4 Spatial data operations
Prerequisites
- This chapter requires the same packages used in Chapter 3:
4.1 Introduction
Spatial operations, including spatial joins between vector datasets and local and focal operations on raster datasets, are a vital part of geocomputation. This chapter shows how spatial objects can be modified in a multitude of ways based on their location and shape. Many spatial operations have a non-spatial (attribute) equivalent, so concepts such as subsetting and joining datasets demonstrated in the previous chapter are applicable here. This is especially true for vector operations: Section 3.2 on vector attribute manipulation provides the basis for understanding its spatial counterpart, namely spatial subsetting (covered in Section 4.2.1). Spatial joining (Sections 4.2.5, 4.2.6 and 4.2.8) and aggregation (Section 4.2.7) also have non-spatial counterparts, covered in the previous chapter.
Spatial operations differ from non-spatial operations in a number of ways, however: spatial joins, for example, can be done in a number of ways — including matching entities that intersect with or are within a certain distance of the target dataset — while the attribution joins discussed in Section 3.2.4 in the previous chapter can only be done in one way (except when using fuzzy joins, as described in the documentation of the fuzzyjoin package). Different types of spatial relationship between objects, including intersects and disjoint, are described in Sections 4.2.2 and 4.2.4. Another unique aspect of spatial objects is distance: all spatial objects are related through space, and distance calculations can be used to explore the strength of this relationship, as described in the context of vector data in Section 4.2.3.
Spatial operations on raster objects include subsetting — covered in Section 4.3.1. Map algebra covers a range of operations that modify raster cell values, with or without reference to surrounding cell values. The concept of map algebra, vital for many applications, is introduced in Section 4.3.2; local, focal and zonal map algebra operations are covered in sections 4.3.3, 4.3.4, and 4.3.5, respectively. Global map algebra operations, which generate summary statistics representing an entire raster dataset, and distance calculations on rasters, are discussed in Section 4.3.6. Next, the relationships between map algebra and vector operations are discussed in Section 4.3.7. In the Section 4.3.8,1 the process of merging two raster datasets is discussed and demonstrated with reference to a reproducible example.
4.2 Spatial operations on vector data
This section provides an overview of spatial operations on vector geographic data represented as simple features in the sf package. Section 4.3 presents spatial operations on raster datasets using classes and functions from the terra package.
4.2.1 Spatial subsetting
Spatial subsetting is the process of taking a spatial object and returning a new object containing only features that relate in space to another object.
Analogous to attribute subsetting (covered in Section 3.2.1), subsets of sf data frames can be created with square bracket ([) operator using the syntax x[y, , op = st_intersects], where x is an sf object from which a subset of rows will be returned, y is the ‘subsetting object’ and , op = st_intersects is an optional argument that specifies the topological relation (also known as the binary predicate) used to do the subsetting.
The default topological relation used when an op argument is not provided is st_intersects(): the command x[y, ] is identical to x[y, , op = st_intersects] shown above but not x[y, , op = st_disjoint] (the meaning of these and other topological relations is described in the next section).
The filter() function from the tidyverse can also be used, but this approach is more verbose, as we will see in the examples below.
To demonstrate spatial subsetting, we will use the nz and nz_height datasets in the spData package, which contain geographic data on the 16 main regions and 101 highest points in New Zealand, respectively (Figure 4.1), in a projected coordinate reference system.
The following code chunk creates an object representing Canterbury, then uses spatial subsetting to return all high points in the region.
canterbury = nz |> filter(Name == "Canterbury")
canterbury_height = nz_height[canterbury, ]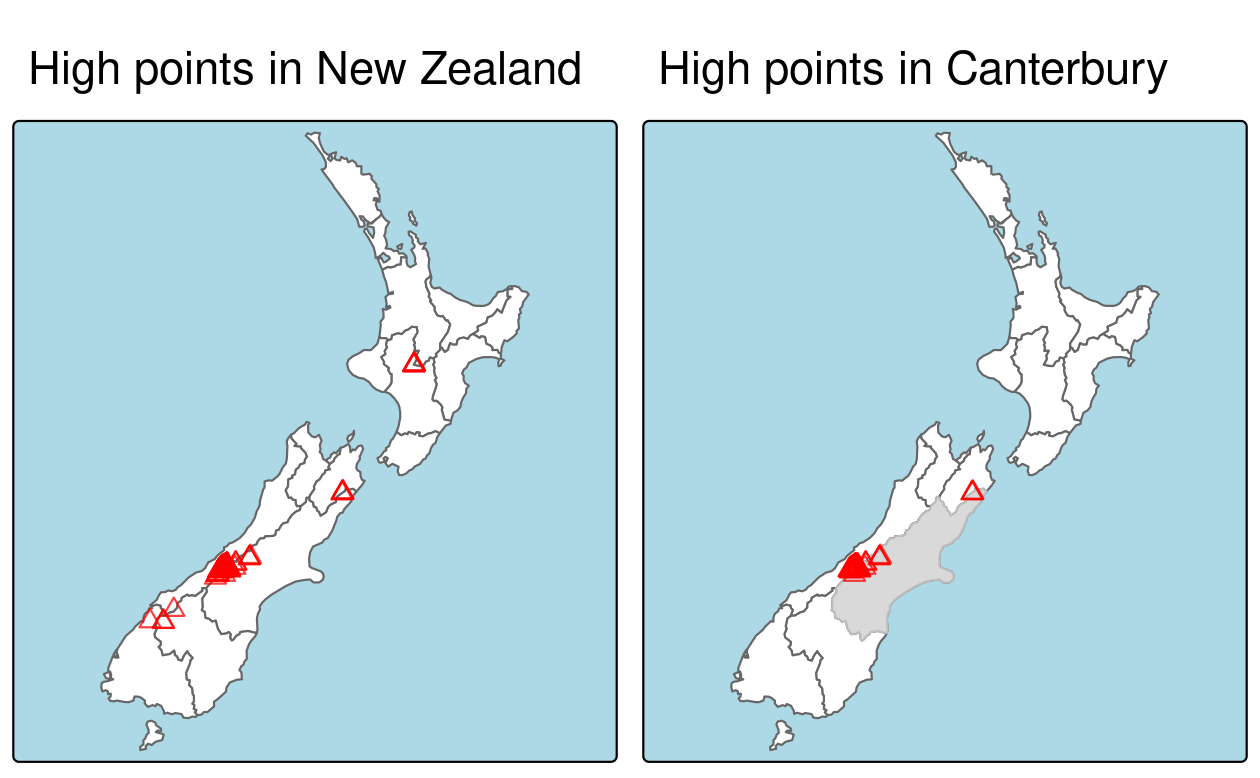
FIGURE 4.1: Spatial subsetting, with red triangles representing 101 high points in New Zealand, clustered near the central Canterbuy region (left). The points in Canterbury were created with the [ subsetting operator (highlighted in gray, right).
Like attribute subsetting, the command x[y, ] (equivalent to nz_height[canterbury, ]) subsets features of a target x using the contents of a source object y.
Instead of y being a vector of class logical or integer, however, for spatial subsetting both x and y must be geographic objects.
Specifically, objects used for spatial subsetting in this way must have the class sf or sfc: both nz and nz_height are geographic vector data frames and have the class sf, and the result of the operation returns another sf object representing the features in the target nz_height object that intersect with (in this case high points that are located within) the canterbury region.
Various topological relations can be used for spatial subsetting which determine the type of spatial relationship that features in the target object must have with the subsetting object to be selected.
These include touches, crosses or within, as we will see shortly in Section 4.2.2.
The default setting st_intersects is a ‘catch all’ topological relation that will return features in the target that touch, cross or are within the source ‘subsetting’ object.
Alternative spatial operators can be specified with the op = argument, as demonstrated in the following command which returns the opposite of st_intersects(), points that do not intersect with Canterbury (see Section 4.2.2).
nz_height[canterbury, , op = st_disjoint], , — in the preceding code chunk is included to highlight op, the third argument in [ for sf objects.
One can use this to change the subsetting operation in many ways.
nz_height[canterbury, 2, op = st_disjoint], for example, returns the same rows but only includes the second attribute column (see sf::`[.sf` and the ?sf for details).
For many applications, this is all you’ll need to know about spatial subsetting for vector data: it just works.
If you are impatient to learn about more topological relations, beyond st_intersects() and st_disjoint(), skip to the next section (4.2.2).
If you’re interested in the details, including other ways of subsetting, read on.
Another way of doing spatial subsetting uses objects returned by topological operators. These objects can be useful in their own right, for example when exploring the graph network of relationships between contiguous regions, but they can also be used for subsetting, as demonstrated in the code chunk below.
sel_sgbp = st_intersects(x = nz_height, y = canterbury)
class(sel_sgbp)
#> [1] "sgbp" "list"
sel_sgbp
#> Sparse geometry binary predicate list of length 101, where the
#> predicate was `intersects'
#> first 10 elements:
#> 1: (empty)
#> 2: (empty)
#> 3: (empty)
#> 4: (empty)
#> 5: 1
#> 6: 1
....
sel_logical = lengths(sel_sgbp) > 0
canterbury_height2 = nz_height[sel_logical, ]The above code chunk creates an object of class sgbp (a sparse geometry binary predicate, a list of length x in the spatial operation) and then converts it into a logical vector sel_logical (containing only TRUE and FALSE values, something that can also be used by dplyr’s filter function).
The function lengths() identifies which features in nz_height intersect with any objects in y.
In this case, 1 is the greatest possible value, but for more complex operations one could use the method to subset only features that intersect with, for example, 2 or more features from the source object.
sparse = FALSE (meaning ‘return a dense matrix not a sparse one’) in operators such as st_intersects(). The command st_intersects(x = nz_height, y = canterbury, sparse = FALSE)[, 1], for example, would return an output identical to sel_logical.
Note: the solution involving sgbp objects is more generalizable though, as it works for many-to-many operations and has lower memory requirements.
