5 Geometry operations
5.1 Introduction
So far the book has explained the structure of geographic datasets (Chapter 2), and how to manipulate them based on their non-geographic attributes (Chapter 3) and spatial relations (Chapter 4).
This chapter focuses on manipulating the geographic elements of spatial objects, for example by creating buffers, simplifying and converting vector geometries, and aggregating and resampling raster data.
After reading it — and attempting the Exercises at the end — you should understand and have control over the geometry column in sf objects and the extent and geographic location of pixels represented in rasters in relation to other geographic objects.
Section 5.2 covers transforming vector geometries with ‘unary’ and ‘binary’ operations. Unary operations work on a single geometry in isolation, including simplification (of lines and polygons), the creation of buffers and centroids, and shifting/scaling/rotating single geometries using ‘affine transformations’ (Sections 5.2.1 to 5.2.4). Binary transformations modify one geometry based on the shape of another, including clipping and geometry unions, covered in Sections 5.2.5 to 5.2.7. Type transformations (from a polygon to a line, for example) are demonstrated in Section 5.2.8.
Section 5.3 covers geometric transformations on raster objects. This involves changing the size and number of the underlying pixels, and assigning them new values. It teaches how to change the resolution (also called raster aggregation and disaggregation), the extent and the origin of a raster. These operations are especially useful if one would like to align raster datasets from diverse sources. Aligned raster objects share a one-to-one correspondence between pixels, allowing them to be processed using map algebra operations, described in Section 4.3.2.
The interaction between raster and vector objects is covered in Chapter 6. It presents how raster values can be ‘masked’ and ‘extracted’ by vector geometries. Importantly it also shows how to ‘polygonize’ rasters and ‘rasterize’ vector datasets, making the two data models more interchangeable.
5.2 Geometric operations on vector data
This section is about operations that in some way change the geometry of vector (sf) objects.
It is more advanced than the spatial data operations presented in the previous chapter (Section 4.2), because here we drill down into the geometry:
the functions discussed in this section work on objects of class sfc in addition to objects of class sf.
5.2.1 Simplification
Simplification is a process for generalization of vector objects (lines and polygons) usually for use in smaller scale maps.
Another reason for simplifying objects is to reduce the amount of memory, disk space and network bandwidth they consume:
it may be wise to simplify complex geometries before publishing them as interactive maps.
The sf package provides st_simplify(), which uses the Douglas-Peucker algorithm to reduce the vertex count.
st_simplify() uses the dTolerance to control the level of generalization in map units (see Douglas and Peucker 1973 for details).
Figure 5.1 illustrates simplification of a LINESTRING geometry representing the River Seine and tributaries.
The simplified geometry was created by the following command:
seine_simp = st_simplify(seine, dTolerance = 2000) # 2000 m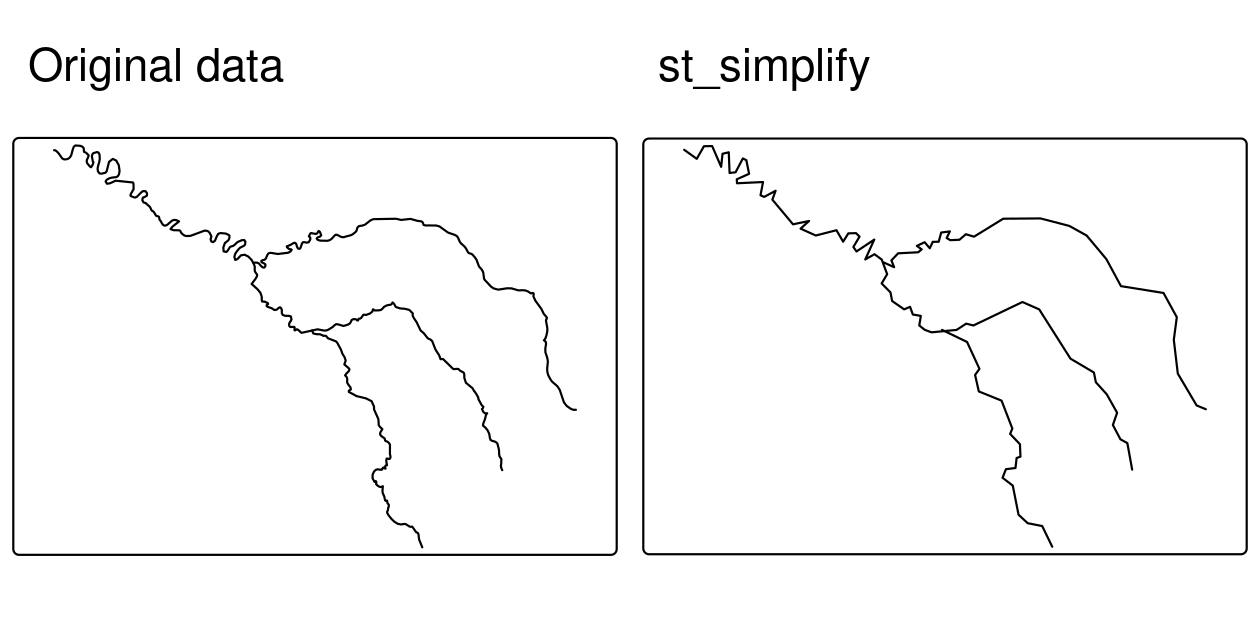
FIGURE 5.1: Comparison of the original and simplified geometry of the seine object.
The resulting seine_simp object is a copy of the original seine but with fewer vertices.
This is apparent, with the result being visually simpler (Figure 5.1, right) and consuming less memory than the original object, as verified below:
object.size(seine)
#> 18096 bytes
object.size(seine_simp)
#> 9112 bytes
Simplification is also applicable for polygons.
This is illustrated using us_states, representing the contiguous United States.
us_states_simp1 = st_simplify(us_states, dTolerance = 100000) # 100 kmA limitation with st_simplify() is that it simplifies objects on a per-geometry basis.
This means the ‘topology’ is lost, resulting in overlapping and ‘holey’ areal units illustrated in Figure 5.2 (right top panel).
ms_simplify() from rmapshaper provides an alternative.
By default it uses the Visvalingam algorithm, which overcomes some limitations of the Douglas-Peucker algorithm (Visvalingam and Whyatt 1993).
The following code chunk uses this function to simplify us_states.
The result has only 1% of the vertices of the input (set using the argument keep), but its number of objects remains intact because we set keep_shapes = TRUE:22
# proportion of points to retain (0-1; default 0.05)
us_states_simp2 = rmapshaper::ms_simplify(us_states, keep = 0.01,
keep_shapes = TRUE)
An alternative process to simplification is smoothing the boundaries of polygon and linestring geometries, which is implemented in the smoothr package.
Smoothing interpolates the edges of geometries and does not necessarily lead to fewer vertices, but can be especially useful when working with geometries that arise from spatially vectorizing a raster (a topic covered in Chapter 6).
smoothr implements three techniques for smoothing: a Gaussian kernel regression, Chaikin’s corner cutting algorithm, and spline interpolation, which are all described in the package vignette and website.
Note that similar to st_simplify(), the smoothing algorithms don’t preserve ‘topology’.
The workhorse function of smoothr is smooth(), where the method argument specifies what smoothing technique to use.
Below is an example of using Gaussian kernel regression to smooth the borders of US states by using method=ksmooth.
The smoothness argument controls the bandwidth of the Gaussian that is used to smooth the geometry and has a default value of 1.
us_states_simp3 = smoothr::smooth(us_states, method = "ksmooth", smoothness = 6)Finally, the visual comparison of the original dataset with the simplified and smoothed versions is shown in Figure 5.2.
Differences can be observed between the outputs of the Douglas-Peucker (st_simplify), Visvalingam (ms_simplify), and Gaussian kernel regression (smooth(method=ksmooth) algorithms.
