr3) # machine learning (see Chapter 12)
library(mlr3spatiotempcv) # spatiotemporal resampling
library(mlr3tuning) # hyperparameter tuning package
library(mlr3learners) # interface to most important machine learning pkgs
library(paradox) # defining hyperparameter spaces
library(ranger) # random forest package
library(qgisprocess) # bridge to QGIS (Chapter 10)
library(tree) # decision tree package
library(vegan) # community ecology package15.1 Introduction
This chapter models the floristic gradient of fog oases to reveal distinctive vegetation belts that are clearly controlled by water availability. The case study provides an opportunity to bring together and extend concepts presented in previous chapters to further enhance your skills at using R for geocomputation.
Fog oases, locally called lomas, are vegetation formations found on mountains along the coastal deserts of Peru and Chile. Similar ecosystems can be found elsewhere, including in the deserts of Namibia and along the coasts of Yemen and Oman (Galletti et al. 2016). Despite the arid conditions and low levels of precipitation of around 30-50 mm per year on average, fog deposition increases the amount of water available to plants during austral winter, resulting in green southern-facing mountain slopes along the coastal strip of Peru. The fog, which develops below the temperature inversion caused by the cold Humboldt current in austral winter, provides the name for this habitat. Every few years, the El Niño phenomenon brings torrential rainfall to this sun-baked environment, providing tree seedlings a chance to develop roots long enough to survive the following arid conditions (Dillon et al. 2003).
Unfortunately, fog oases are heavily endangered, primarily due to agriculture and anthropogenic climate change. Evidence on the composition and spatial distribution of the native flora can support efforts to protect remaining fragments of fog oases (Muenchow, Bräuning, et al. 2013; Muenchow, Hauenstein, et al. 2013).
In this chapter you will analyze the composition and the spatial distribution of vascular plants (here referring mostly to flowering plants) on the southern slope of Mt. Mongón, a lomas mountain near Casma on the central northern coast of Peru (Figure 15.1). During a field study to Mt. Mongón, all vascular plants living in 100 randomly sampled 4 by 4 m2 plots in the austral winter of 2011 were recorded (Muenchow, Bräuning, et al. 2013). The sampling coincided with a strong La Niña event that year, as shown in data published by the National Oceanic and Atmospheric Administration (NOAA). This led to even higher levels of aridity than usual in the coastal desert and increased fog activity on the southern slopes of Peruvian lomas mountains.
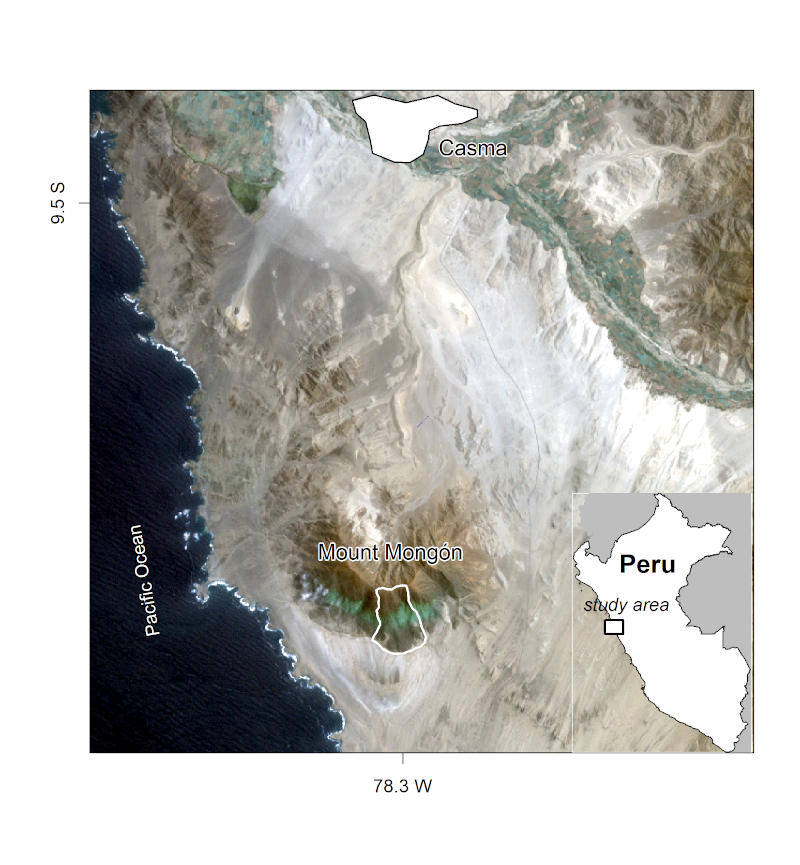
FIGURE 15.1: The Mt. Mongón study area. Figure taken from Muenchow, Schratz, and Brenning (2017).