The same result can be also achieved with the sf function st_filter() which was created to increase compatibility between sf objects and dplyr data manipulation code:
canterbury_height3 = nz_height |>
st_filter(y = canterbury, .predicate = st_intersects)At this point, there are three identical (in all but row names) versions of canterbury_height, one created using the [ operator, one created via an intermediary selection object, and another using sf’s convenience function st_filter().
The next section explores different types of spatial relation, also known as binary predicates, that can be used to identify whether two features are spatially related or not.
4.2.2 Topological relations
Topological relations describe the spatial relationships between objects.
“Binary topological relationships”, to give them their full name, are logical statements (in that the answer can only be TRUE or FALSE) about the spatial relationships between two objects defined by ordered sets of points (typically forming points, lines and polygons) in two or more dimensions (Egenhofer and Herring 1990).
That may sound rather abstract and, indeed, the definition and classification of topological relations is based on mathematical foundations first published in book form in 1966 (Spanier 1995), with the field of algebraic topology continuing beyond the year 2000 (Dieck 2008).
Despite their mathematical origins, topological relations can be understood intuitively with reference to visualizations of commonly used functions that test for common types of spatial relationships.
Figure 4.2 shows a variety of geometry pairs and their associated relations.
The third and fourth pairs in Figure 4.2 (from left to right and then down) demonstrate that, for some relations, order is important.
While the relations equals, intersects, crosses, touches and overlaps are symmetrical, meaning that if function(x, y) is true, function(y, x) will also be true, relations in which the order of the geometries are important such as contains and within are not.
Notice that each geometry pair has a “DE-9IM” string such as FF2F11212, described in the next section.
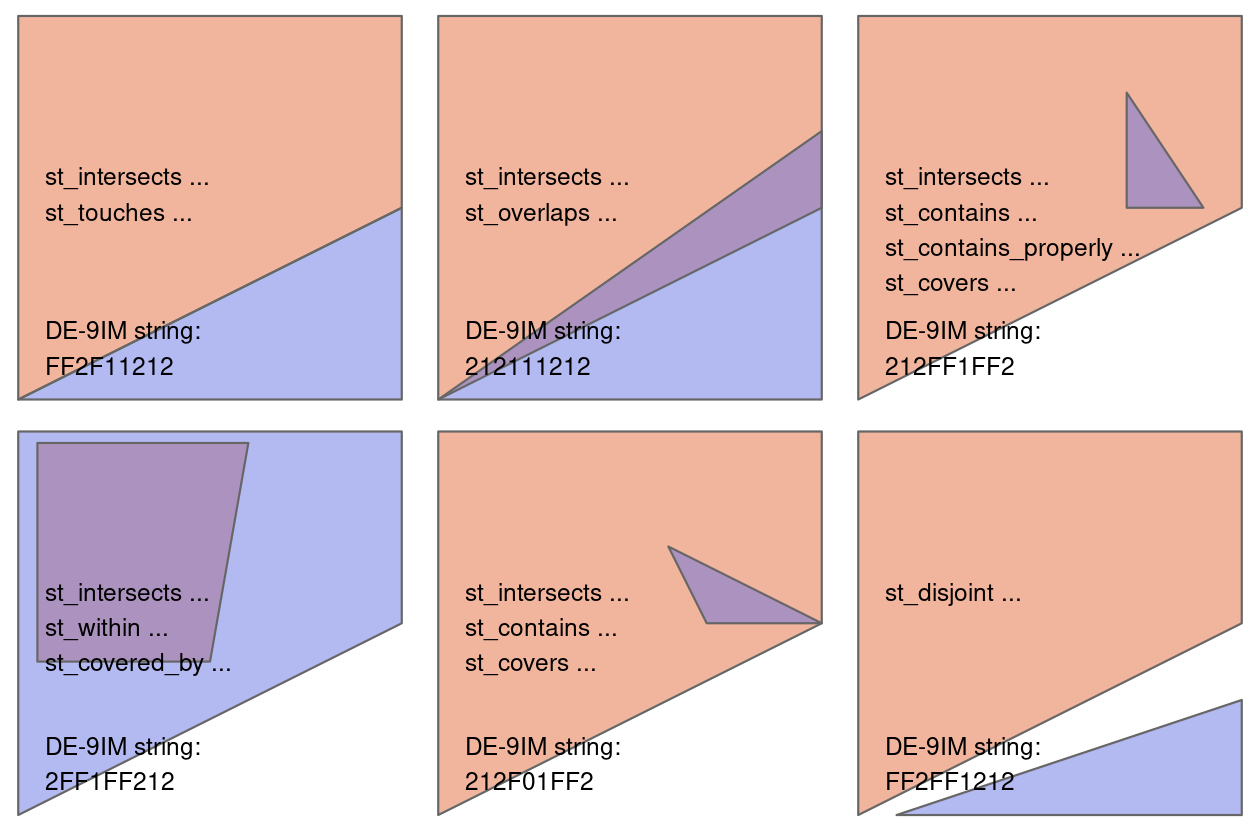
FIGURE 4.2: Topological relations between vector geometries, inspired by figures 1 and 2 in Egenhofer and Herring (1990). The relations for which the function(x, y) is true are printed for each geometry pair, with x represented in pink and y represented in blue. The nature of the spatial relationship for each pair is described by the Dimensionally Extended 9-Intersection Model string.
In sf, functions testing for different types of topological relations are called ‘binary predicates’, as described in the vignette Manipulating Simple Feature Geometries, which can be viewed with the command vignette("sf3"), and in the help page ?geos_binary_pred.
To see how topological relations work in practice, let’s create a simple reproducible example, building on the relations illustrated in Figure 4.2 and consolidating knowledge of how vector geometries are represented from a previous chapter (Section 2.2.4).
Note that to create tabular data representing coordinates (x and y) of the polygon vertices, we use the base R function cbind() to create a matrix representing coordinates points, a POLYGON, and finally an sfc object, as described in Chapter 2:
polygon_matrix = cbind(
x = c(0, 0, 1, 1, 0),
y = c(0, 1, 1, 0.5, 0)
)
polygon_sfc = st_sfc(st_polygon(list(polygon_matrix)))We will create additional geometries to demonstrate spatial relations with the following commands which, when plotted on top of the polygon created above, relate in space to one another, as shown in Figure 4.3.
Note the use of the function st_as_sf() and the argument coords to efficiently convert from a data frame containing columns representing coordinates to an sf object containing points:
point_df = data.frame(
x = c(0.2, 0.7, 0.4),
y = c(0.1, 0.2, 0.8)
)
point_sf = st_as_sf(point_df, coords = c("x", "y"))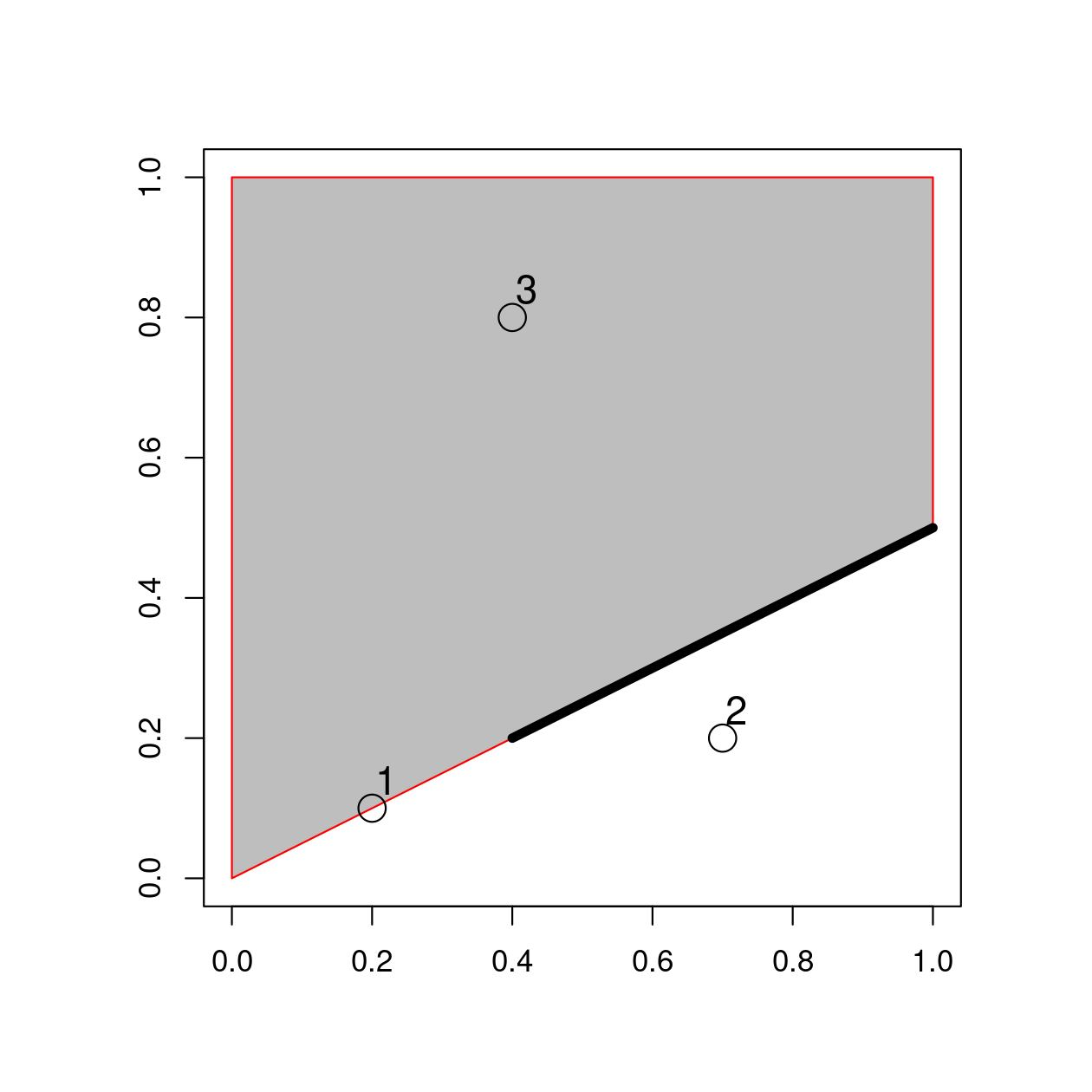
FIGURE 4.3: Points, line and polygon objects arranged to illustrate topological relations.