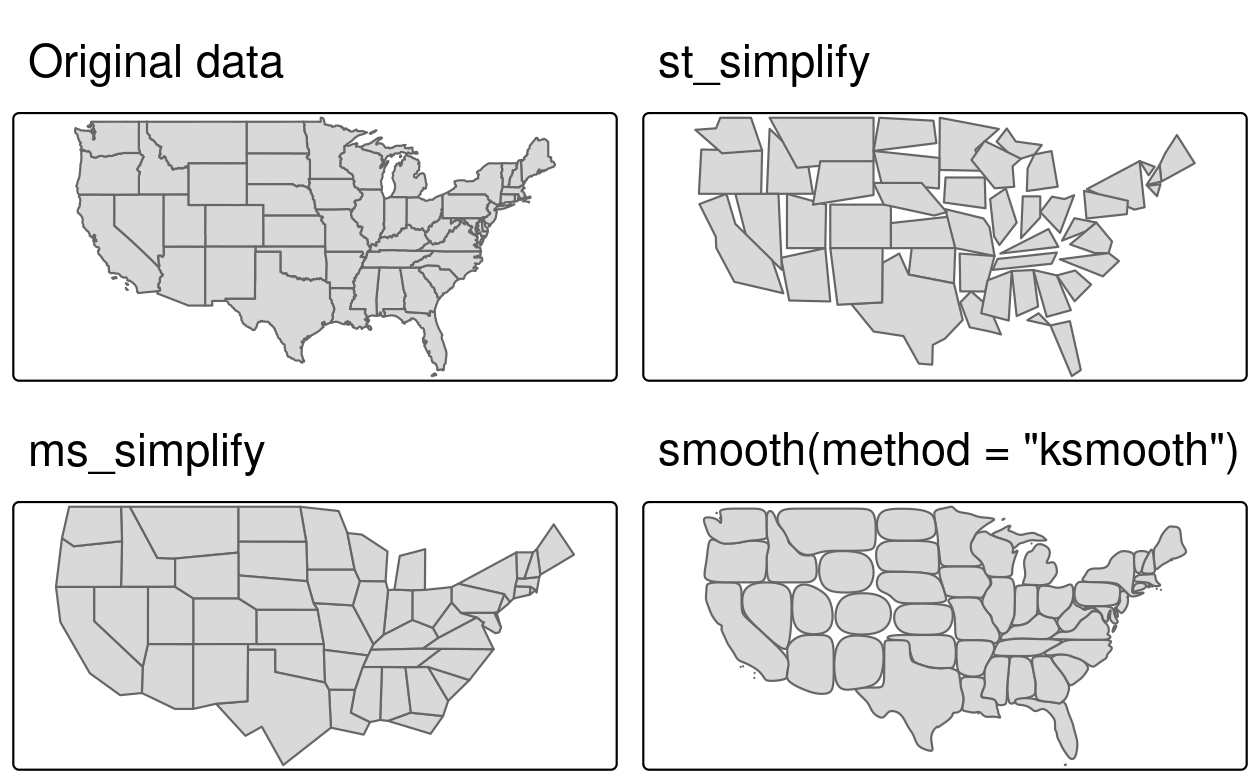
FIGURE 5.2: Polygon simplification in action, comparing the original geometry of the contiguous United States with simplified versions, generated with functions from sf (top-right), rmapshaper (bottom-left), and smoothr (bottom-right) packages.
5.2.2 Centroids
Centroid operations identify the center of geographic objects. Like statistical measures of central tendency (including mean and median definitions of ‘average’), there are many ways to define the geographic center of an object. All of them create single point representations of more complex vector objects.
The most commonly used centroid operation is the geographic centroid.
This type of centroid operation (often referred to as ‘the centroid’) represents the center of mass in a spatial object (think of balancing a plate on your finger).
Geographic centroids have many uses, for example to create a simple point representation of complex geometries, or to estimate distances between polygons.
They can be calculated with the sf function st_centroid() as demonstrated in the code below, which generates the geographic centroids of regions in New Zealand and tributaries to the River Seine, illustrated with black points in Figure 5.3.
nz_centroid = st_centroid(nz)
seine_centroid = st_centroid(seine)Sometimes the geographic centroid falls outside the boundaries of their parent objects (think of a doughnut).
In such cases point on surface operations can be used to guarantee the point will be in the parent object (e.g., for labeling irregular multipolygon objects such as island states), as illustrated by the red points in Figure 5.3.
Notice that these red points always lie on their parent objects.
They were created with st_point_on_surface() as follows:23
nz_pos = st_point_on_surface(nz)
seine_pos = st_point_on_surface(seine)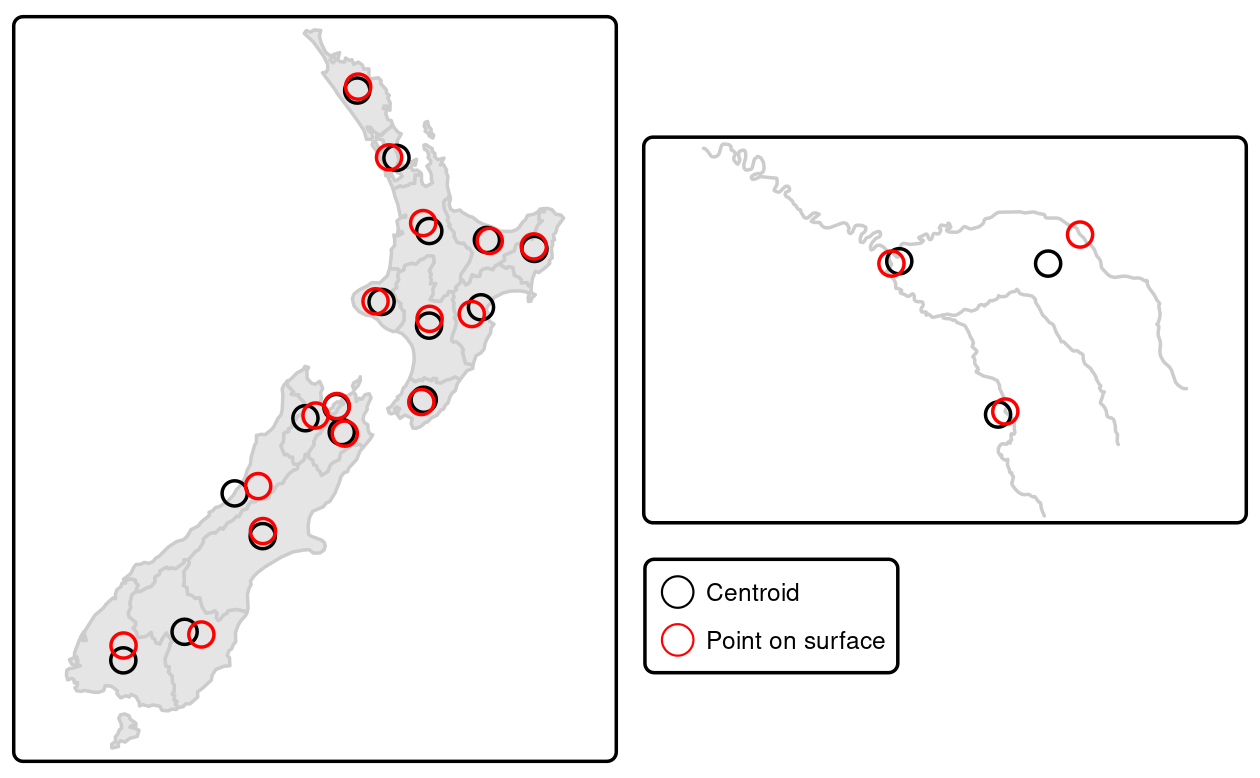
FIGURE 5.3: Centroids (black points) and ‘points on surface’ (red points) of New Zealand’s regions (left) and the Seine (right) datasets.
Other types of centroids exist, including the Chebyshev center and the visual center. We will not explore these here, but it is possible to calculate them using R, as we’ll see in Chapter 11.
5.2.3 Buffers
Buffers are polygons representing the area within a given distance of a geometric feature: regardless of whether the input is a point, line or polygon, the output is a polygon. Unlike simplification (which is often used for visualization and reducing file size), buffering tends to be used for geographic data analysis. How many points are within a given distance of this line? Which demographic groups are within travel distance of this new shop? These kinds of questions can be answered and visualized by creating buffers around the geographic entities of interest.
Figure 5.4 illustrates buffers of different sizes (5 and 50 km) surrounding the River Seine and tributaries.