This chapter also demonstrates how to apply techniques covered in previous chapters to an important applied field: ecology. Specifically, we will:
- Load in needed data and compute environmental predictors (Section 15.2)
- Extract the main floristic gradient from our species composition matrix with the help of a dimension-reducing technique (ordinations; Section 15.3)
- Model the first ordination axis, i.e., the floristic gradient, as a function of environmental predictors such as altitude, slope, catchment area and NDVI (Section 15.4). For this, we will make use of a random forest model — a very popular machine learning algorithm (Breiman 2001). To guarantee an optimal prediction, it is advisable to tune beforehand the hyperparameters with the help of spatial cross-validation (see Section 12.5.2)
- Make a spatial distribution map of the floristic composition anywhere in the study area (Section 15.4.2)
15.2 Data and data preparation
All the data needed for the subsequent analyses is available via the spDataLarge package.
data("study_area", "random_points", "comm", package = "spDataLarge")
dem = rast(system.file("raster/dem.tif", package = "spDataLarge"))
ndvi = rast(system.file("raster/ndvi.tif", package = "spDataLarge"))study_area is a polygon representing the outline of the study area, and random_points is an sf object containing the 100 randomly chosen sites.
comm is a community matrix of the wide data format (Wickham 2014) where the rows represent the visited sites in the field and the columns the observed species.98
# sites 35 to 40 and corresponding occurrences of the first five species in the
# community matrix
comm[35:40, 1:5]
#> Alon_meri Alst_line Alte_hali Alte_porr Anth_eccr
#> 35 0 0 0 0.0 1.000
#> 36 0 0 1 0.0 0.500
#> 37 0 0 0 0.0 0.125
#> 38 0 0 0 0.0 3.000
#> 39 0 0 0 0.0 2.000
#> 40 0 0 0 0.2 0.125The values represent species cover per site, and were recorded as the area covered by a species in proportion to the site area (%; please note that one site can have >100% due to overlapping cover between individual plants).
The rownames of comm correspond to the id column of random_points.
dem is the digital elevation model (DEM) for the study area, and ndvi is the Normalized Difference Vegetation Index (NDVI) computed from the red and near-infrared channels of a Landsat scene (see Section 4.3.3 and ?spDataLarge::ndvi.tif).
Visualizing the data helps to get more familiar with it, as shown in Figure 15.2 where the dem is overplotted by the random_points and the study_area.
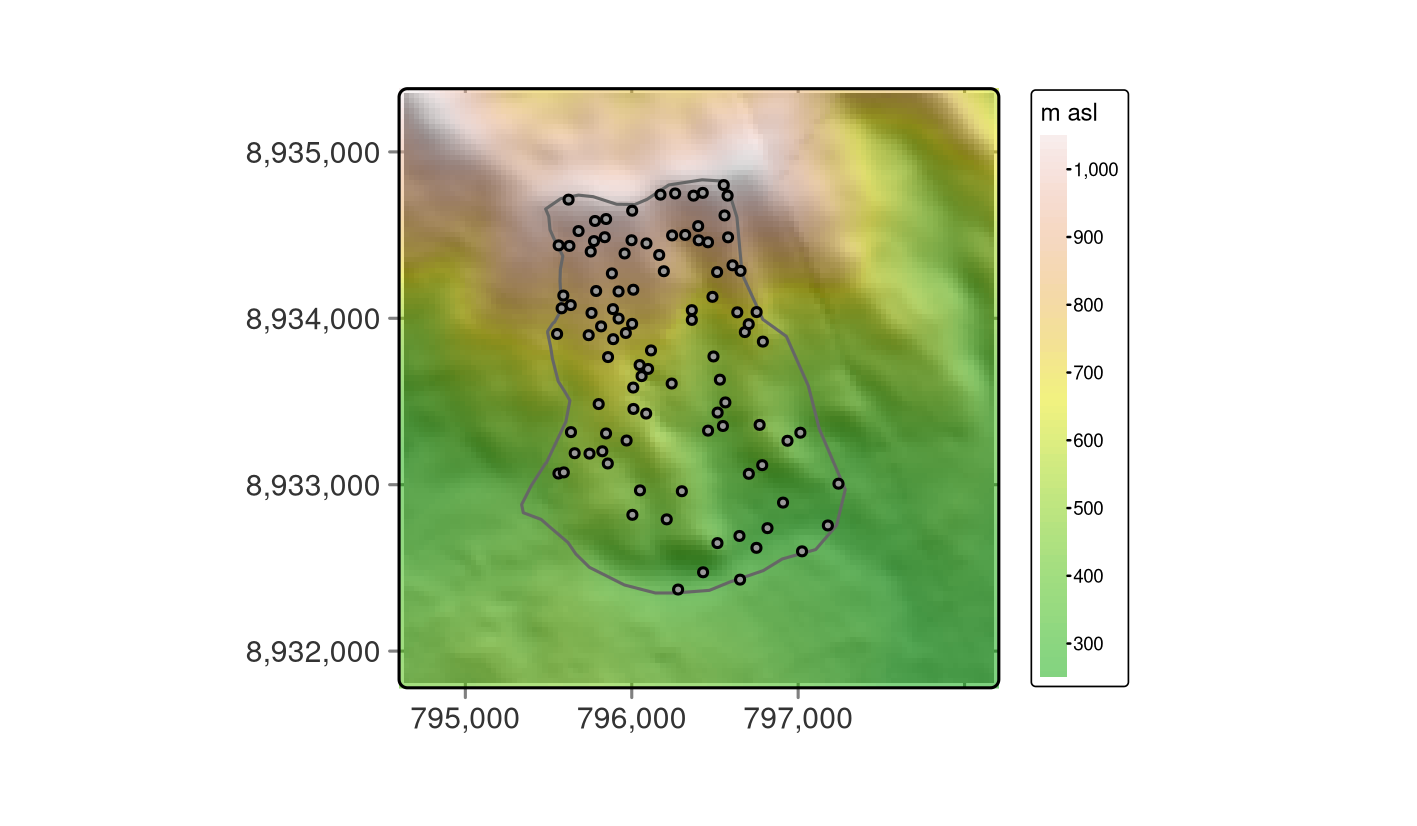
FIGURE 15.2: Study mask (polygon), location of the sampling sites (black points) and DEM in the background.