A simple query is: which of the points in point_sf intersect in some way with polygon polygon_sfc?
The question can be answered by inspection (points 1 and 3 are touching and within the polygon, respectively).
This question can be answered with the spatial predicate st_intersects() as follows:
st_intersects(point_sf, polygon_sfc)
#> Sparse geometry binary predicate... `intersects'
#> 1: 1
#> 2: (empty)
#> 3: 1The result should match your intuition:
positive (1) results are returned for the first and third point, and a negative result (represented by an empty vector) for the second are outside the polygon’s border.
What may be unexpected is that the result comes in the form of a list of vectors.
This sparse matrix output only registers a relation if one exists, reducing the memory requirements of topological operations on multi-feature objects.
As we saw in the previous section, a dense matrix consisting of TRUE or FALSE values is returned when sparse = FALSE.
st_intersects(point_sf, polygon_sfc, sparse = FALSE)
#> [,1]
#> [1,] TRUE
#> [2,] FALSE
#> [3,] TRUEIn the above output each row represents a feature in the target (argument x) object, and each column represents a feature in the selecting object (y).
In this case, there is only one feature in the y object polygon_sfc so the result, which can be used for subsetting as we saw in Section 4.2.1, has only one column.
st_intersects() returns TRUE even in cases where the features just touch: intersects is a ‘catch-all’ topological operation which identifies many types of spatial relation, as illustrated in Figure 4.2.
More restrictive questions include which points lie within the polygon, and which features are on or contain a shared boundary with y?
These can be answered as follows (results not shown):
st_within(point_sf, polygon_sfc)
st_touches(point_sf, polygon_sfc)Note that although the first point touches the boundary polygon, it is not within it; the third point is within the polygon but does not touch any part of its border.
The opposite of st_intersects() is st_disjoint(), which returns only objects that do not spatially relate in any way to the selecting object (note [, 1] converts the result into a vector).
st_disjoint(point_sf, polygon_sfc, sparse = FALSE)[, 1]
#> [1] FALSE TRUE FALSEThe function st_is_within_distance() detects features that almost touch the selection object, which has an additional dist argument.
It can be used to set how close target objects need to be before they are selected.
The ‘is within distance’ binary spatial predicate is demonstrated in the code chunk below, the results of which show that every point is within 0.2 units of the polygon.
st_is_within_distance(point_sf, polygon_sfc, dist = 0.2, sparse = FALSE)[, 1]
#> [1] TRUE TRUE TRUENote that although point 2 is more than 0.2 units of distance from the nearest vertex of polygon_sfc, it is still selected when the distance is set to 0.2.
This is because distance is measured to the nearest edge, in this case the part of the polygon that lies directly above point 2 in Figure 4.3.
(You can verify the actual distance between point 2 and the polygon is 0.13 with the command st_distance(point_sf, polygon_sfc).)
st_join function, mentioned in the next section, also uses the spatial indexing.
You can learn more at https://www.r-spatial.org/r/2017/06/22/spatial-index.html.
4.2.3 Distance relations
While the topological relations presented in the previous section are binary (a feature either intersects with another or does not) distance relations are continuous.
The distance between two sf objects is calculated with st_distance(), which is also used behind the scenes in Section 4.2.6 for distance-based joins.
This is illustrated in the code chunk below, which finds the distance between the highest point in New Zealand and the geographic centroid of the Canterbury region, created in Section 4.2.1:
nz_highest = nz_height |> slice_max(n = 1, order_by = elevation)
canterbury_centroid = st_centroid(canterbury)
st_distance(nz_highest, canterbury_centroid)
#> Units: [m]
#> [,1]
#> [1,] 115540There are two potentially surprising things about the result:
- It has
units, telling us the distance is 100,000 meters, not 100,000 inches, or any other measure of distance - It is returned as a matrix, even though the result only contains a single value
This second feature hints at another useful feature of st_distance(), its ability to return distance matrices between all combinations of features in objects x and y.
This is illustrated in the command below, which finds the distances between the first three features in nz_height and the Otago and Canterbury regions of New Zealand represented by the object co.
co = filter(nz, grepl("Canter|Otag", Name))
st_distance(nz_height[1:3, ], co)
#> Units: [m]
#> [,1] [,2]
#> [1,] 123537 15498
#> [2,] 94283 0
#> [3,] 93019 0Note that the distance between the second and third features in nz_height and the second feature in co is zero.
This demonstrates the fact that distances between points and polygons refer to the distance to any part of the polygon.
The second and third points in nz_height are in Otago, which can be verified by plotting them (result not shown):
plot(st_geometry(co)[2])
plot(st_geometry(nz_height)[2:3], add = TRUE)4.2.4 DE-9IM strings
Underlying the binary predicates demonstrated in the previous section is the Dimensionally Extended 9-Intersection Model (DE-9IM). As the cryptic name suggests, this is not an easy topic to understand, but it is worth knowing about because it underlies many spatial operations and enables the creation of custom spatial predicates. The model was originally labelled “DE + 9IM” by its inventors, referring to the “dimension of the intersections of boundaries, interiors, and exteriors of two features” (Clementini and Di Felice 1995), but it is now referred to as DE-9IM (Shen et al. 2018). DE-9IM is applicable to two-dimensional objects (points, lines and polygons) in Euclidean space, meaning that the model (and software implementing it such as GEOS) assumes you are working with data in a projected coordinate reference system, described in Chapter 7.
To demonstrate how DE-9IM strings work, let’s take a look at the various ways that the first geometry pair in Figure 4.2 relate.
Figure 4.4 illustrates the 9-intersection model (9IM) which shows the intersections between every combination of each object’s interior, boundary and exterior: when each component of the first object x is arranged as columns, and each component of y is arranged as rows, a facetted graphic is created with the intersections between each element highlighted.
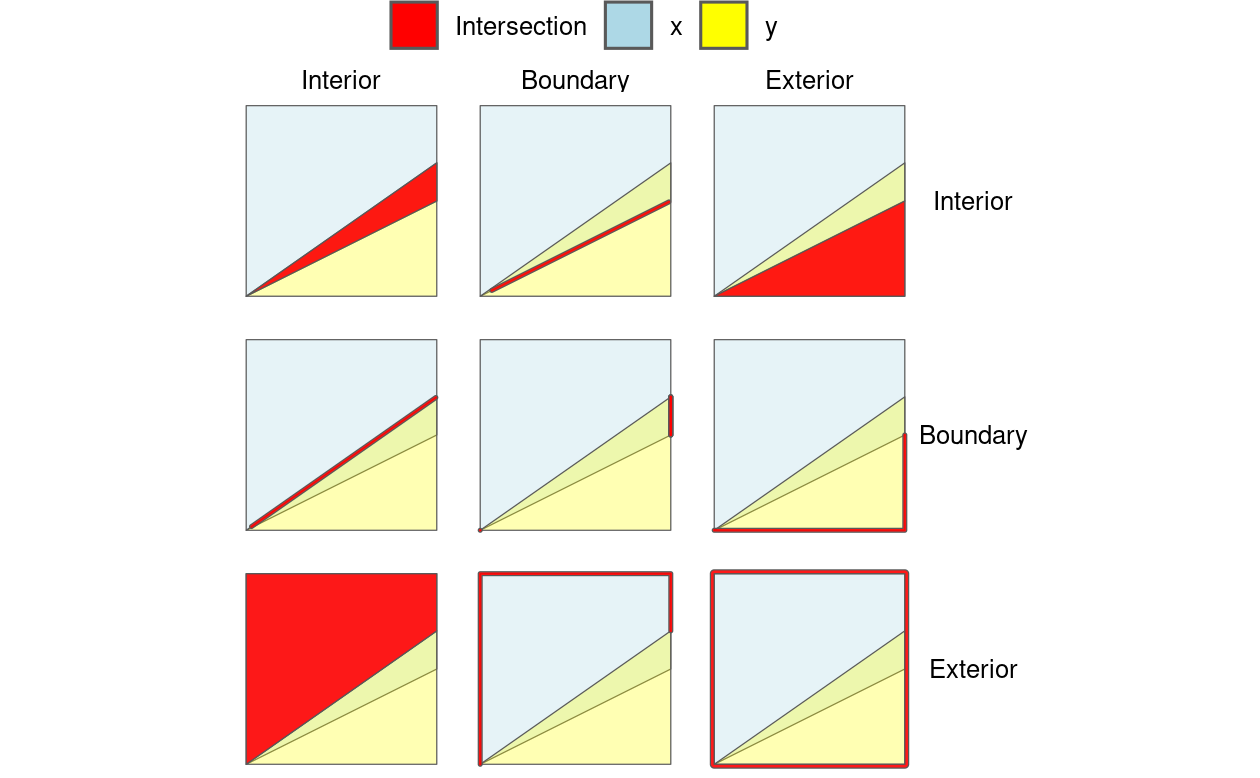
FIGURE 4.4: Illustration of how the Dimensionally Extended 9 Intersection Model (DE-9IM) works. Colors not in the legend represent the overlap between different components. The thick lines highlight two-dimensional intersections, e.g., between the boundary of object x and the interior of object y, shown in the middle top facet.
DE-9IM strings are derived from the dimension of each type of relation. In this case, the red intersections in Figure 4.4 have dimensions of 0 (points), 1 (lines), and 2 (polygons), as shown in Table 4.1.
| Interior (x) | Boundary (x) | Exterior (x) | |
|---|---|---|---|
| Interior (y) | 2 | 1 | 2 |
| Boundary (y) | 1 | 1 | 1 |
| Exterior (y) | 2 | 1 | 2 |
Flattening this matrix ‘row-wise’ (meaning concatenating the first row, then the second, then the third) results in the string 212111212.