These buffers were created with commands below, which show that the command st_buffer() requires at least two arguments: an input geometry and a distance, provided in the units of the CRS (in this case meters).
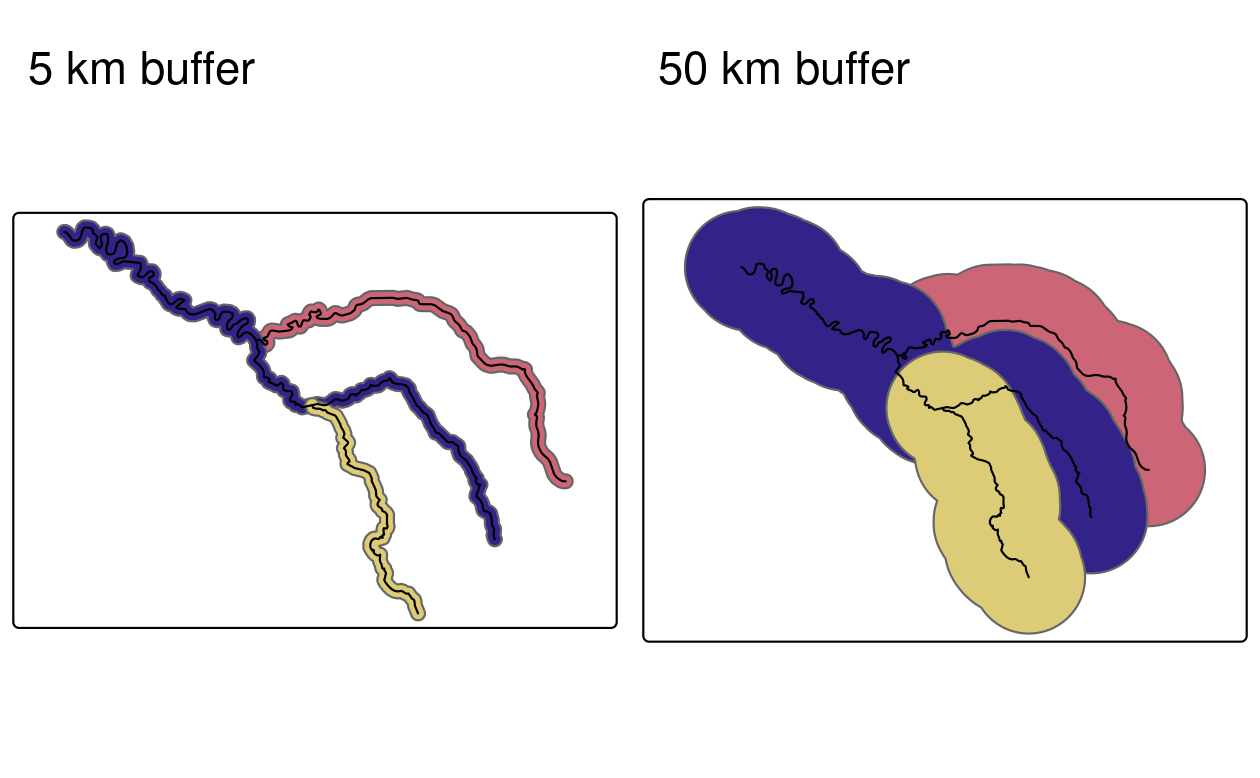
FIGURE 5.4: Buffers around the Seine dataset of 5 km (left) and 50 km (right). Note the colors, which reflect the fact that one buffer is created per geometry feature.
The st_buffer() has a few additional arguments.
The most important ones are:
-
nQuadSegs(when the GEOS engine is used), which means ‘number of segments per quadrant’ and is set by default to 30 (meaning circles created by buffers are composed of \(4 \times 30 = 120\) lines). Unusual cases where it may be useful include when the memory consumed by the output of a buffer operation is a major concern (in which case it should be reduced) or when very high precision is needed (in which case it should be increased) -
max_cells(when the S2 engine is used), the larger the value, the more smooth the buffer will be, but the calculations will take longer -
endCapStyleandjoinStyle(when the GEOS engine is used), which control the appearance of the buffer’s edges -
singleSide(when the GEOS engine is used), which controls whether the buffer is created on one or both sides of the input geometry
5.2.4 Affine transformations
Affine transformation is any transformation that preserves lines and parallelism.
However, angles or length are not necessarily preserved.
Affine transformations include, among others, shifting (translation), scaling and rotation.
Additionally, it is possible to use any combination of these.
Affine transformations are an essential part of geocomputation.
For example, shifting is needed for labels placement, scaling is used in non-contiguous area cartograms (see Section 9.6), and many affine transformations are applied when reprojecting or improving the geometry that was created based on a distorted or wrongly projected map.
The sf package implements affine transformation for objects of classes sfg and sfc.
nz_sfc = st_geometry(nz)Shifting moves every point by the same distance in map units. It could be done by adding a numerical vector to a vector object. For example, the code below shifts all y-coordinates by 100,000 meters to the north, but leaves the x-coordinates untouched (Figure 5.5, left panel).
nz_shift = nz_sfc + c(0, 100000)Scaling enlarges or shrinks objects by a factor.
It can be applied either globally or locally.
Global scaling increases or decreases all coordinates values in relation to the origin coordinates, while keeping all geometries topological relations intact.
It can be done by subtraction or multiplication of a sfg or sfc object.
Local scaling treats geometries independently and requires points around which geometries are going to be scaled, e.g., centroids.
In the example below, each geometry is shrunk by a factor of two around the centroids (Figure 5.5, middle panel).
To achieve that, each object is firstly shifted in a way that its center has coordinates of 0, 0 ((nz_sfc - nz_centroid_sfc)).
Next, the sizes of the geometries are reduced by half (* 0.5).
Finally, each object’s centroid is moved back to the input data coordinates (+ nz_centroid_sfc).
nz_centroid_sfc = st_centroid(nz_sfc)
nz_scale = (nz_sfc - nz_centroid_sfc) * 0.5 + nz_centroid_sfcRotation of two-dimensional coordinates requires a rotation matrix:
\[ R = \begin{bmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \\ \end{bmatrix} \]
It rotates points in a clockwise direction. The rotation matrix can be implemented in R as:
rotation = function(a){
r = a * pi / 180 #degrees to radians
matrix(c(cos(r), sin(r), -sin(r), cos(r)), nrow = 2, ncol = 2)
} The rotation function accepts one argument a — a rotation angle in degrees.
Rotation could be done around selected points, such as centroids (Figure 5.5, right panel).
See vignette("sf3") for more examples.