The next step is to compute variables which are not only needed for the modeling and predictive mapping (see Section 15.4.2) but also for aligning the non-metric multidimensional scaling (NMDS) axes with the main gradient in the study area, altitude and humidity, respectively (see Section 15.3).
Specifically, we compute catchment slope and catchment area from a digital elevation model using R-GIS bridges (see Chapter 10). Curvatures might also represent valuable predictors, and in the Exercise section you can find out how they would impact the modeling result.
To compute catchment area and catchment slope, we use the Rsagacmd package which calls SAGA GIS from R (see also Section 10.3).
Rsagacmd auto-generates an R interface from the saga_cmd help, so each SAGA library appears as a list and each tool as a function on the saga object.
Printing a tool returns its description and a tibble of all parameters (type, R argument name, SAGA identifier, default), which makes it easy to look up what is available.
library(Rsagacmd)
# initialize the link to SAGA; saga_cmd must be installed on the system
saga = saga_gis()
saga$ta_hydrology$saga_wetness_index
#> Help for library = ta_hydrology; tool = saga_wetness_index:
#> Author: J.Boehner, O.Conrad (c) 2001
#> Description: The 'SAGA Wetness Index' is similar to the 'Topographic
#> Wetness Index' (TWI) but uses a modified catchment area, predicting a
#> more realistic, higher potential soil moisture in valley floors.
#>
#> # A tibble: 12 × 7
#> parameter type argument identifier default available_opts
#> <chr> <chr> <chr> <chr> <dbl> <chr>
#> 1 Elevation grid dem DEM NA NA
#> 2 Weights grid weight WEIGHT NA NA
#> 3 Catchment Area grid area AREA NA NA
#> 4 Catchment Slope grid slope SLOPE NA NA
#> 5 Modified Catchm… grid area_mod AREA_MOD NA NA
#> 6 Topographic Wet… grid twi TWI NA NA
#> 7 Suction floa… suction SUCTION 10 …
#> 8 Type of Area choi… area_type AREA_TYPE 2 [0] total …
#> 9 Type of Slope choi… slope_type SLOPE_TYPE 1 [0] local …
#> ...The dem argument is required (the digital elevation model).
Setting slope_type = 1 requests the catchment slope rather than the local slope (which is the SAGA default).
The tool returns four rasters in a single call – catchment area (area), catchment slope (slope), modified catchment area (area_mod), and a topographic wetness index variant (twi).
saga_twi = saga$ta_hydrology$saga_wetness_index(dem = dem, slope_type = 1)saga_twi is a list of SpatRaster objects.
We build the environmental predictor stack by combining catchment area and catchment slope with the previously loaded dem and ndvi, and we log-transform catchment area which is highly right-skewed (hist(ep$carea)).
ep = c(dem, ndvi, saga_twi$area, saga_twi$slope)
names(ep) = c("dem", "ndvi", "carea", "cslope")
ep$carea = log10(ep$carea)For the small DEM used here, exchanging rasters between R and SAGA in memory is fine.
For larger datasets, you can instead point Rsagacmd at file paths for inputs and outputs (e.g., dem = "path/to/dem.tif", area = "path/to/carea.tif"), so the rasters never need to be loaded into R.
As a convenience to the reader, the resulting ep is also available in spDataLarge:
ep = rast(system.file("raster/ep.tif", package = "spDataLarge"))Finally, we can extract the terrain attributes to our field observations (see also Section 6.3).
15.3 Reducing dimensionality
Ordinations are a popular tool in vegetation science to extract the main information, frequently corresponding to ecological gradients, from large species-plot matrices mostly filled with 0s.
However, they are also used in remote sensing, the soil sciences, geomarketing and many other fields.
If you are unfamiliar with ordination techniques or in need of a refresher, have a look at Michael W. Palmer’s webpage for a short introduction to popular ordination techniques in ecology and at Borcard et al. (2011) for a deeper look on how to apply these techniques in R.
vegan’s package documentation is also a very helpful resource (vignette(package = "vegan")).
Principal component analysis (PCA) is probably the most famous ordination technique. It is a great tool to reduce dimensionality if one can expect linear relationships between variables, and if the joint absence of a variable in two plots (observations) can be considered a similarity. This is barely the case with vegetation data.
For one, the presence of a plant often follows a unimodal, i.e., a non-linear, relationship along a gradient (e.g., humidity, temperature or salinity) with a peak at the most favorable conditions and declining ends towards the unfavorable conditions.
Secondly, the joint absence of a species in two plots is hardly an indication for similarity. Suppose a plant species is absent from the driest (e.g., an extreme desert) and the moistest locations (e.g., a tree savanna) of our sampling. Then we really should refrain from counting this as a similarity because it is very likely that the only thing these two completely different environmental settings have in common in terms of floristic composition is the shared absence of species (except for rare ubiquitous species).
NMDS is one popular dimension-reducing technique used in ecology (von Wehrden et al. 2009).
NMDS reduces the rank-based differences between distances between objects in the original matrix and distances between the ordinated objects.
The difference is expressed as stress.
The lower the stress value, the better the ordination, i.e., the low-dimensional representation of the original matrix.
Stress values lower than 10 represent an excellent fit, stress values of around 15 are still good, and values greater than 20 represent a poor fit (McCune et al. 2002).
In R, metaMDS() of the vegan package can execute a NMDS.