Another example will serve to demonstrate the system:
the relation shown in Figure 4.2 (the third polygon pair in the third column and 1st row) can be defined in the DE-9IM system as follows:
- The intersections between the interior of the larger object
xand the interior, boundary and exterior ofyhave dimensions of 2, 1 and 2, respectively - The intersections between the boundary of the larger object
xand the interior, boundary and exterior ofyhave dimensions of F, F and 1, respectively, where ‘F’ means ‘false’, the objects are disjoint - The intersections between the exterior of
xand the interior, boundary and exterior ofyhave dimensions of F, F and 2, respectively: the exterior of the larger object does not touch the interior or boundary ofy, but the exterior of the smaller and larger objects cover the same area
These three components, when concatenated, create the string 212, FF1, and FF2.
This is the same as the result obtained from the function st_relate() (see the source code of this chapter to see how other geometries in Figure 4.2 were created):
xy2sfc = function(x, y) st_sfc(st_polygon(list(cbind(x, y))))
x = xy2sfc(x = c(0, 0, 1, 1, 0), y = c(0, 1, 1, 0.5, 0))
y = xy2sfc(x = c(0.7, 0.7, 0.9, 0.7), y = c(0.8, 0.5, 0.5, 0.8))
st_relate(x, y)
#> [,1]
#> [1,] "212FF1FF2"Understanding DE-9IM strings allows new binary spatial predicates to be developed.
The help page ?st_relate contains function definitions for ‘queen’ and ‘rook’ relations in which polygons share a border or only a point, respectively.
‘Queen’ relations mean that ‘boundary-boundary’ relations (the cell in the second column and the second row in Table 4.1, or the 5th element of the DE-9IM string) must not be empty, corresponding to the pattern F***T****, while for ‘rook’ relations, the same element must be 1 (meaning a linear intersection) (see Figure 4.5).
These are implemented as follows:
st_queen = function(x, y) st_relate(x, y, pattern = "F***T****")
st_rook = function(x, y) st_relate(x, y, pattern = "F***1****")Building on the object x created previously, we can use the newly created functions to find out which elements in the grid are a ‘queen’ and ‘rook’ in relation to the middle square of the grid as follows:
grid = st_make_grid(x, n = 3)
grid_sf = st_sf(grid)
grid_sf$queens = lengths(st_queen(grid, grid[5])) > 0
plot(grid, col = grid_sf$queens)
grid_sf$rooks = lengths(st_rook(grid, grid[5])) > 0
plot(grid, col = grid_sf$rooks)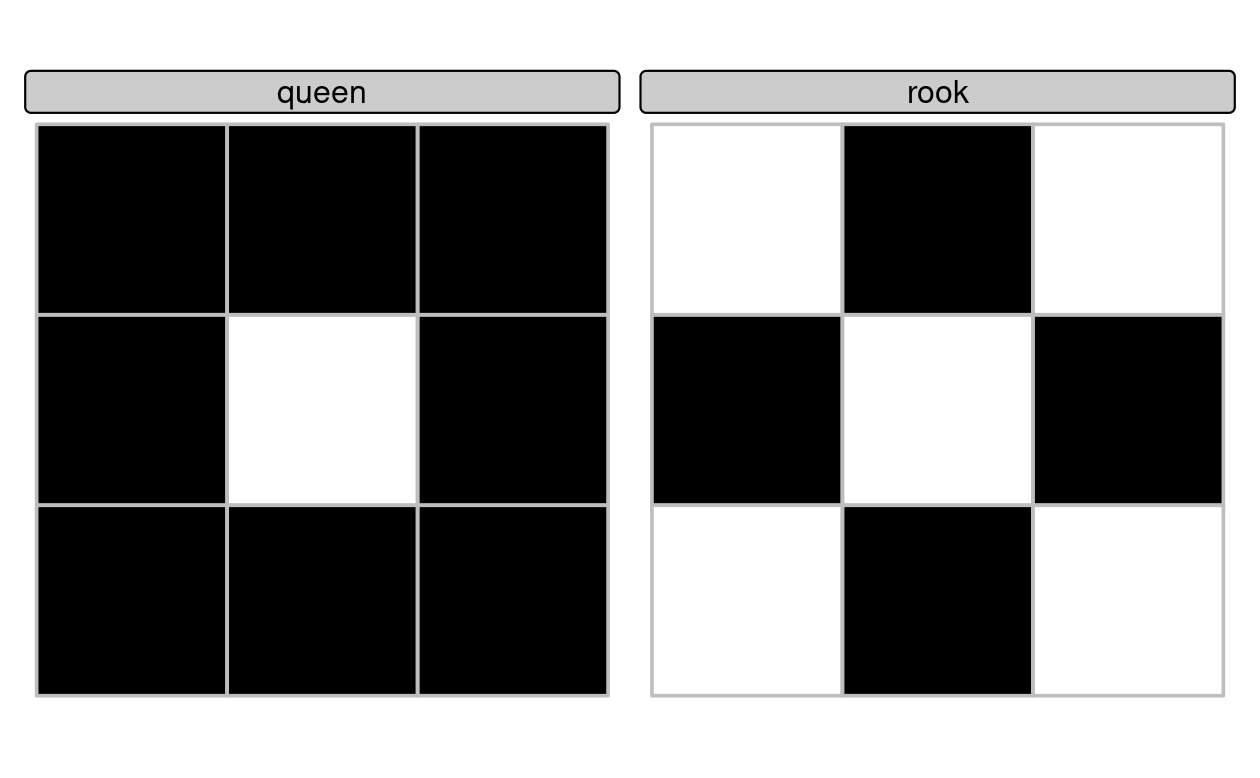
FIGURE 4.5: Demonstration of custom binary spatial predicates for finding queen (left) and rook (right) relations to the central square in a grid with 9 geometries.
4.2.5 Spatial joining
Joining two non-spatial datasets relies on a shared ‘key’ variable, as described in Section 3.2.4.
Spatial data joining applies the same concept, but instead relies on spatial relations, described in the previous section.
As with attribute data, joining adds new columns to the target object (the argument x in joining functions), from a source object (y).
The process is illustrated by the following example: imagine you have ten points randomly distributed across the Earth’s surface and you ask, for the points that are on land, which countries are they in? Implementing this idea in a reproducible example will build your geographic data-handling skills and will showhow spatial joins work. The starting point is to create points that are randomly scattered over the Earth’s surface.
set.seed(2018) # set seed for reproducibility
(bb = st_bbox(world)) # the world's bounds
#> xmin ymin xmax ymax
#> -180.0 -89.9 180.0 83.6
random_df = data.frame(
x = runif(n = 10, min = bb[1], max = bb[3]),
y = runif(n = 10, min = bb[2], max = bb[4])
)
random_points = random_df |>
st_as_sf(coords = c("x", "y"), crs = "EPSG:4326") # set coordinates and CRSThe scenario illustrated in Figure 4.6 shows that the random_points object (top left) lacks attribute data, while the world (top right) has attributes, including country names shown for a sample of countries in the legend.
Spatial joins are implemented with st_join(), as illustrated in the code chunk below.
The output is the random_joined object which is illustrated in Figure 4.6 (bottom left).
Before creating the joined dataset, we use spatial subsetting to create world_random, which contains only countries that contain random points, to verify that number of country names returned in the joined dataset should be four (Figure 4.6, top right panel).
world_random = world[random_points, ]
nrow(world_random)
#> [1] 4
random_joined = st_join(random_points, world["name_long"])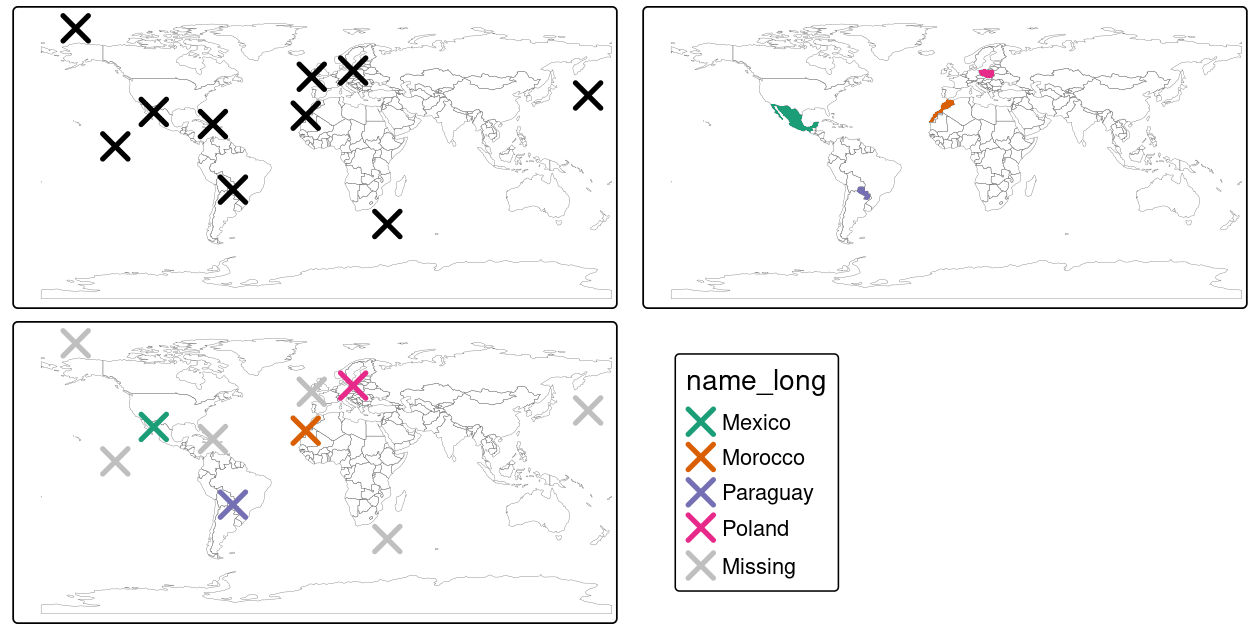
FIGURE 4.6: Illustration of a spatial join. A new attribute variable is added to random points (top left) from source world object (top right) resulting in the data represented in the final panel.