nz_rotate = (nz_sfc - nz_centroid_sfc) * rotation(30) + nz_centroid_sfc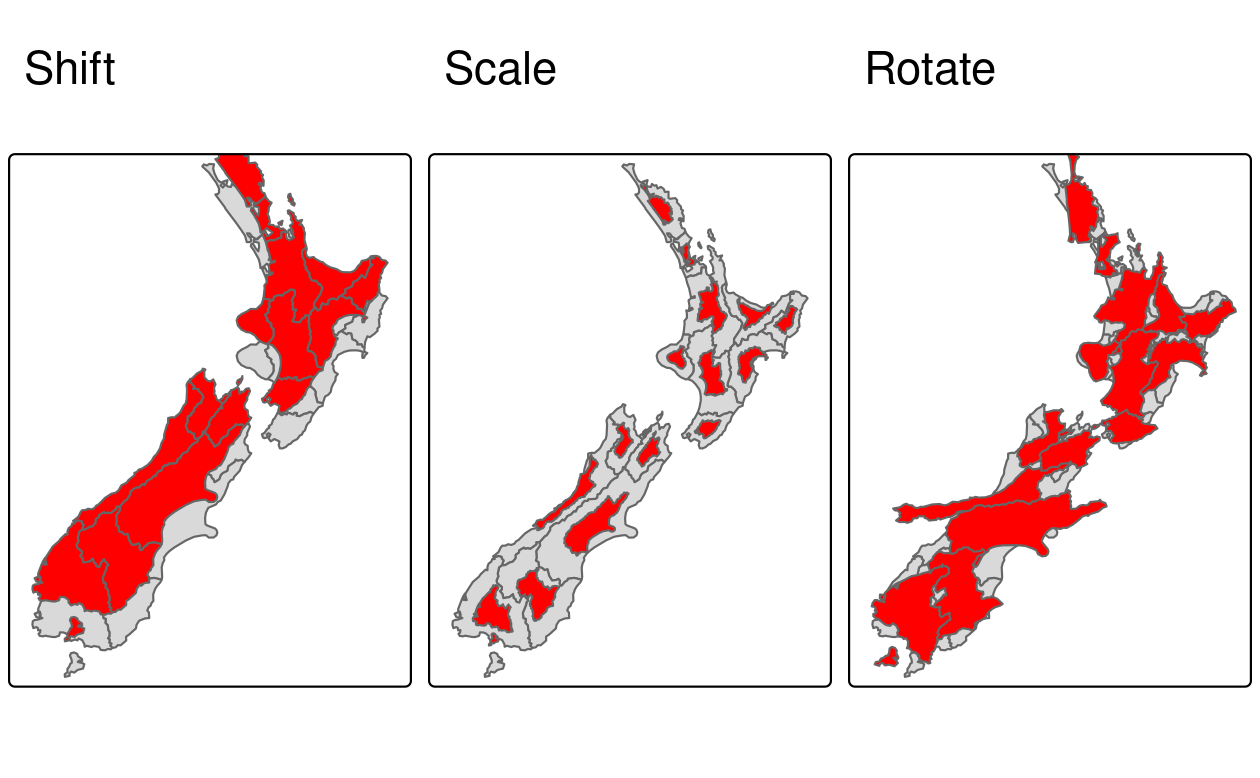
FIGURE 5.5: Affine transformations: shift, scale and rotate.
Finally, the newly created geometries can replace the old ones with the st_set_geometry() function:
nz_scale_sf = st_set_geometry(nz, nz_scale)5.2.5 Clipping
Spatial clipping is a form of spatial subsetting that involves changes to the geometry columns of at least some of the affected features.
Clipping can only apply to features more complex than points: lines, polygons and their ‘multi’ equivalents. To illustrate the concept, we will start with a simple example: two overlapping circles with a center point one unit away from each other and a radius of one (Figure 5.6).
b = st_sfc(st_point(c(0, 1)), st_point(c(1, 1))) # create 2 points
b = st_buffer(b, dist = 1) # convert points to circles
plot(b, border = "gray")
text(x = c(-0.5, 1.5), y = 1, labels = c("x", "y"), cex = 3) # add text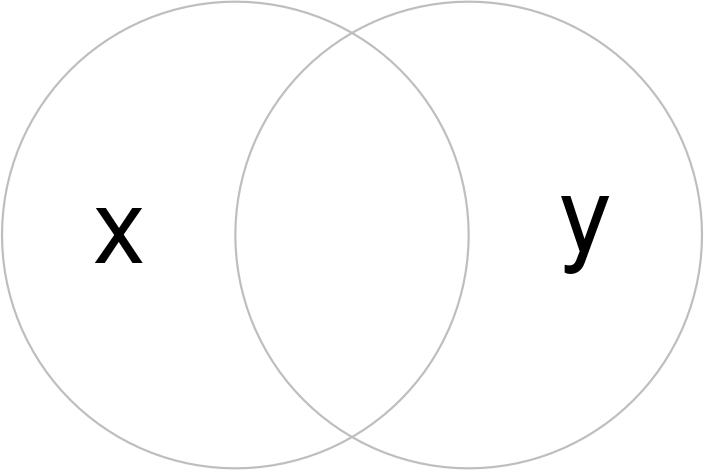
FIGURE 5.6: Overlapping circles.
Imagine you want to select not one circle or the other, but the space covered by both x and y.
This can be done using the function st_intersection(), illustrated using objects named x and y which represent the left- and right-hand circles (Figure 5.7).
x = b[1]
y = b[2]
x_and_y = st_intersection(x, y)
plot(b, border = "gray")
plot(x_and_y, col = "lightgray", border = "gray", add = TRUE) # intersecting area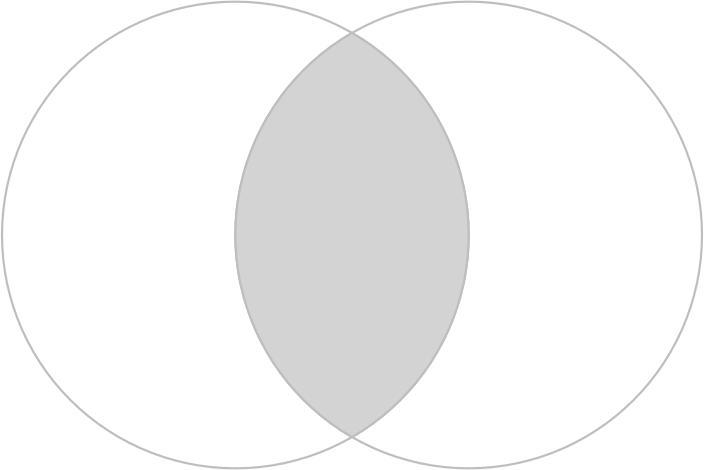
FIGURE 5.7: Overlapping circles with a gray color indicating intersection between them.
The subsequent code chunk demonstrates how this works for all combinations of the ‘Venn’ diagram representing x and y, inspired by Figure 5.1 of the book R for Data Science (Grolemund and Wickham 2016).
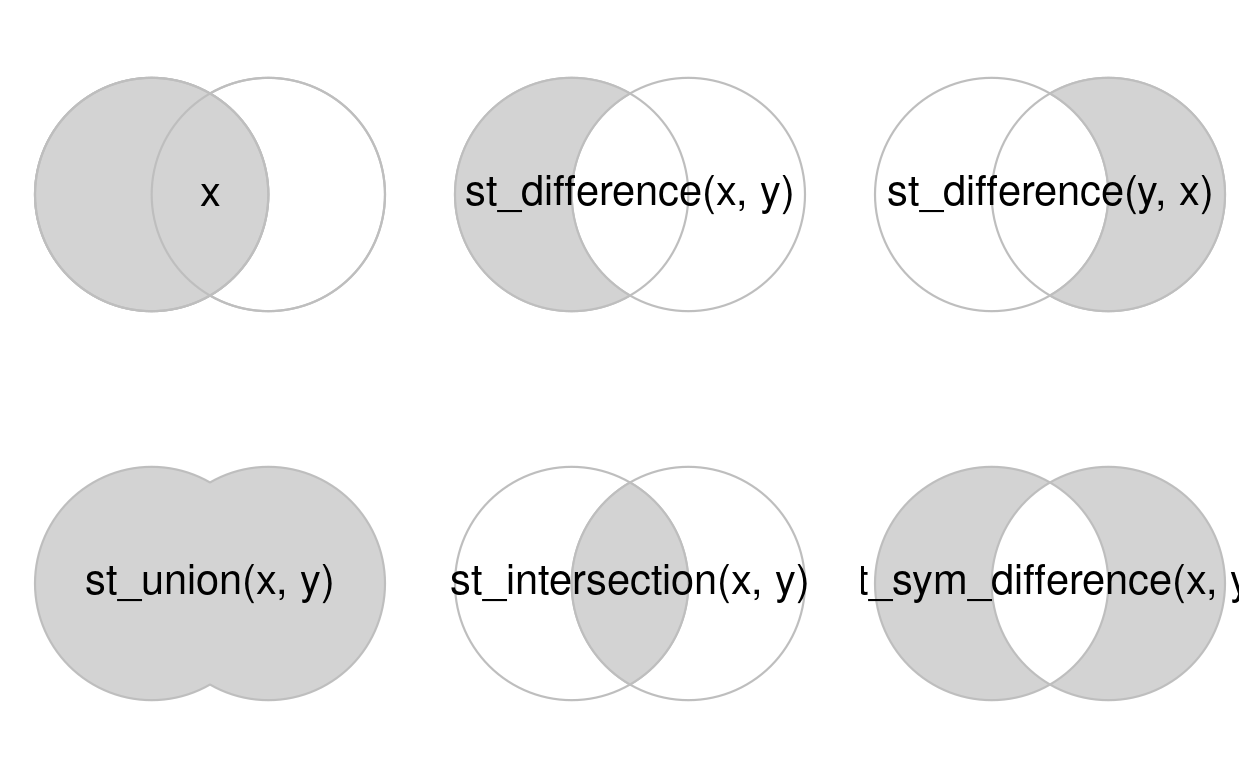
FIGURE 5.8: Spatial equivalents of logical operators.