As input, it expects a community matrix with the sites as rows and the species as columns.
Often ordinations using presence-absence data yield better results (in terms of explained variance) though the prize is, of course, a less informative input matrix (see also Exercises).
decostand() converts numerical observations into presences and absences with 1 indicating the occurrence of a species and 0 the absence of a species.
Ordination techniques such as NMDS require at least one observation per site.
Hence, we need to dismiss all sites in which no species were found.
# presence-absence matrix
pa = vegan::decostand(comm, "pa") # 100 rows (sites), 69 columns (species)
# keep only sites in which at least one species was found
pa = pa[rowSums(pa) != 0, ] # 84 rows, 69 columnsThe resulting matrix serves as input for the NMDS.
k specifies the number of output axes, here, set to 4.99
NMDS is an iterative procedure trying to make the ordinated space more similar to the input matrix in each step.
To make sure that the algorithm converges, we set the number of steps to 500 using the try parameter.
set.seed(25072018)
nmds = vegan::metaMDS(comm = pa, k = 4, try = 500)
nmds$stress
#> ...
#> Run 498 stress 0.08834745
#> ... Procrustes: rmse 0.004100446 max resid 0.03041186
#> Run 499 stress 0.08874805
#> ... Procrustes: rmse 0.01822361 max resid 0.08054538
#> Run 500 stress 0.08863627
#> ... Procrustes: rmse 0.01421176 max resid 0.04985418
#> *** Solution reached
#> 0.08831395A stress value of 9 represents a very good result, which means that the reduced ordination space represents the large majority of the variance of the input matrix.
Overall, NMDS puts objects that are more similar (in terms of species composition) closer together in ordination space.
However, as opposed to most other ordination techniques, the axes are arbitrary and not necessarily ordered by importance (Borcard et al. 2011).
However, we already know that humidity represents the main gradient in the study area (Muenchow, Bräuning, et al. 2013; Muenchow et al. 2017).
Since humidity is highly correlated with elevation, we rotate the NMDS axes in accordance with elevation (see also ?MDSrotate for more details on rotating NMDS axes).
Plotting the result reveals that the first axis is, as intended, clearly associated with altitude (Figure 15.3).
elev = dplyr::filter(random_points, id %in% rownames(pa)) |>
dplyr::pull(dem)
# rotating NMDS in accordance with altitude (proxy for humidity)
rotnmds = vegan::MDSrotate(nmds, elev)
# extracting the first two axes
sc = vegan::scores(rotnmds, choices = 1:2, display = "sites")
# plotting the first axis against altitude
plot(y = sc[, 1], x = elev, xlab = "elevation in m",
ylab = "First NMDS axis", cex.lab = 0.8, cex.axis = 0.8)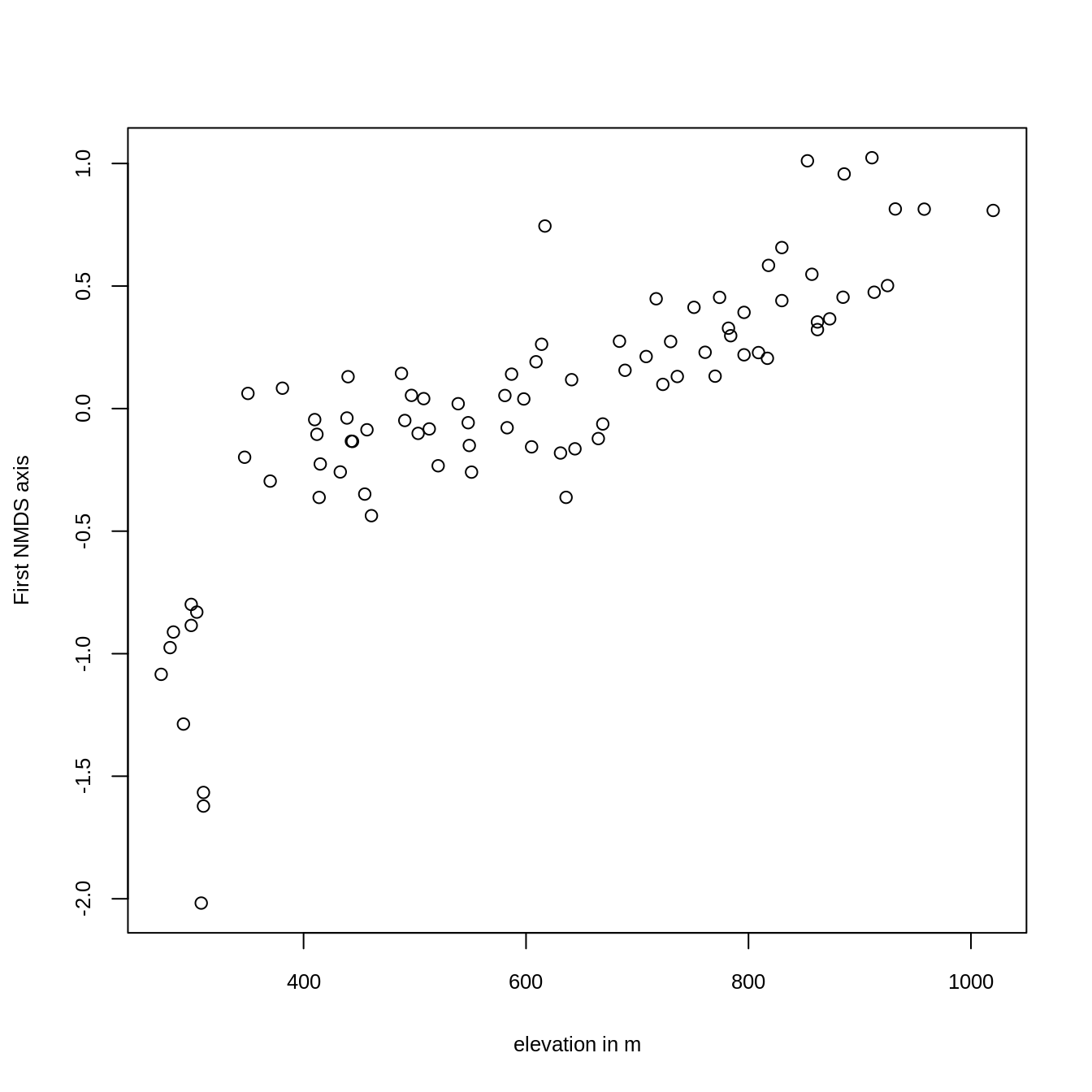
FIGURE 15.3: Plotting the first NMDS axis against altitude.