By default, st_join() performs a left join, meaning that the result is an object containing all rows from x including rows with no match in y (see Section 3.2.4), but it can also do inner joins by setting the argument left = FALSE.
Like spatial subsetting, the default topological operator used by st_join() is st_intersects(), which can be changed by setting the join argument (see ?st_join for details).
The example above demonstrates the addition of a column from a polygon layer to a point layer, but the approach works regardless of geometry types.
In such cases, for example when x contains polygons, each of which matches multiple objects in y, spatial joins will result in duplicate features by creating a new row for each match in y.
4.2.6 Distance-based joins
Sometimes two geographic datasets do not intersect but still have a strong geographic relationship due to their proximity.
The datasets cycle_hire and cycle_hire_osm, already attached in the spData package, provide a good example.
Plotting them shows that they are often closely related, but they do not touch, as shown in Figure 4.7, a base version of which is created with the following code below:
plot(st_geometry(cycle_hire), col = "blue")
plot(st_geometry(cycle_hire_osm), add = TRUE, pch = 3, col = "red")We can check if any points are the same using st_intersects() as shown below:
any(st_intersects(cycle_hire, cycle_hire_osm, sparse = FALSE))
#> [1] FALSEFIGURE 4.7: The spatial distribution of cycle hire points in London based on official data (blue) and OpenStreetMap data (red).
Imagine that we need to join the capacity variable in cycle_hire_osm onto the official ‘target’ data contained in cycle_hire.
This is when a non-overlapping join is needed.
The simplest method is to use the binary predicate st_is_within_distance(), as demonstrated below using a threshold distance of 20 m.
One can set the threshold distance in metric units also for unprojected data (e.g., lon/lat CRSs such as WGS84), if the spherical geometry engine (S2) is enabled, as it is in sf by default (see Section 2.2.9).
sel = st_is_within_distance(cycle_hire, cycle_hire_osm,
dist = units::set_units(20, "m"))
summary(lengths(sel) > 0)
#> Mode FALSE TRUE
#> logical 304 438This shows that there are 438 points in the target object cycle_hire within the threshold distance of cycle_hire_osm.
How to retrieve the values associated with the respective cycle_hire_osm points?
The solution is again with st_join(), but with an additional dist argument (set to 20 m below):
z = st_join(cycle_hire, cycle_hire_osm, st_is_within_distance,
dist = units::set_units(20, "m"))
nrow(cycle_hire)
#> [1] 742
nrow(z)
#> [1] 762Note that the number of rows in the joined result is greater than the target.
This is because some cycle hire stations in cycle_hire have multiple matches in cycle_hire_osm.
To aggregate the values for the overlapping points and return the mean, we can use the aggregation methods learned in Chapter 3, resulting in an object with the same number of rows as the target.
z = z |>
group_by(id) |>
summarize(capacity = mean(capacity))
nrow(z) == nrow(cycle_hire)
#> [1] TRUEThe capacity of nearby stations can be verified by comparing a plot of the capacity of the source cycle_hire_osm data with the results in this new object (plots not shown):
The result of this join has used a spatial operation to change the attribute data associated with simple features; the geometry associated with each feature has remained unchanged.
4.2.7 Spatial aggregation
As with attribute data aggregation, spatial data aggregation condenses data: aggregated outputs have fewer rows than non-aggregated inputs.
Statistical aggregating functions, such as mean average or sum, summarize multiple values of a variable, and return a single value per grouping variable.
Section 3.2.3 demonstrated how aggregate() and group_by() |> summarize() condense data based on attribute variables, this section shows how the same functions work with spatial objects.
Returning to the example of New Zealand, imagine you want to find out the average height of high points in each region: it is the geometry of the source (y or nz in this case) that defines how values in the target object (x or nz_height) are grouped.
This can be done in a single line of code with base R’s aggregate() method.
nz_agg = aggregate(x = nz_height, by = nz, FUN = mean)The result of the previous command is an sf object with the same geometry as the (spatial) aggregating object (nz), which you can verify with the command identical(st_geometry(nz), st_geometry(nz_agg)).
The result of the previous operation is illustrated in Figure 4.8, which shows the average value of features in nz_height within each of New Zealand’s 16 regions.
The same result can also be generated by piping the output from st_join() into the ‘tidy’ functions group_by() and summarize() as follows:
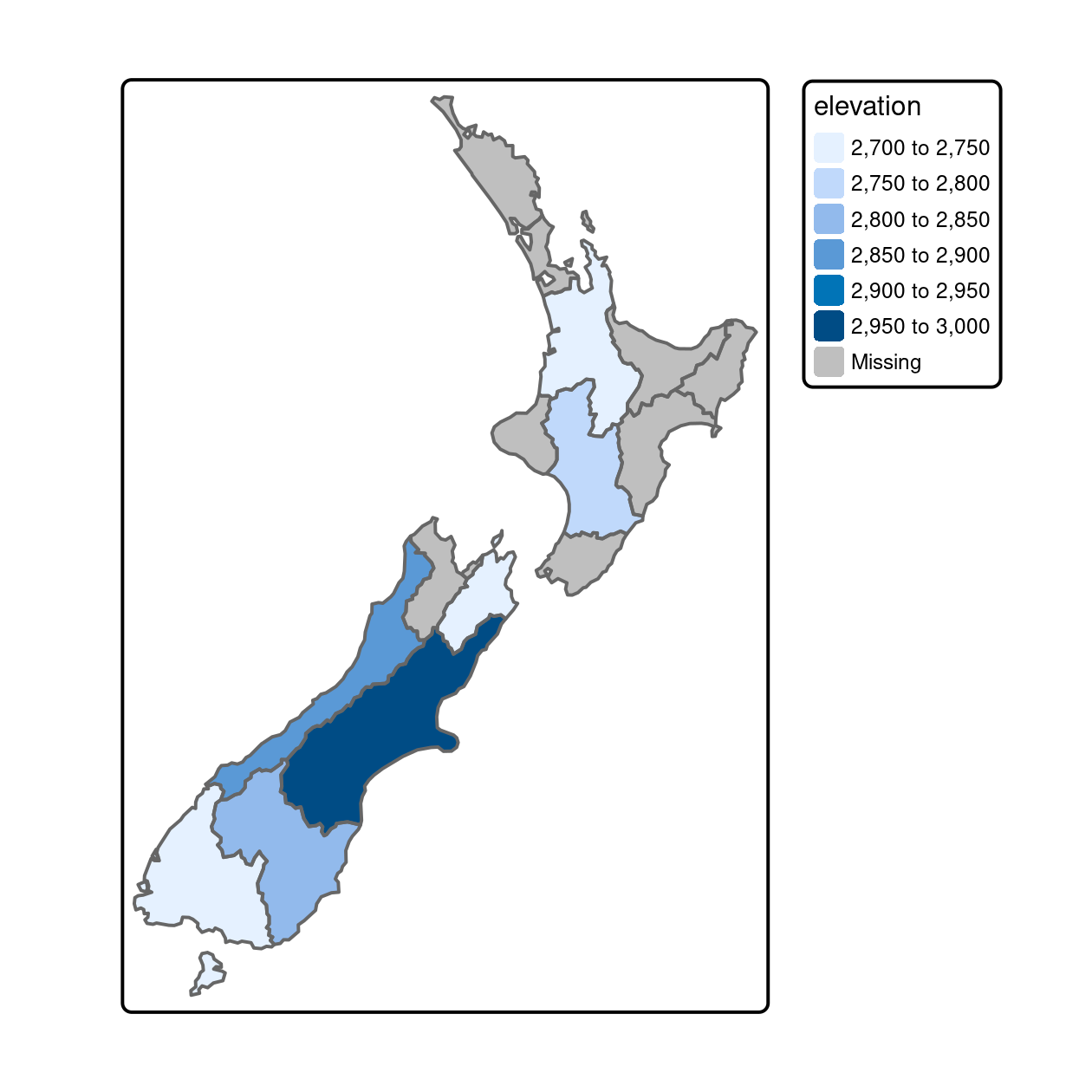
FIGURE 4.8: Average height of the top 101 high points across the regions of New Zealand.
nz_agg2 = st_join(x = nz, y = nz_height) |>
group_by(Name) |>
summarize(elevation = mean(elevation, na.rm = TRUE))The resulting nz_agg objects have the same geometry as the aggregating object nz but with a new column summarizing the values of x in each region using the function mean().
Other functions could be used instead of mean() here, including median(), sd() and other functions that return a single value per group.
Note: one difference between the aggregate() and group_by() |> summarize() approaches is that the former results in NA values for unmatching region names, while the latter preserves region names.
The ‘tidy’ approach is thus more flexible in terms of aggregating functions and the column names of the results.
Aggregating operations that also create new geometries are covered in Section 5.2.7.
4.2.8 Joining incongruent layers
Spatial congruence is an important concept related to spatial aggregation.
An aggregating object (which we will refer to as y) is congruent with the target object (x) if the two objects have shared borders.
Often this is the case for administrative boundary data, whereby larger units — such as Middle Layer Super Output Areas (MSOAs) in the UK or districts in many other European countries — are composed of many smaller units.
Incongruent aggregating objects, by contrast, do not share common borders with the target (Qiu et al. 2012). This is problematic for spatial aggregation (and other spatial operations) illustrated in Figure 4.9: aggregating the centroid of each sub-zone will not return accurate results. Areal interpolation overcomes this issue by transferring values from one set of areal units to another, using a range of algorithms including simple area weighted approaches and more sophisticated approaches such as ‘pycnophylactic’ methods (Tobler 1979).