5.2.6 Subsetting and clipping
Clipping objects can change their geometry, but it can also subset objects, returning only features that intersect (or partly intersect) with a clipping/subsetting object.
To illustrate this point, we will subset points that cover the bounding box of the circles x and y in Figure 5.8.
Some points will be inside just one circle, some will be inside both and some will be inside neither.
st_sample() is used below to generate a simple random distribution of points within the extent of circles x and y, resulting in output illustrated in Figure 5.9, raising the question: how to subset the points to only return the point that intersects with both x and y?
bb = st_bbox(st_union(x, y))
box = st_as_sfc(bb)
set.seed(2024)
p = st_sample(x = box, size = 10)
p_xy1 = p[x_and_y]
plot(box, border = "gray", lty = 2)
plot(x, add = TRUE, border = "gray")
plot(y, add = TRUE, border = "gray")
plot(p, add = TRUE, cex = 3.5)
plot(p_xy1, cex = 5, col = "red", add = TRUE)
text(x = c(-0.5, 1.5), y = 1, labels = c("x", "y"), cex = 3)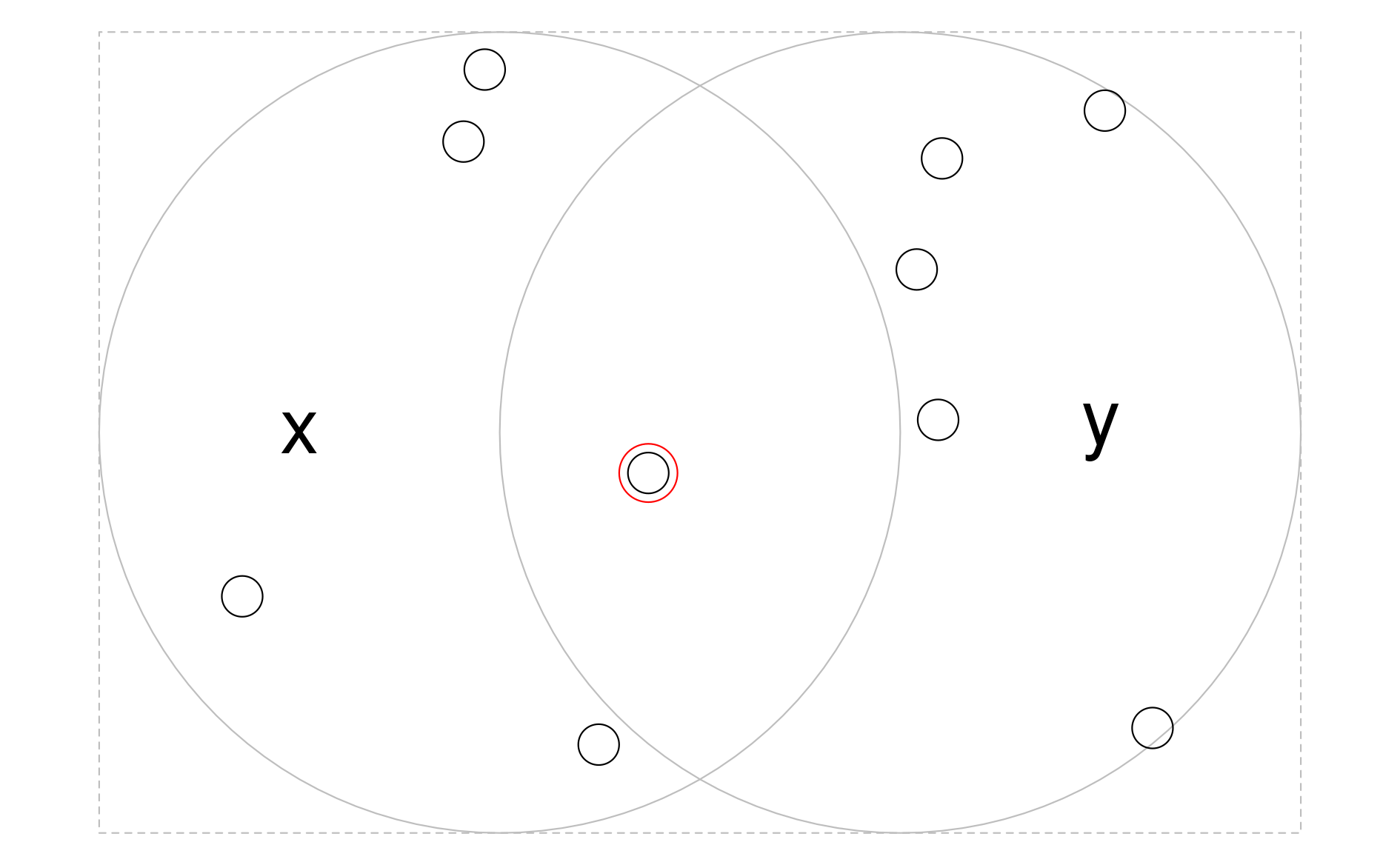
FIGURE 5.9: Randomly distributed points within the bounding box enclosing circles x and y. The point that intersects with both objects x and y is highlighted.
bb = st_bbox(st_union(x, y))
box = st_as_sfc(bb)
set.seed(2024)
p = st_sample(x = box, size = 10)
x_and_y = st_intersection(x, y)The code chunk below demonstrates three ways to achieve the same result.
We can use the intersection of x and y (represented by x_and_y in the previous code chunk) as a subsetting object directly, as shown in the first line in the code chunk below.
We can also find the intersection between the input points represented by p and the subsetting/clipping object x_and_y, as demonstrated in the second line in the code chunk below.
This second approach will return features that partly intersect with x_and_y but with modified geometries for spatially extensive features that cross the border of the subsetting object.
The third approach is to create a subsetting object using the binary spatial predicate st_intersects(), introduced in the previous chapter.
The results are identical (except superficial differences in attribute names), but the implementation differs substantially:
# way #1
p_xy1 = p[x_and_y]
# way #2
p_xy2 = st_intersection(p, x_and_y)
# way #3
sel_p_xy = st_intersects(p, x, sparse = FALSE)[, 1] &
st_intersects(p, y, sparse = FALSE)[, 1]
p_xy3 = p[sel_p_xy]Although the example above is rather contrived and provided for educational rather than applied purposes, and we encourage the reader to reproduce the results to deepen understanding for handling geographic vector objects in R, it raises an important question: which implementation to use? Generally, more concise implementations should be favored, meaning the first approach above. We will return to the question of choosing between different implementations of the same technique or algorithm in Chapter 11.
5.2.7 Geometry unions
As we saw in Section 3.2.3, spatial aggregation can silently dissolve the geometries of touching polygons in the same group.