The scores of the first NMDS axis represent the different vegetation formations, i.e., the floristic gradient, appearing along the slope of Mt. Mongón. To spatially visualize them, we can model the NMDS scores with the previously created predictors (Section 15.2), and use the resulting model for predictive mapping (see Section 15.4).
15.4 Modeling the floristic gradient
To predict the floristic gradient spatially, we use a random forest model. Random forest models are frequently applied in environmental and ecological modeling, and often provide the best results in terms of predictive performance (Hengl et al. 2018; Schratz et al. 2019). Here, we shortly introduce decision trees and bagging, since they form the basis of random forests. We refer the reader to James et al. (2013) for a more detailed description of random forests and related techniques.
To introduce decision trees by example, we first construct a response-predictor matrix by joining the rotated NMDS scores to the field observations (random_points).
We will also use the resulting data frame for the mlr3 modeling later on.
# construct response-predictor matrix
# id- and response variable
rp = data.frame(id = as.numeric(rownames(sc)), sc = sc[, 1])
# join the predictors (dem, ndvi and terrain attributes)
rp = inner_join(random_points, rp, by = "id")Decision trees split the predictor space into a number of regions.
To illustrate this, we apply a decision tree to our data using the scores of the first NMDS axis as the response (sc) and altitude (dem) as the only predictor.
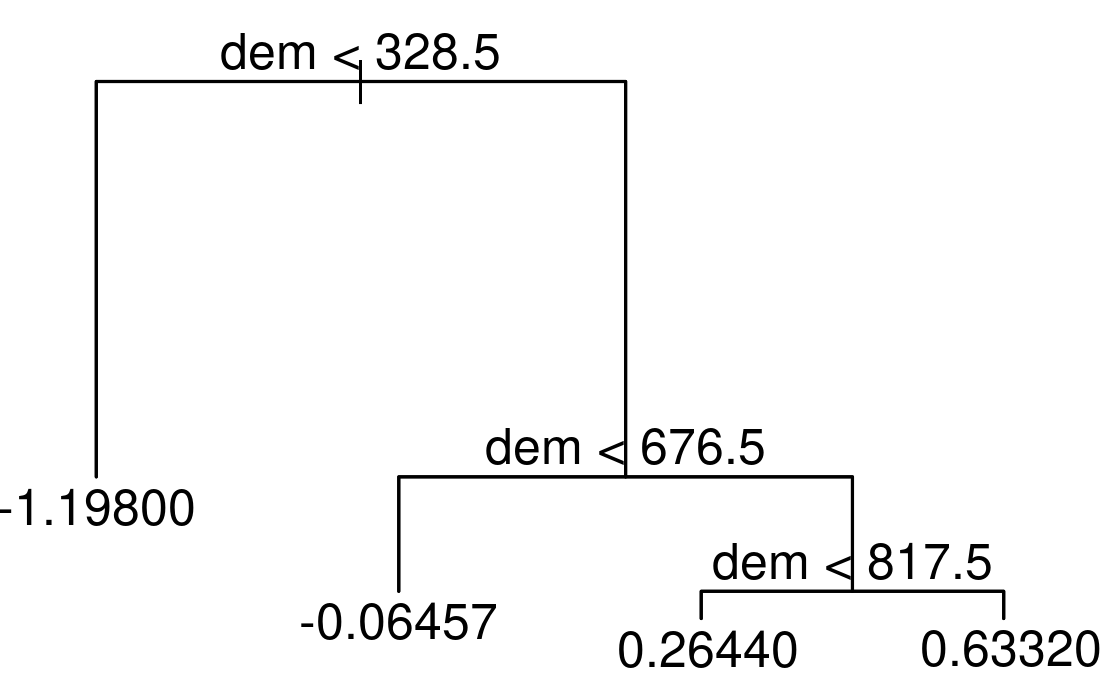
FIGURE 15.4: Simple example of a decision tree with three internal nodes and four terminal nodes.