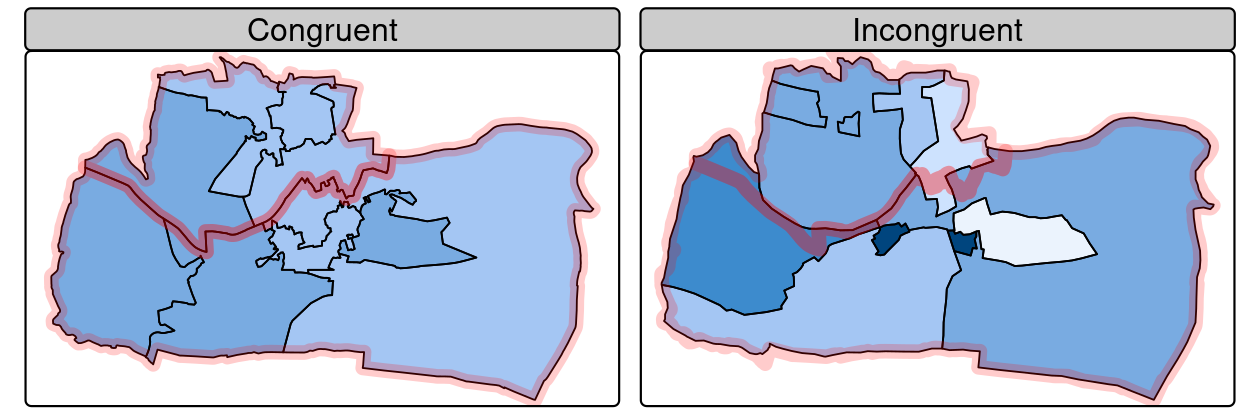
FIGURE 4.9: Congruent (left) and incongruent (right) areal units with respect to larger aggregating zones (translucent red borders).
The spData package contains a dataset named incongruent (colored polygons with black borders in the right panel of Figure 4.9) and a dataset named aggregating_zones (the two polygons with the translucent red border in the right panel of Figure 4.9).
Let us assume that the value column of incongruent refers to the total regional income in million Euros.
How can we transfer the values of the underlying nine spatial polygons into the two polygons of aggregating_zones?
The simplest useful method for this is area weighted spatial interpolation, which transfers values from the incongruent object to a new column in aggregating_zones in proportion with the area of overlap: the larger the spatial intersection between input and output features, the larger the corresponding value.
This is implemented in st_interpolate_aw(), as demonstrated in the code chunk below.
iv = incongruent["value"] # keep only the values to be transferred
agg_aw = st_interpolate_aw(iv, aggregating_zones, extensive = TRUE)
#> Warning in st_interpolate_aw.sf(iv, aggregating_zones, extensive = TRUE):
#> st_interpolate_aw assumes attributes are constant or uniform over areas of x
agg_aw$value
#> [1] 19.6 25.7In our case it is meaningful to sum up the values of the intersections falling into the aggregating zones since total income is a so-called spatially extensive variable (which increases with area), assuming income is evenly distributed across the smaller zones (hence the warning message above).
This would be different for spatially intensive variables such as average income or percentages, which do not increase as the area increases.
st_interpolate_aw() works equally with spatially intensive variables: set the extensive parameter to FALSE and it will use an average rather than a sum function when doing the aggregation.
4.3 Spatial operations on raster data
This section builds on Section 3.3, which highlights various basic methods for manipulating raster datasets, to demonstrate more advanced and explicitly spatial raster operations, and it uses the objects elev and grain manually created in Section 3.3.
For the reader’s convenience, these datasets can be also found in the spData package.
elev = rast(system.file("raster/elev.tif", package = "spData"))
grain = rast(system.file("raster/grain.tif", package = "spData"))4.3.1 Spatial subsetting
The previous chapter (Section 3.3) demonstrated how to retrieve values associated with specific cell IDs or row and column combinations.
Raster objects can also be extracted by location (coordinates) and other spatial objects.
To use coordinates for subsetting, one can ‘translate’ the coordinates into a cell ID with the terra function cellFromXY().
An alternative is to use terra::extract() (be careful, there is also a function called extract() in the tidyverse) to extract values.
Both methods are demonstrated below to find the value of the cell that covers a point located at coordinates of 0.1, 0.1.
id = cellFromXY(elev, xy = matrix(c(0.1, 0.1), ncol = 2))
elev[id]
# the same as
terra::extract(elev, matrix(c(0.1, 0.1), ncol = 2))Raster objects can also be subset with another raster object, as demonstrated in the code chunk below:
clip = rast(xmin = 0.9, xmax = 1.8, ymin = -0.45, ymax = 0.45,
resolution = 0.3, vals = rep(1, 9))
elev[clip]
# we can also use extract
# terra::extract(elev, ext(clip))This amounts to retrieving the values of the first raster object (in this case elev) that fall within the extent of a second raster (here: clip).
The example above returned the values of specific cells, but in many cases spatial outputs from subsetting operations on raster datasets are needed.
This can be done by setting the drop argument of the [ operator to FALSE.
The code below returns the first two cells of elev, i.e., the first two cells of the top row, as a raster object (only the first 2 lines of the output is shown):
elev[1:2, drop = FALSE] # spatial subsetting with cell IDs
#> class : SpatRaster
#> dimensions : 1, 2, 1 (nrow, ncol, nlyr)
#> ...Another common use case of spatial subsetting is when a raster with logical (or NA) values is used to mask another raster with the same extent and resolution, as illustrated in Figure 4.10.
In this case, the [ and mask() functions can be used (results not shown).
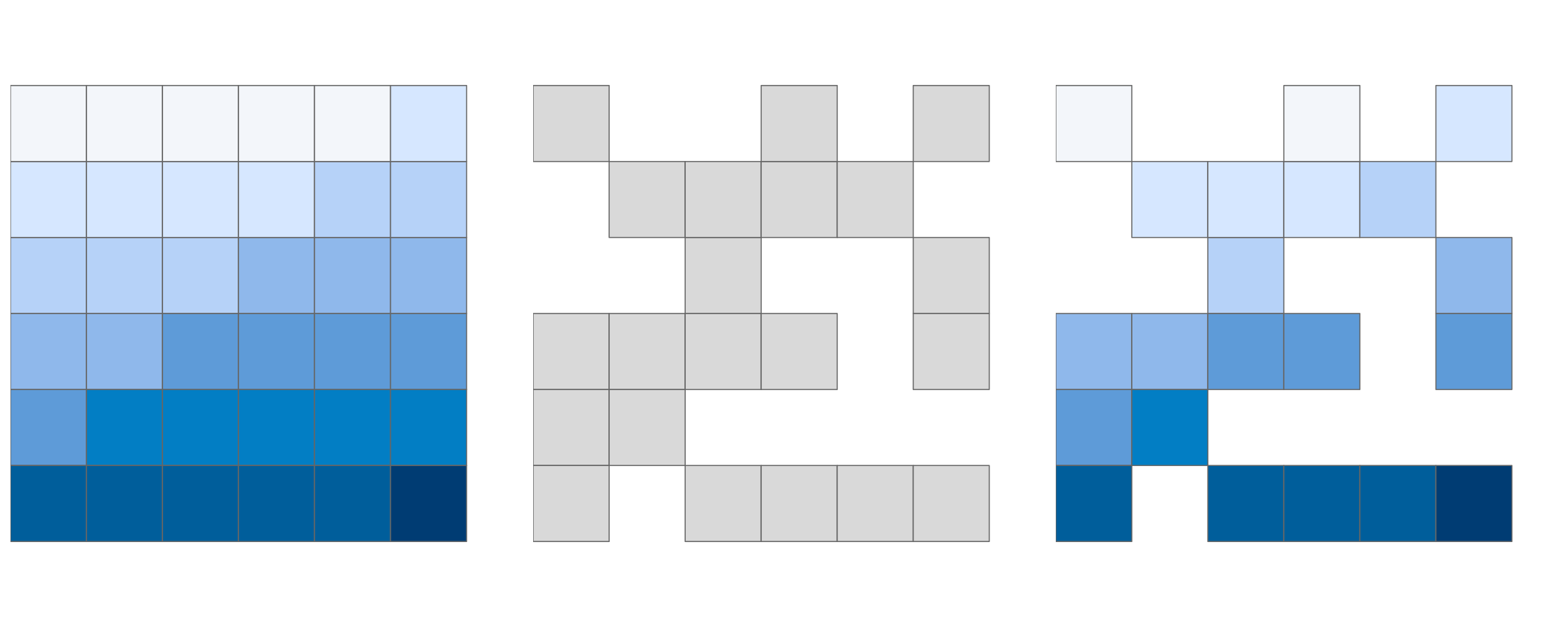
FIGURE 4.10: Original raster (left), raster mask (middle), and output of masking a raster (right).
In the code chunk above, we have created a mask object called rmask with values randomly assigned to NA and TRUE.
Next, we want to keep those values of elev which are TRUE in rmask.
In other words, we want to mask elev with rmask.
# spatial subsetting
elev[rmask, drop = FALSE] # with [ operator
# we can also use mask
# mask(elev, rmask)The above approach can be also used to replace some values (e.g., expected to be wrong) with NA.
elev[elev < 20] = NAThese operations are in fact Boolean local operations since we compare cell-wise two rasters. The next subsection explores these and related operations in more detail.
4.3.2 Map algebra
The term ‘map algebra’ was coined in the late 1970s to describe a “set of conventions, capabilities, and techniques” for the analysis of geographic raster and (although less prominently) vector data (Tomlin 1994). In this context, we define map algebra more narrowly, as operations that modify or summarize raster cell values, with reference to surrounding cells, zones, or statistical functions that apply to every cell.
Map algebra operations tend to be fast, because raster datasets only implicitly store coordinates, hence the old adage “raster is faster but vector is corrector”. The location of cells in raster datasets can be calculated by using its matrix position and the resolution and origin of the dataset (stored in the header). For the processing, however, the geographic position of a cell is barely relevant as long as we make sure that the cell position is still the same after the processing. Additionally, if two or more raster datasets share the same extent, projection and resolution, one could treat them as matrices for the processing.