This is demonstrated in the code chunk below in which 48 US states and the District of Columbia (us_states) are aggregated into four regions using base and dplyr functions (see results in Figure 5.10):
regions = aggregate(x = us_states[, "total_pop_15"], by = list(us_states$REGION),
FUN = sum, na.rm = TRUE)
regions2 = us_states |>
group_by(REGION) |>
summarize(pop = sum(total_pop_15, na.rm = TRUE))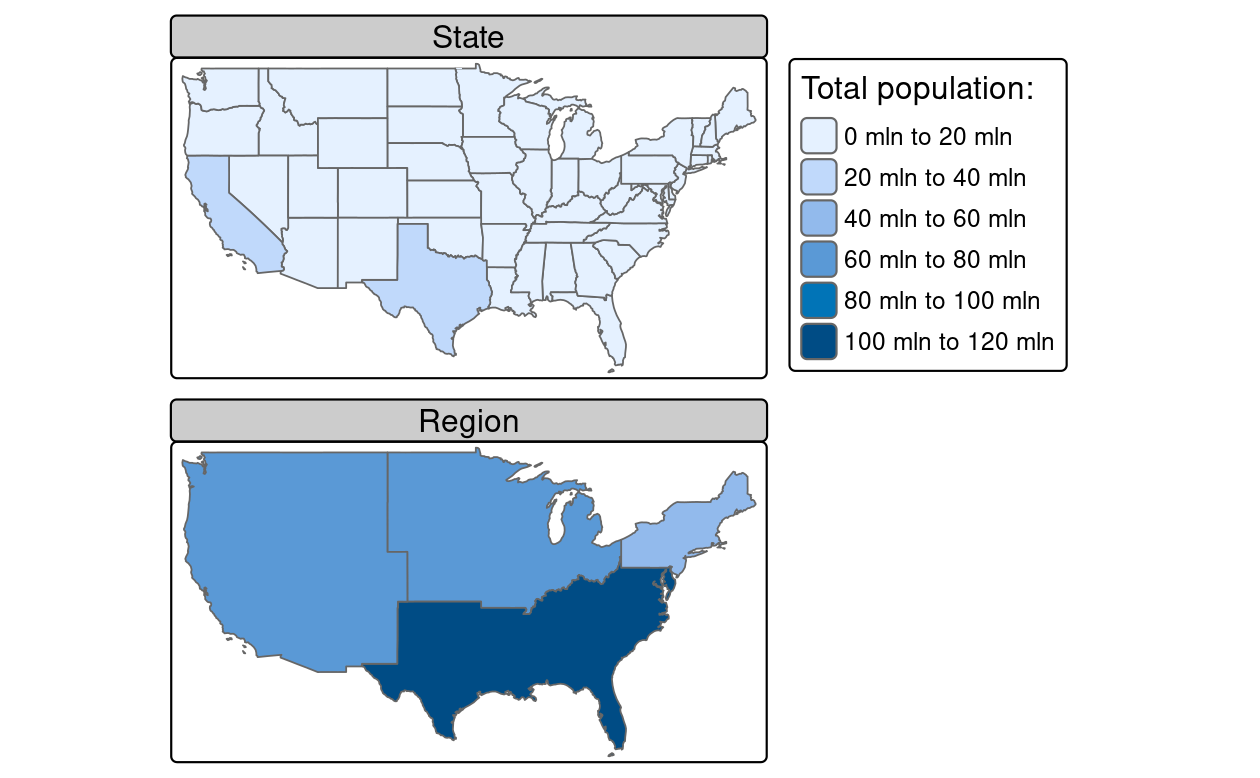
FIGURE 5.10: Spatial aggregation on contiguous polygons, illustrated by aggregating the population of US states into regions, with population represented by color. Note the operation automatically dissolves boundaries between states.
What is going on in terms of the geometries?
Behind the scenes, both aggregate() and summarize() combine the geometries and dissolve the boundaries between them using st_union().
This is demonstrated in the code chunk below which creates a united western US:
us_west = us_states[us_states$REGION == "West", ]
us_west_union = st_union(us_west)The function can take two geometries and unite them, as demonstrated in the code chunk below which creates a united western block incorporating Texas (challenge: reproduce and plot the result):
texas = us_states[us_states$NAME == "Texas", ]
texas_union = st_union(us_west_union, texas)5.2.8 Type transformations
Geometry casting is a powerful operation that enables transformation of the geometry type.
It is implemented in the st_cast() function from the sf package.
Importantly, st_cast() behaves differently on single simple feature geometry (sfg) objects, simple feature geometry column (sfc) and simple features objects.
Let’s create a multipoint to illustrate how geometry casting works on simple feature geometry (sfg) objects:
multipoint = st_multipoint(matrix(c(1, 3, 5, 1, 3, 1), ncol = 2))In this case, st_cast() can be useful to transform the new object into a linestring or a polygon (Figure 5.11).
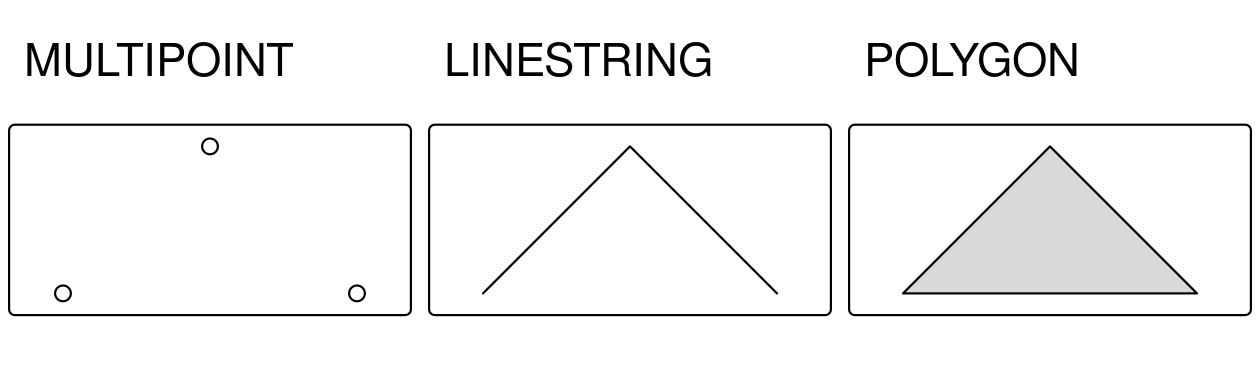
FIGURE 5.11: Examples of a linestring and a polygon casted from a multipoint geometry.
Conversion from multipoint to linestring is a common operation that creates a line object from ordered point observations, such as GPS measurements or geotagged media. This, in turn, allows us to perform spatial operations such as the calculation of the length of the path traveled. Conversion from multipoint or linestring to polygon is often used to calculate an area, for example from the set of GPS measurements taken around a lake or from the corners of a building lot.
The transformation process can be also reversed using st_cast():
multipoint_2 = st_cast(linestring, "MULTIPOINT")
multipoint_3 = st_cast(polyg, "MULTIPOINT")
all.equal(multipoint, multipoint_2)
#> [1] TRUE
all.equal(multipoint, multipoint_3)
#> [1] TRUEsfg), st_cast() also provides geometry casting from non-multi-types to multi-types (e.g., POINT to MULTIPOINT) and from multi-types to non-multi-types.
However, when casting from multi-types to non-multi-types, only the first element of the old object would remain in the output object.
Geometry casting of simple features geometry column (sfc) and simple features objects works the same as for sfg in most of the cases.
One important difference is the conversion between multi-types to non-multi-types.
As a result of this process, multi-objects of sfc or sf are split into many non-multi-objects.
Let’s say we have the following sf objects:
-
POI- POINT type (with one point by definition) -
MPOI- MULTIPOINT type with four points -
LIN- LINESTRING type with one linestring containing five points -
MLIN- MULTILINESTRING type with two linestrings (one with five points and one with two points) -
POL- POLYGON type with one polygon (created using five points) -
MPOL- MULTIPOLYGON type consisting of two polygons (both consisting of five points) -
GC- GEOMETRYCOLLECTION type with two geometries, a MULTIPOINT (four points) and a LINESTRING (five points)
Table 5.1 shows possible geometry type transformations on the simple feature objects listed above.
Single simple feature geometries (represented by the first column in the table) can be transformed into multiple geometry types, represented by the columns in Table 5.1.
Some transformations are not possible: you cannot convert a single point into a multilinestring or a polygon, for example, explaining why the cells [1, 4:5] in the table contain NA.
Some transformations split single features input into multiple sub-features, ‘expanding’ sf objects (adding new rows with duplicate attribute values).