The resulting tree consists of three internal nodes and four terminal nodes (Figure 15.4). The first internal node at the top of the tree assigns all observations which are below 328.5 m to the left and all other observations to the right branch. The observations falling into the left branch have a mean NMDS score of -1.198. Overall, we can interpret the tree as follows: the higher the elevation, the higher the NMDS score becomes. This means that the simple decision tree has already revealed four distinct floristic assemblages. For a more in-depth interpretation, please refer to Section 15.4.2. Decision trees have a tendency to overfit, that is, they mirror too closely the input data including its noise which in turn leads to bad predictive performances (Section 12.4, James et al. 2013). Bootstrap aggregation (bagging) is an ensemble technique that can help to overcome this problem. Ensemble techniques simply combine the predictions of multiple models. Thus, bagging takes repeated samples from the same input data and averages the predictions. This reduces the variance and overfitting with the result of a much better predictive accuracy compared to decision trees. Finally, random forests extend and improve bagging by decorrelating trees which is desirable since averaging the predictions of highly correlated trees shows a higher variance and thus lower reliability than averaging predictions of decorrelated trees (James et al. 2013). To achieve this, random forests use bagging, but in contrast to the traditional bagging where each tree is allowed to use all available predictors, random forests only use a random sample of all available predictors.
15.4.1 mlr3 building blocks
The code in this section largely follows the steps we have introduced in Section 12.5.2. The only differences are the following:
- The response variable is numeric, hence a regression task will replace the classification task of Section 12.5.2
- Instead of the AUROC which can only be used for categorical response variables, we will use the root mean squared error (RMSE) as the performance measure
- We use a Random Forest model instead of a Support Vector Machine which naturally goes along with different hyperparameters
- We are leaving the assessment of a bias-reduced performance measure as an exercise to the reader (see Exercises). Instead, we show how to tune hyperparameters for (spatial) predictions
Remember that 125,500 models were necessary to retrieve bias-reduced performance estimates when using 100-repeated 5-fold spatial cross-validation and a random search of 50 iterations in Section 12.5.2. In the hyperparameter tuning level, we found the best hyperparameter combination which in turn was used in the outer performance level for predicting the test data of a specific spatial partition (see also Figure 12.6). This was done for five spatial partitions, and repeated a 100 times yielding in total 500 optimal hyperparameter combinations. Which one should we use for making spatial distribution maps? The answer is simple: none at all. Remember, the tuning was done to retrieve a bias-reduced performance estimate, not to do the best possible spatial prediction. For the latter, one estimates the best hyperparameter combination from the complete dataset. This means, the inner hyperparameter tuning level is no longer needed, which makes perfect sense since we are applying our model to new data (unvisited field observations) for which the true outcomes are unavailable, hence testing is impossible in any case. Therefore, we tune the hyperparameters for a good spatial prediction on the complete dataset via a 5-fold spatial CV with one repetition.
Having already constructed the input variables (rp), we are all set for specifying the mlr3 building blocks (task, learner, and resampling).
For specifying a spatial task, we use again the mlr3spatiotempcv package (Schratz et al. 2021, Section 12.5), and since our response (sc) is numeric, we use a regression task.
# create task
task = mlr3spatiotempcv::as_task_regr_st(
select(rp, -id, -spri),
target = "sc",
id = "mongon"
)Using an sf object as the backend automatically provides the geometry information needed for the spatial partitioning later on.
Additionally, we got rid of the columns id and spri, since these variables should not be used as predictors in the modeling.
Next, we go on to construct a random forest learner from the ranger package (Wright and Ziegler 2017).
lrn_rf = lrn("regr.ranger", predict_type = "response")As opposed to, for example, Support Vector Machines (see Section 12.5.2), random forests often already show good performances when used with the default values of their hyperparameters (which may be one reason for their popularity).
Still, tuning often moderately improves model results, and thus is worth the effort (Probst et al. 2018).
In random forests, the hyperparameters mtry, min.node.size and sample.fraction determine the degree of randomness, and should be tuned (Probst et al. 2018).
mtry indicates how many predictor variables should be used in each tree.
If all predictors are used, then this corresponds in fact to bagging (see beginning of Section 15.4).
The sample.fraction parameter specifies the fraction of observations to be used in each tree.
Smaller fractions lead to greater diversity, and thus less correlated trees which often is desirable (see above).
The min.node.size parameter indicates the number of observations a terminal node should at least have (see also Figure 15.4).
Naturally, as trees and computing time become larger, the lower the min.node.size.
Hyperparameter combinations will be selected randomly but should fall inside specific tuning limits (created with paradox::ps()).
mtry should range between 1 and the number of predictors (4) , sample.fraction should range between 0.2 and 0.9 and min.node.size should range between 1 and 10 (Probst et al. 2018).
# specifying the search space
search_space = paradox::ps(
mtry = paradox::p_int(lower = 1, upper = ncol(task$data()) - 1),
sample.fraction = paradox::p_dbl(lower = 0.2, upper = 0.9),
min.node.size = paradox::p_int(lower = 1, upper = 10)
)Having defined the search space, we are all set for specifying our tuning via the AutoTuner() function.
Since we deal with geographic data, we will again make use of spatial cross-validation to tune the hyperparameters (see Sections 12.4 and 12.5).
Specifically, we will use a 5-fold spatial partitioning with only one repetition (rsmp()).
In each of these spatial partitions, we run 50 models (trm()) while using randomly selected hyperparameter configurations (tnr()) within predefined limits (seach_space) to find the optimal hyperparameter combination (see also Section 12.5.2 and https://mlr3book.mlr-org.com/chapters/chapter4/hyperparameter_optimization.html#sec-autotuner, Bischl et al. 2024).