This is the way that map algebra works with the terra package. First, the headers of the raster datasets are queried and (in cases where map algebra operations work on more than one dataset) checked to ensure the datasets are compatible. Second, map algebra retains the so-called one-to-one locational correspondence, meaning that cells cannot move. This differs from matrix algebra, in which values change position, for example when multiplying or dividing matrices.
Map algebra (or cartographic modeling with raster data) divides raster operations into four sub-classes (Tomlin 1990), with each working on one or several grids simultaneously:
- Local or per-cell operations
- Focal or neighborhood operations. Most often the output cell value is the result of a 3 x 3 input cell block
- Zonal operations are similar to focal operations, but the surrounding pixel grid on which new values are computed can have irregular sizes and shapes
- Global or per-raster operations. That means the output cell derives its value potentially from one or several entire rasters
This typology classifies map algebra operations by the number of cells used for each pixel processing step and the type of the output. For the sake of completeness, we should mention that raster operations can also be classified by discipline such as terrain, hydrological analysis, or image classification. The following sections explain how each type of map algebra operations can be used, with reference to worked examples.
4.3.3 Local operations
Local operations comprise all cell-by-cell operations in one or several layers. This includes adding or subtracting values from a raster, squaring and multiplying rasters. Raster algebra also allows logical operations such as finding all raster cells that are greater than a specific value (5 in our example below). The terra package supports all these operations and more, as demonstrated below (Figure 4.11):
elev + elev
elev^2
log(elev)
elev > 5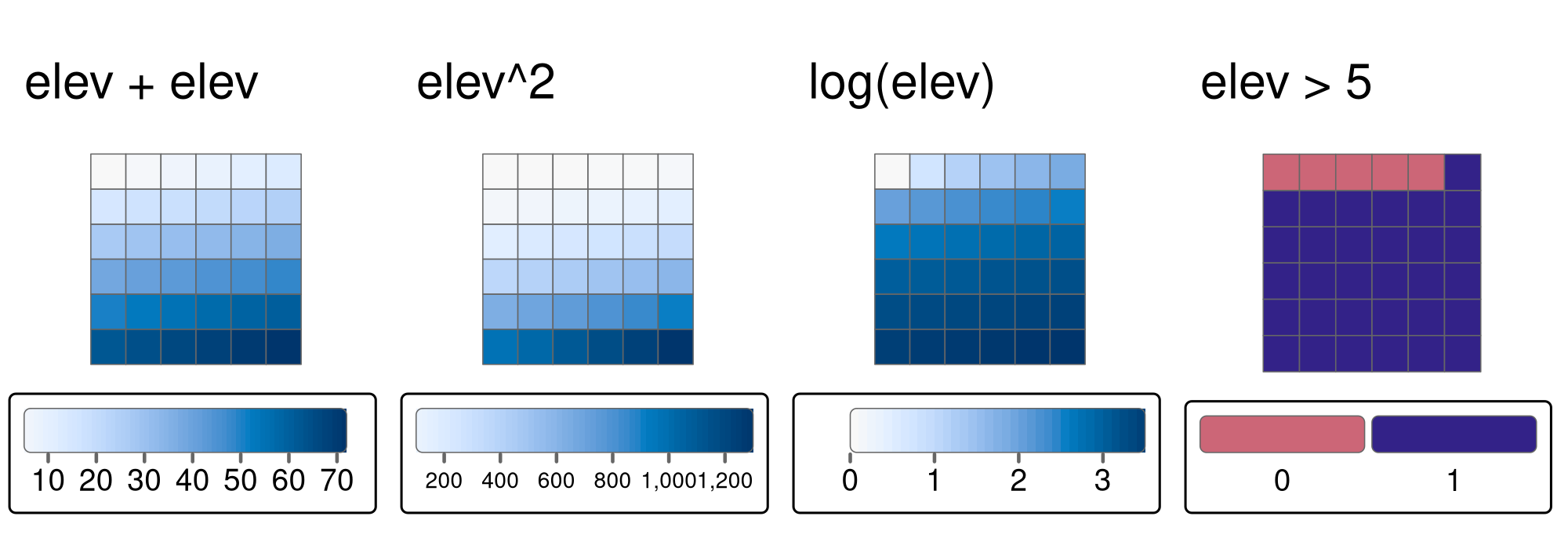
FIGURE 4.11: Examples of different local operations of the elev raster object: adding two rasters, squaring, applying logarithmic transformation, and performing a logical operation.
Another good example of local operations is the classification of intervals of numeric values into groups such as grouping a digital elevation model into low (class 1), middle (class 2) and high elevations (class 3).
Using the classify() command, we need first to construct a reclassification matrix, where the first column corresponds to the lower and the second column to the upper end of the class.
The third column represents the new value for the specified ranges in columns one and two.
rcl = matrix(c(0, 12, 1, 12, 24, 2, 24, 36, 3), ncol = 3, byrow = TRUE)
rcl
#> [,1] [,2] [,3]
#> [1,] 0 12 1
#> [2,] 12 24 2
#> [3,] 24 36 3Here, we assign the raster values in the ranges 0–12, 12–24 and 24–36 are reclassified to take values 1, 2 and 3, respectively.
recl = classify(elev, rcl = rcl)The classify() function can be also used when we want to reduce the number of classes in our categorical rasters.
We will perform several additional reclassifications in Chapter 14.
Apart from applying arithmetic operators directly, one can also use the app(), tapp() and lapp() functions.
They are more efficient, hence, they are preferable in the presence of large raster datasets.
Additionally, they allow you to save an output file directly.
The app() function applies a function to each cell of a raster and is used to summarize (e.g., calculating the sum) the values of multiple layers into one layer.
tapp() is an extension of app(), allowing us to select a subset of layers (see the index argument) for which we want to perform a certain operation.
Finally, the lapp() function allows us to apply a function to each cell using layers as arguments – an application of lapp() is presented below.
The calculation of the normalized difference vegetation index (NDVI) is a well-known local (pixel-by-pixel) raster operation. It returns a raster with values between -1 and 1; positive values indicate the presence of living plants (mostly > 0.2). NDVI is calculated from red and near-infrared (NIR) bands of remotely sensed imagery, typically from satellite systems such as Landsat or Sentinel. Vegetation absorbs light heavily in the visible light spectrum, and especially in the red channel, while reflecting NIR light. Here’s the NDVI formula:
\[ \begin{split} NDVI&= \frac{\text{NIR} - \text{Red}}{\text{NIR} + \text{Red}}\\ \end{split} \]
Let’s calculate NDVI for the multi-spectral satellite file of Zion National Park.
multi_raster_file = system.file("raster/landsat.tif", package = "spDataLarge")
multi_rast = rast(multi_raster_file)Our raster object has four satellite bands from the Landsat 8 satellite: blue, green, red, and NIR. Importantly, Landsat level-2 products are stored as integers to save disk space, and thus we need to convert them to floating-point numbers before doing any calculations. For that purpose, we need to apply a scaling factor (0.0000275) and add an offset (-0.2) to the original values.21
multi_rast = (multi_rast * 0.0000275) - 0.2The proper values now should be in a range between 0 and 1. This is not the case here, probably due to the presence of clouds and other atmospheric effects, which are stored as negative values. We will replace these negative values with 0 as follows.
multi_rast[multi_rast < 0] = 0The next step should be to implement the NDVI formula into an R function:
ndvi_fun = function(nir, red){
(nir - red) / (nir + red)
}This function accepts two numerical arguments, nir and red, and returns a numerical vector with NDVI values.
It can be used as the fun argument of lapp().
We just need to remember that our function expects two bands (not four from the original raster), and they need to be in the NIR, red order.
That is why we subset the input raster with multi_rast[[c(4, 3)]] before doing any calculations.
The result, shown on the right panel in Figure 4.12, can be compared to the RGB image of the same area (left panel of the same figure). It allows us to see that the largest NDVI values are connected to northern areas of dense forest, while the lowest values are related to the lake in the north and snowy mountain ridges.

FIGURE 4.12: RGB image (left) and NDVI values (right) calculated for the example satellite file of Zion National Park
Predictive mapping is another interesting application of local raster operations.
The response variable corresponds to measured or observed points in space, for example, species richness, the presence of landslides, tree disease or crop yield.
Consequently, we can easily retrieve space- or airborne predictor variables from various rasters (elevation, pH, precipitation, temperature, land cover, soil class, etc.).
Subsequently, we model our response as a function of our predictors using lm(), glm(), gam() or a machine-learning technique.
Spatial predictions on raster objects can therefore be made by applying estimated coefficients to the predictor raster values, and summing the output raster values (see Chapter 15).
4.3.4 Focal operations
While local functions operate on one cell, though possibly from multiple layers, focal operations take into account a central (focal) cell and its neighbors. The neighborhood (also named kernel, filter or moving window) under consideration is typically of size 3-by-3 cells (that is the central cell and its eight surrounding neighbors), but it can take on any other size or (not necessarily rectangular) shape as defined by the user. A focal operation applies an aggregation function to all cells within the specified neighborhood, uses the corresponding output as the new value for the central cell, and moves on to the next central cell (Figure 4.13). Other names for this operation are spatial filtering and convolution (Burrough et al. 2015).
In R, we can use the focal() function to perform spatial filtering.
We define the shape of the moving window with a matrix whose values correspond to weights (see w parameter in the code chunk below).
Secondly, the fun parameter lets us specify the function we wish to apply to this neighborhood.
Here, we choose the minimum, but any other summary function, including sum(), mean(), or var() can be used.
The min() function has an additional argument to determine whether to remove NAs in the process (na.rm = TRUE) or not (na.rm = FALSE, the default).