When a multipoint geometry consisting of five pairs of coordinates is tranformed into a ‘POINT’ geometry, for example, the output will contain five features.
| POI | MPOI | LIN | MLIN | POL | MPOL | GC | |
|---|---|---|---|---|---|---|---|
| POI(1) | 1 | 1 | 1 | NA | NA | NA | NA |
| MPOI(1) | 4 | 1 | 1 | 1 | 1 | NA | NA |
| LIN(1) | 5 | 1 | 1 | 1 | 1 | NA | NA |
| MLIN(1) | 7 | 2 | 2 | 1 | NA | NA | NA |
| POL(1) | 5 | 1 | 1 | 1 | 1 | 1 | NA |
| MPOL(1) | 10 | 1 | NA | 1 | 2 | 1 | 1 |
| GC(1) | 9 | 1 | NA | NA | NA | NA | 1 |
Note: Values in parentheses represent the number of features; NA means the operation is not available
Let’s try to apply geometry type transformations on a new object, multilinestring_sf, as an example (on the left in Figure 5.12):
multilinestring_list = list(matrix(c(1, 4, 5, 3), ncol = 2),
matrix(c(4, 4, 4, 1), ncol = 2),
matrix(c(2, 4, 2, 2), ncol = 2))
multilinestring = st_multilinestring(multilinestring_list)
multilinestring_sf = st_sf(geom = st_sfc(multilinestring))
multilinestring_sf
#> Simple feature collection with 1 feature and 0 fields
#> Geometry type: MULTILINESTRING
#> Dimension: XY
#> Bounding box: xmin: 1 ymin: 1 xmax: 4 ymax: 5
#> CRS: NA
#> geom
#> 1 MULTILINESTRING ((1 5, 4 3)...You can imagine it as a road or river network.
The new object has only one row that defines all the lines.
This restricts the number of operations that can be done, for example it prevents adding names to each line segment or calculating lengths of single lines.
The st_cast() function can be used in this situation, as it separates one mutlilinestring into three linestrings.
linestring_sf2 = st_cast(multilinestring_sf, "LINESTRING")
linestring_sf2
#> Simple feature collection with 3 features and 0 fields
#> Geometry type: LINESTRING
#> Dimension: XY
#> Bounding box: xmin: 1 ymin: 1 xmax: 4 ymax: 5
#> CRS: NA
#> geom
#> 1 LINESTRING (1 5, 4 3)
#> 2 LINESTRING (4 4, 4 1)
#> 3 LINESTRING (2 2, 4 2)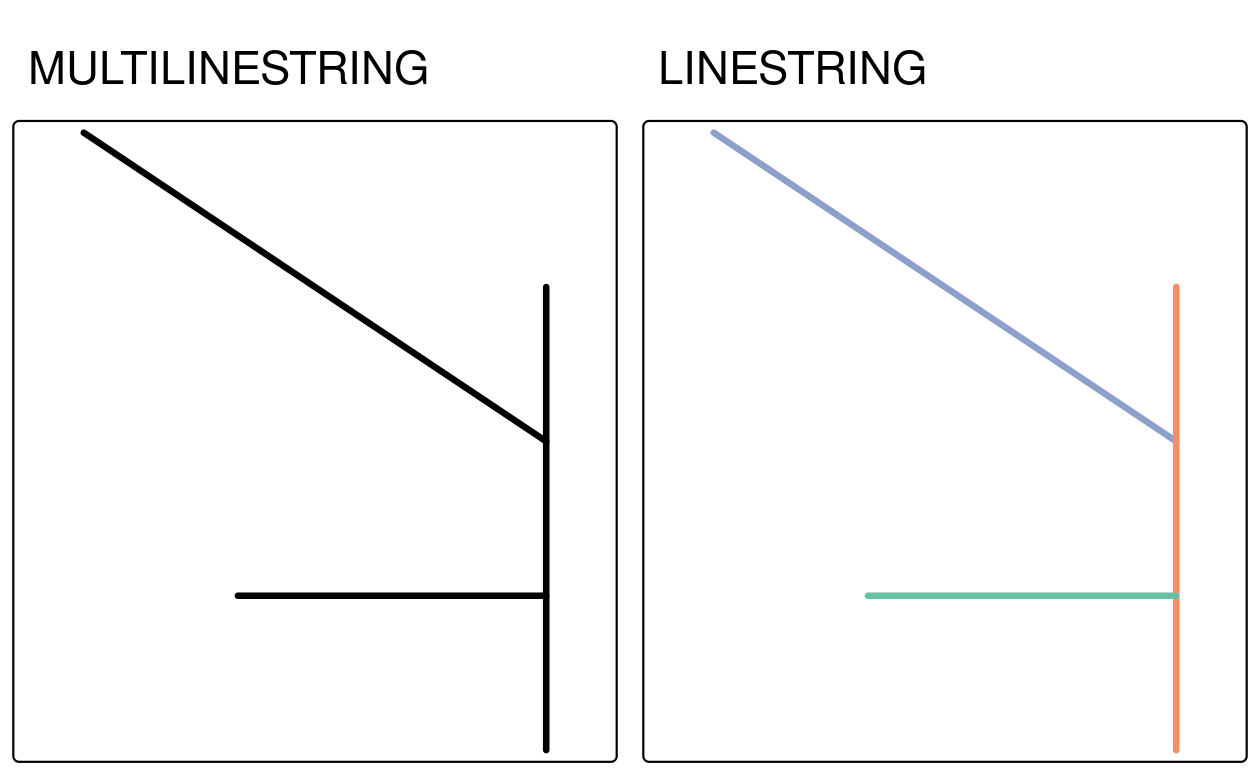
FIGURE 5.12: Examples of type casting between multilinestring (left) and linestring (right).
The newly created object allows for attributes creation (see more in Section 3.2.5) and length measurements:
linestring_sf2$name = c("Riddle Rd", "Marshall Ave", "Foulke St")
linestring_sf2$length = st_length(linestring_sf2)
linestring_sf2
#> Simple feature collection with 3 features and 2 fields
#> Geometry type: LINESTRING
#> Dimension: XY
#> Bounding box: xmin: 1 ymin: 1 xmax: 4 ymax: 5
#> CRS: NA
#> geom name length
#> 1 LINESTRING (1 5, 4 3) Riddle Rd 3.61
#> 2 LINESTRING (4 4, 4 1) Marshall Ave 3.00
#> 3 LINESTRING (2 2, 4 2) Foulke St 2.005.3 Geometric operations on raster data
Geometric raster operations include the shifting, flipping, mirroring, scaling, rotation or warping of images. These operations are necessary for a variety of applications including georeferencing, used to allow images to be overlaid on an accurate map with a known CRS (Liu and Mason 2009). A variety of georeferencing techniques exist, including:
- Georectification based on known ground control points
- Orthorectification, which also accounts for local topography
- Image registration is used to combine images of the same thing, but shot from different sensors by aligning one image with another (in terms of coordinate system and resolution)
R is rather unsuitable for the first two points since these often require manual intervention which is why they are usually done with the help of dedicated GIS software (see also Chapter 10). On the other hand, aligning several images is possible in R and this section shows among others how to do so. This often includes changing the extent, the resolution and the origin of an image. A matching projection is of course also required but is already covered in Section 7.8.
In any case, there are other reasons to perform a geometric operation on a single raster image. For instance, in Chapter 14 we define metropolitan areas in Germany as 20 km2 pixels with more than 500,000 inhabitants. The original inhabitant raster, however, has a resolution of 1 km2 which is why we will decrease (aggregate) the resolution by a factor of 20 (see Section 14.5). Another reason for aggregating a raster is simply to decrease run-time or save disk space. Of course, this approach is only recommended if the task at hand allows a coarser resolution of raster data.
5.3.1 Geometric intersections
In Section 4.3.1 we have shown how to extract values from a raster overlaid by other spatial objects.
To retrieve a spatial output, we can use almost the same subsetting syntax.
The only difference is that we have to make clear that we would like to keep the matrix structure by setting the drop argument to FALSE.
This will return a raster object containing the cells whose midpoints overlap with clip.
elev = rast(system.file("raster/elev.tif", package = "spData"))
clip = rast(xmin = 0.9, xmax = 1.8, ymin = -0.45, ymax = 0.45,
resolution = 0.3, vals = rep(1, 9))
elev[clip, drop = FALSE]
#> class : SpatRaster
#> size : 2, 1, 1 (nrow, ncol, nlyr)
#> resolution : 0.5, 0.5 (x, y)
#> extent : 1, 1.5, -0.5, 0.5 (xmin, xmax, ymin, ymax)
#> coord. ref. : lon/lat WGS 84 (EPSG:4326)
#> source(s) : memory
#> varname : elev
#> name : elev
#> min value : 18
#> max value : 24For the same operation, we can also use the intersect() and crop() command.