The performance measure is the root mean squared error (RMSE).
autotuner_rf = mlr3tuning::auto_tuner(
learner = lrn_rf,
resampling = mlr3::rsmp("spcv_coords", folds = 5), # spatial partitioning
measure = mlr3::msr("regr.rmse"), # performance measure
terminator = mlr3tuning::trm("evals", n_evals = 50), # specify 50 iterations
search_space = search_space, # predefined hyperparameter search space
tuner = mlr3tuning::tnr("random_search") # specify random search
)Calling the train()-method of the AutoTuner-object finally runs the hyperparameter tuning, and will find the optimal hyperparameter combination for the specified parameters.
# hyperparameter tuning
set.seed(19012026)
autotuner_rf$train(task)
autotuner_rf$tuning_result
#> mtry sample.fraction min.node.size learner_param_vals x_domain regr.rmse
#> <int> <num> <int> <list> <list> <num>
#> 1: 4 0.803 2 <list[5]> <list[3]> 0.3815.4.2 Predictive mapping
The tuned hyperparameters can now be used for the prediction.
To do so, we only need to run the predict method of our fitted AutoTuner object.
# predicting using the best hyperparameter combination
autotuner_rf$predict(task)
#>
#> ── <PredictionRegr> for 84 observations: ───────────────────────────────────────
#> row_ids truth response
#> 1 -1.084 -1.080
#> 2 -0.975 -1.030
#> 3 -0.912 -0.929
#> --- --- ---
#> 82 0.814 0.637
#> 83 0.814 0.785
#> 84 0.808 0.824The predict method will apply the model to all observations used in the modeling.
Given a multi-layer SpatRaster containing rasters named as the predictors used in the modeling, terra::predict() will also make spatial distribution maps, i.e., predict to new data.
As an alternative, you can also use the dedicated mlr3spatial package for doing spatial predictions.
pred = terra::predict(ep, model = autotuner_rf$learner$model$model, fun = predict)
# doing the same using mlr3spatial
# pred = mlr3spatial::predict_spatial(newdata = ep, learner = autotuner_rf)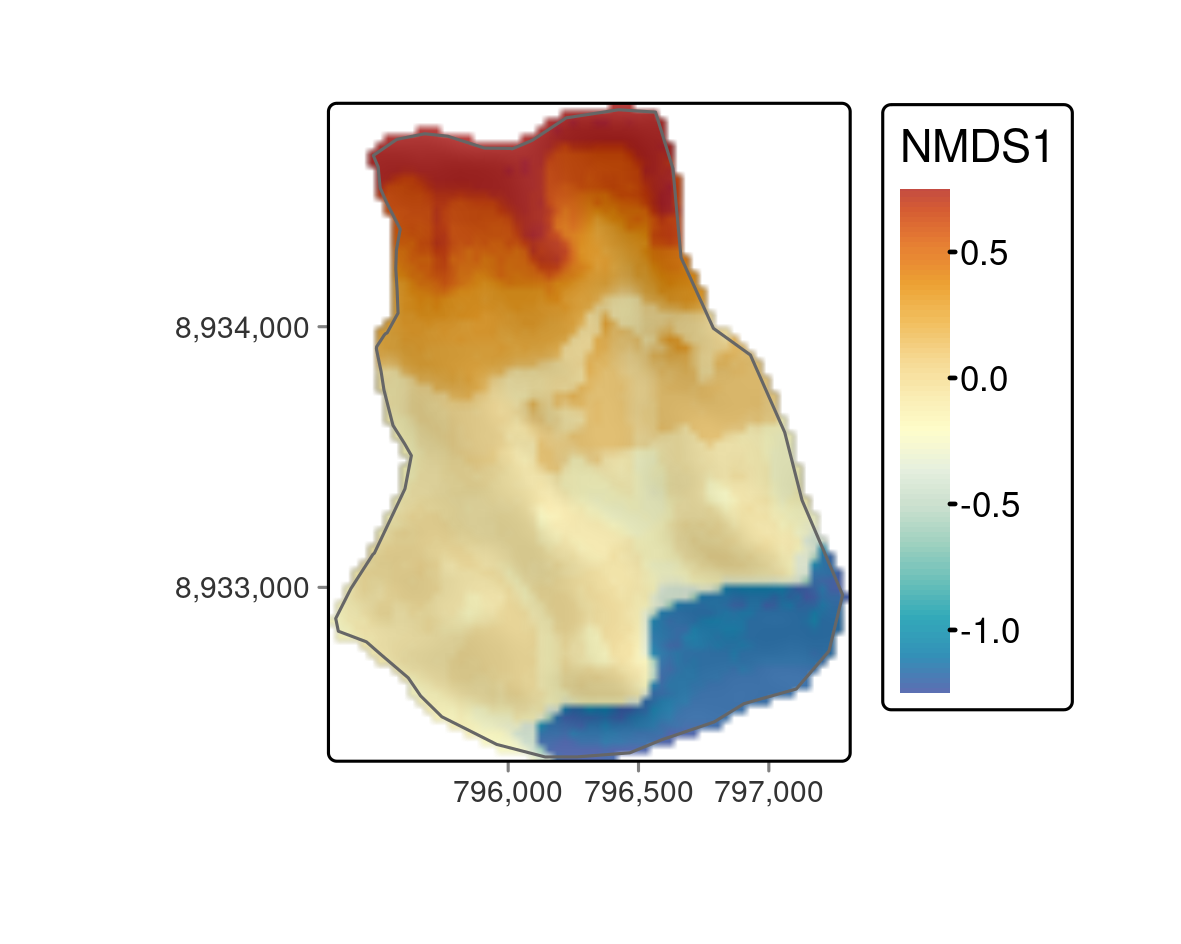
FIGURE 15.5: Predictive mapping of the floristic gradient clearly revealing distinct vegetation belts.