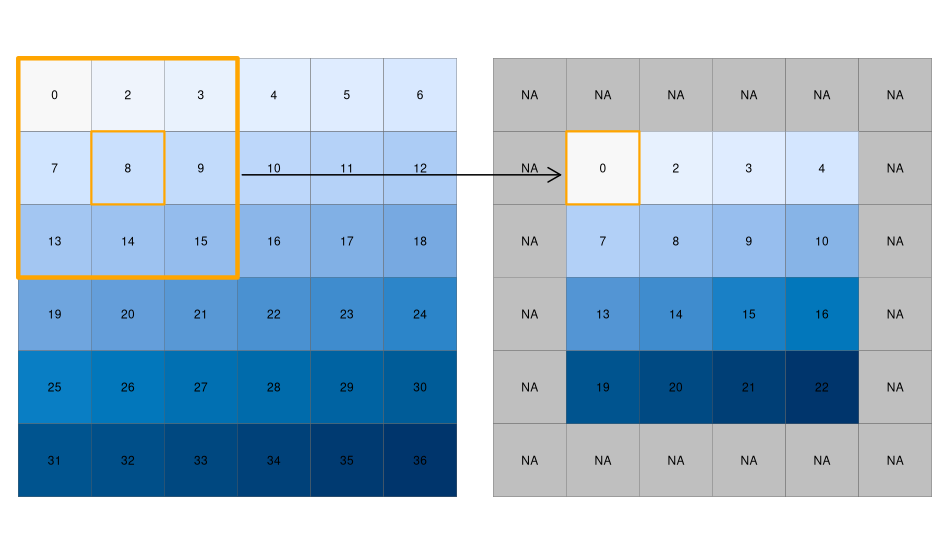
FIGURE 4.13: Input raster (left) and resulting output raster (right) due to a focal operation, finding the minimum value in 3-by-3 moving windows.
We can quickly check if the output meets our expectations. In our example, the minimum value has to be always the upper left corner of the moving window (remember, we have created the input raster by row-wise incrementing the cell values by one starting at the upper left corner). In this example, the weighting matrix consists only of 1s, meaning each cell has the same weight on the output, but this can be changed.
Focal functions or filters play a dominant role in image processing.
Low-pass or smoothing filters use the mean function to remove extremes.
In the case of categorical data, we can replace the mean with the mode, which is the most common value.
By contrast, high-pass filters accentuate features.
The line detection Laplace and Sobel filters might serve as an example here.
Check the focal() help page for how to use them in R (this will also be used in the exercises at the end of this chapter).
Terrain processing, the calculation of topographic characteristics such as slope, aspect and flow directions, relies on focal functions.
terrain() can be used to calculate these metrics, although some terrain algorithms, including the Zevenbergen and Thorne method to compute slope, are not implemented in this terra function.
Many other algorithms — including curvatures, contributing areas and wetness indices — are implemented in open source desktop geographic information system (GIS) software.
Chapter 10 shows how to access such GIS functionality from within R.
4.3.5 Zonal operations
Just like focal operations, zonal operations apply an aggregation function to multiple raster cells. However, a second raster, usually with categorical values, defines the zonal filters (or ‘zones’) in the case of zonal operations, as opposed to a neighborhood window in the case of focal operations presented in the previous section. Consequently, raster cells defining the zonal filter do not necessarily have to be neighbors. Our grain-size raster is a good example, as illustrated in the right panel of Figure 3.2: different grain sizes are spread irregularly throughout the raster. Finally, the result of a zonal operation is a summary table grouped by zone which is why this operation is also known as zonal statistics in the GIS world. This is in contrast to focal operations which return a raster object by default.
The following code chunk uses the zonal() function to calculate the mean elevation associated with each grain-size class.
z = zonal(elev, grain, fun = "mean")
z
#> grain elev
#> 1 clay 14.8
#> 2 silt 21.2
#> 3 sand 18.7This returns the statistics for each category, here the mean altitude for each grain-size class.
Note that it is also possible to get a raster with calculated statistics for each zone by setting the as.raster argument to TRUE.
4.3.6 Global operations and distances
Global operations are a special case of zonal operations with the entire raster dataset representing a single zone. The most common global operations are descriptive statistics for the entire raster dataset such as the minimum or maximum – we already discussed those in Section 3.3.2.
Aside from that, global operations are also useful for the computation of distance and weight rasters.
In the first case, one can calculate the distance from each cell to a specific target cell.
For example, one might want to compute the distance to the nearest coast (see also terra::distance()).
We might also want to consider topography, for example to avoid the crossing mountain ranges on the way to the coast.
This can be done by weighting distance by elevation so that each additional altitudinal meter ‘prolongs’ the Euclidean distance (in Exercises E8 and E9 at the end of this chapter you will do exactly that).
Visibility and viewshed computations also belong to the family of global operations (in the Exercises of Chapter 10, you will compute a viewshed raster).
4.3.7 Map algebra counterparts in vector processing
Many map algebra operations have a counterpart in vector processing (Liu and Mason 2009).
Computing a distance raster (global operation) while only considering a maximum distance (logical focal operation) is the equivalent to a vector buffer operation (Section 5.2.5).
Reclassifying raster data (either local or zonal function depending on the input) is equivalent to dissolving vector data (Section 4.2.5).
Overlaying two rasters (local operation), where one contains NULL or NA values representing a mask, is similar to vector clipping (Section 5.2.5).
Quite similar to spatial clipping is intersecting two layers (Section 4.2.1).
The difference is that these two layers (vector or raster) simply share an overlapping area (see Figure 5.8 for an example).
However, be careful with the wording.
Sometimes the same words have slightly different meanings for raster and vector data models.
While aggregating polygon geometries means dissolving boundaries, for raster data geometries it means increasing cell sizes and thereby reducing spatial resolution.
Zonal operations dissolve the cells of one raster in accordance with the zones (categories) of another raster dataset using an aggregating function.
4.3.8 Merging rasters
Suppose we would like to compute the NDVI (see Section 4.3.3), and additionally we want to compute terrain attributes from elevation data for observations within a study area.
Such computations rely on remotely sensed information.
The corresponding imagery is often divided into scenes covering a specific spatial extent, and frequently, a study area covers more than one scene.
Then, we would need to merge the scenes covered by our study area.
In the easiest case, we can just merge these scenes, that is put them side by side.
This is possible, for example, with digital elevation data.
In the following code chunk, we first download the Shuttle Radar Topography Mission (SRTM) elevation data for Austria and Switzerland (for the country codes, see the geodata function country_codes()).
In a second step, we merge the two rasters into one.
aut = geodata::elevation_30s(country = "AUT", path = tempdir())
ch = geodata::elevation_30s(country = "CHE", path = tempdir())
aut_ch = merge(aut, ch)terra’s merge() command combines two images, and in case they overlap, it uses the value of the first raster.
The merging approach is of little use when the overlapping values do not correspond to each other.
This is frequently the case when you want to combine spectral imagery from scenes that were taken on different dates.
The merge() command will still work, but you will see a clear border in the resulting image.
On the other hand, the mosaic() command lets you define a function for the overlapping area.
For instance, we could compute the mean value — this might smooth the clear border in the merged result, but it will most likely not make it disappear.
For a more detailed introduction to remote sensing with R, see Wegmann et al. (2016).
4.4 Exercises
E1. It was established in Section 4.2 that Canterbury was the region of New Zealand containing most of the 101 highest points in the country. How many of these high points does the Canterbury region contain?
Bonus: plot the result using the plot() function to show all of New Zealand, canterbury region highlighted in yellow, high points in Canterbury represented by red crosses (hint: pch = 7) and high points in other parts of New Zealand represented by blue circles. See the help page ?points for details with an illustration of different pch values.
E2. Which region has the second highest number of nz_height points, and how many does it have?
E3. Generalizing the question to all regions: how many of New Zealand’s 16 regions contain points which belong to the top 101 highest points in the country? Which regions?
- Bonus: create a table listing these regions in order of the number of points and their name.
E4. Test your knowledge of spatial predicates by finding out and plotting how US states relate to each other and other spatial objects.
The starting point of this exercise is to create an object representing Colorado state in the USA. Do this with the command
colorado = us_states[us_states$NAME == "Colorado",] (base R) or with the filter() function (tidyverse) and plot the resulting object in the context of US states.
- Create a new object representing all the states that geographically intersect with Colorado and plot the result (hint: the most concise way to do this is with the subsetting method
[). - Create another object representing all the objects that touch (have a shared boundary with) Colorado and plot the result (hint: remember you can use the argument
op = st_intersectsand other spatial relations during spatial subsetting operations in base R). - Bonus: create a straight line from the centroid of the District of Columbia near the East coast to the centroid of California near the West coast of the USA (hint: functions
st_centroid(),st_union()andst_cast()described in Chapter 5 may help) and identify which states this long East-West line crosses.
E5. Use dem = rast(system.file("raster/dem.tif", package = "spDataLarge")), and reclassify the elevation in three classes: low (<300), medium and high (>500).
Secondly, read the NDVI raster (ndvi = rast(system.file("raster/ndvi.tif", package = "spDataLarge"))) and compute the mean NDVI and the mean elevation for each altitudinal class.
E6. Apply a line detection filter to rast(system.file("ex/logo.tif", package = "terra")).
Plot the result.
Hint: Read ?terra::focal().
E7. Calculate the Normalized Difference Water Index (NDWI; (green - nir)/(green + nir)) of a Landsat image.
Use the Landsat image provided by the spDataLarge package (system.file("raster/landsat.tif", package = "spDataLarge")).
Also, calculate a correlation between NDVI and NDWI for this area (hint: you can use the layerCor() function).
E8. A StackOverflow post (stackoverflow.com/questions/35555709) shows how to compute distances to the nearest coastline using raster::distance().
Try to do something similar but with terra::distance(): retrieve a digital elevation model of Spain, and compute a raster which represents distances to the coast across the country (hint: use geodata::elevation_30s()).
Convert the resulting distances from meters to kilometers.
Note: it may be wise to increase the cell size of the input raster to reduce compute time during this operation (aggregate()).
E9. Try to modify the approach used in the above exercise by weighting the distance raster with the elevation raster; every 100 altitudinal meters should increase the distance to the coast by 10 km. Next, compute and visualize the difference between the raster created using the Euclidean distance (E8) and the raster weighted by elevation.