In case, terra::predict() does not support a model algorithm, you can still make the predictions manually.
newdata = as.data.frame(as.matrix(ep))
colSums(is.na(newdata)) # 0 NAs
# but assuming there were 0s results in a more generic approach
ind = rowSums(is.na(newdata)) == 0
tmp = autotuner_rf$predict_newdata(newdata = newdata[ind, ], task = task)
newdata[ind, "pred"] = data.table::as.data.table(tmp)[["response"]]
pred_2 = ep$dem
# now fill the raster with the predicted values
pred_2[] = newdata$pred
# check if terra and our manual prediction is the same
all(values(pred - pred_2) == 0)The predictive mapping clearly reveals distinct vegetation belts (Figure 15.5). Please refer to Muenchow, Hauenstein, et al. (2013) for a detailed description of vegetation belts on lomas mountains. The blue color tones represent the so-called Tillandsia belt. Tillandsia is a highly adapted genus especially found in high quantities at the sandy and quite desertic foot of lomas mountains. The yellow color tones refer to a herbaceous vegetation belt with a much higher plant cover compared to the Tillandsia belt. The orange colors represent the bromeliad belt, which features the highest species richness and plant cover. It can be found directly beneath the temperature inversion (ca. 750-850 m asl) where humidity due to fog is highest. Water availability naturally decreases above the temperature inversion, and the landscape becomes desertic again with only a few succulent species (succulent belt; red colors). Interestingly, the spatial prediction clearly reveals that the bromeliad belt is interrupted, which is a very interesting finding we would have not detected without the predictive mapping.
15.5 Conclusions
In this chapter we have ordinated the community matrix of the lomas Mt. Mongón with the help of a NMDS (Section 15.3).
The first axis, representing the main floristic gradient in the study area, was modeled as a function of environmental predictors which partly were derived through R-GIS bridges (Section 15.2).
The mlr3 package provided the building blocks to spatially tune the hyperparameters mtry, sample.fraction and min.node.size (Section 15.4.1).
The tuned hyperparameters served as input for the final model which in turn was applied to the environmental predictors for a spatial representation of the floristic gradient (Section 15.4.2).
The result demonstrates spatially the astounding biodiversity in the middle of the desert.
Since lomas mountains are heavily endangered, the prediction map can serve as basis for informed decision-making on delineating protection zones, and making the local population aware of the uniqueness found in their immediate neighborhood.
In terms of methodology, a few additional points could be addressed:
- It would be interesting to also model the second ordination axis, and to subsequently find an innovative way of visualizing jointly the modeled scores of the two axes in one prediction map
- If we were interested in interpreting the model in an ecologically meaningful way, we should probably use (semi-)parametric models (Muenchow, Bräuning, et al. 2013; Zuur et al. 2009; Zuur et al. 2017). However, there are at least approaches that help to interpret machine learning models such as random forests (see, e.g., https://mlr-org.com/posts/2018-04-30-interpretable-machine-learning-iml-and-mlr/)
- A sequential model-based optimization (SMBO) might be preferable to the random search for hyperparameter optimization used in this chapter (Probst et al. 2018)
Finally, please note that random forest and other machine learning models are frequently used in a setting with much more observations and predictors than used in this Chapter, and where it is unclear which variables and variable interactions contribute to explaining the response. Additionally, the relationships might be highly non-linear. In our use case, the relationship between response and predictors is pretty clear, there is only a slight amount of non-linearity and the number of observations and predictors is low. Hence, it might be worth trying a linear model. A linear model is much easier to explain and understand than a random forest model, and therefore preferred (law of parsimony). Additionally it is computationally less demanding (see Exercises). If the linear model cannot cope with the degree of non-linearity present in the data, one could also try a generalized additive model (GAM). The point here is that the toolbox of a data scientist consists of more than one tool, and it is your responsibility to select the tool best suited for the task or purpose at hand. Here, we wanted to introduce the reader to random forest modeling and how to use the corresponding results for predictive mapping purposes. For this purpose, a well-studied dataset with known relationships between response and predictors, is appropriate. However, this does not imply that the random forest model has returned the best result in terms of predictive performance.
15.6 Exercises
The solutions assume the following packages are attached (other packages will be attached when needed):
E1. Run a NMDS using the percentage data of the community matrix. Report the stress value and compare it to the stress value as retrieved from the NMDS using presence-absence data. What might explain the observed difference?
E2. Compute all the predictor rasters we have used in the chapter (catchment slope, catchment area), and put them into a SpatRaster-object.
Add dem and ndvi to it.
Next, compute profile and tangential curvature and add them as additional predictor rasters (hint: grass:r.slope.aspect).
Finally, construct a response-predictor matrix.
The scores of the first NMDS axis (which were the result when using the presence-absence community matrix) rotated in accordance with elevation represent the response variable, and should be joined to random_points (use an inner join).
To complete the response-predictor matrix, extract the values of the environmental predictor raster object to random_points.
E3. Retrieve the bias-reduced RMSE of a random forest and a linear model using spatial cross-validation.
The random forest modeling should include the estimation of optimal hyperparameter combinations (random search with 50 iterations) in an inner tuning loop.
Parallelize the tuning level.
Report the mean RMSE and use a boxplot to visualize all retrieved RMSEs.
Please note that this exercise is best solved using the mlr3 functions benchmark_grid() and benchmark() (see https://mlr3book.mlr-org.com/perf-eval-cmp.html#benchmarking for more information).