5.3.2 Extent and origin
When merging or performing map algebra on rasters, their resolution, projection, origin and/or extent have to match. Otherwise, how should we add the values of one raster with a resolution of 0.2 decimal degrees to a second raster with a resolution of 1 decimal degree? The same problem arises when we would like to merge satellite imagery from different sensors with different projections and resolutions. We can deal with such mismatches by aligning the rasters.
In the simplest case, two images only differ with regard to their extent.
The following code adds one row and two columns to each side of the raster while setting all new values to NA (Figure 5.13).
elev = rast(system.file("raster/elev.tif", package = "spData"))
elev_2 = extend(elev, c(1, 2))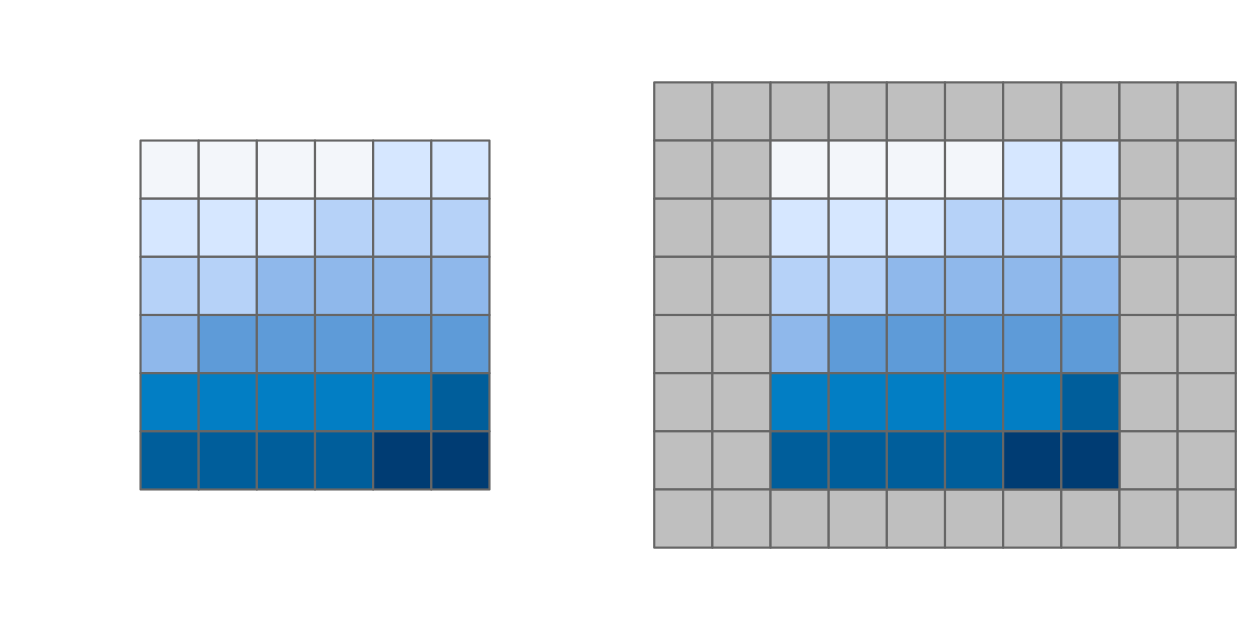
FIGURE 5.13: Original raster (left) and the same raster (right) extended by one row on the top and bottom and two columns on the left and right.
Performing an algebraic operation on two objects with differing extents in R, the terra package returns an error.
elev_3 = elev + elev_2
#> Error:
#> ! [+] extents do not matchHowever, we can align the extent of two rasters with extend().
Instead of telling the function how many rows or columns should be added (as done before), we allow it to figure it out by using another raster object.
Here, we extend the elev object to the extent of elev_2.
The values of the newly added rows and columns are set to NA.
elev_4 = extend(elev, elev_2)
The origin of a raster is the cell corner closest to the coordinates (0, 0).
The origin() function returns the coordinates of the origin.
In the example below a cell corner exists with coordinates (0, 0), but that is not necessarily the case.
origin(elev_4)
#> [1] 0 0If two rasters have different origins, their cells do not overlap completely which would make map algebra impossible.
To change the origin, use origin().24
Figure 5.14 reveals the effect of changing the origin in this way.
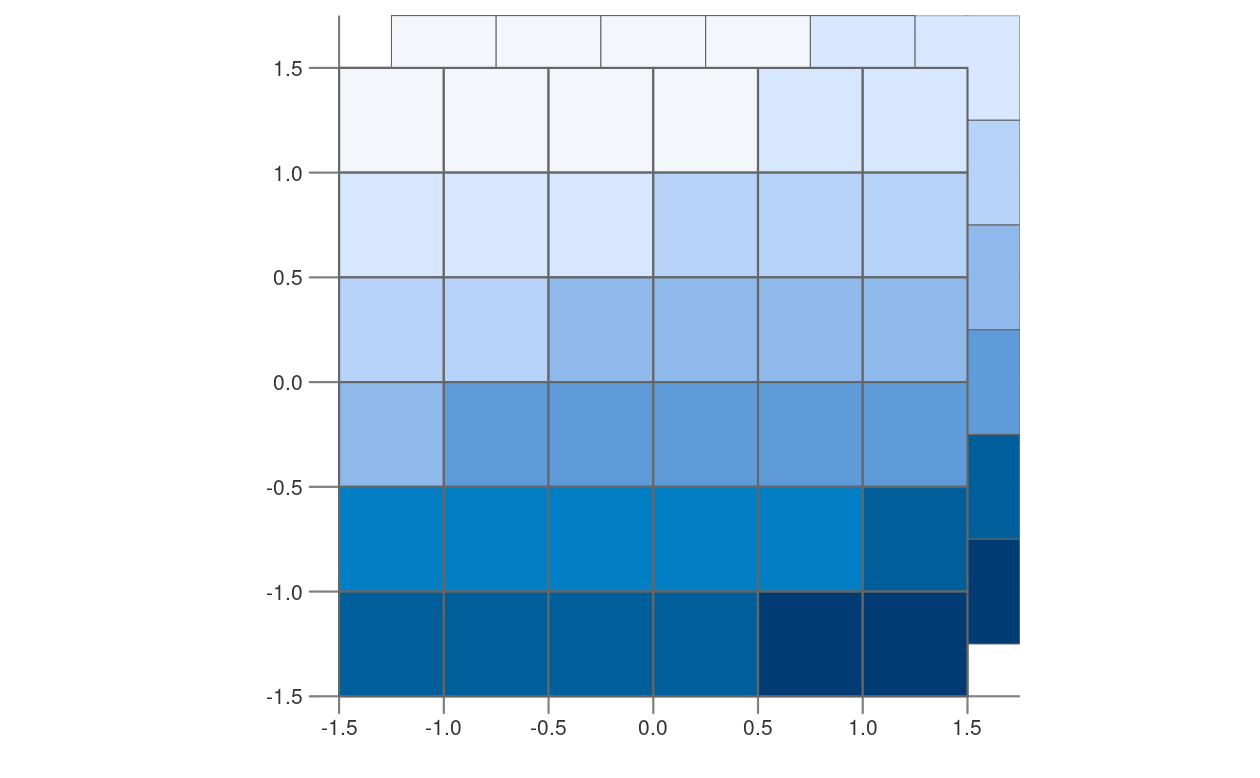
FIGURE 5.14: Rasters with identical values but different origins.
Note that changing the resolution (next section) frequently also changes the origin.
5.3.3 Aggregation and disaggregation
Raster datasets can also differ with regard to their resolution.
To match resolutions, one can either decrease (aggregate()) or increase (disagg()) the resolution of one raster.25
As an example, we here change the spatial resolution of dem (found in the spDataLarge package) by a factor of 5 (Figure 5.15).
Additionally, the output cell value is going to correspond to the mean of the input cells (note that one could use other functions as well, such as median(), sum(), etc.):
dem = rast(system.file("raster/dem.tif", package = "spDataLarge"))
dem_agg = aggregate(dem, fact = 5, fun = mean)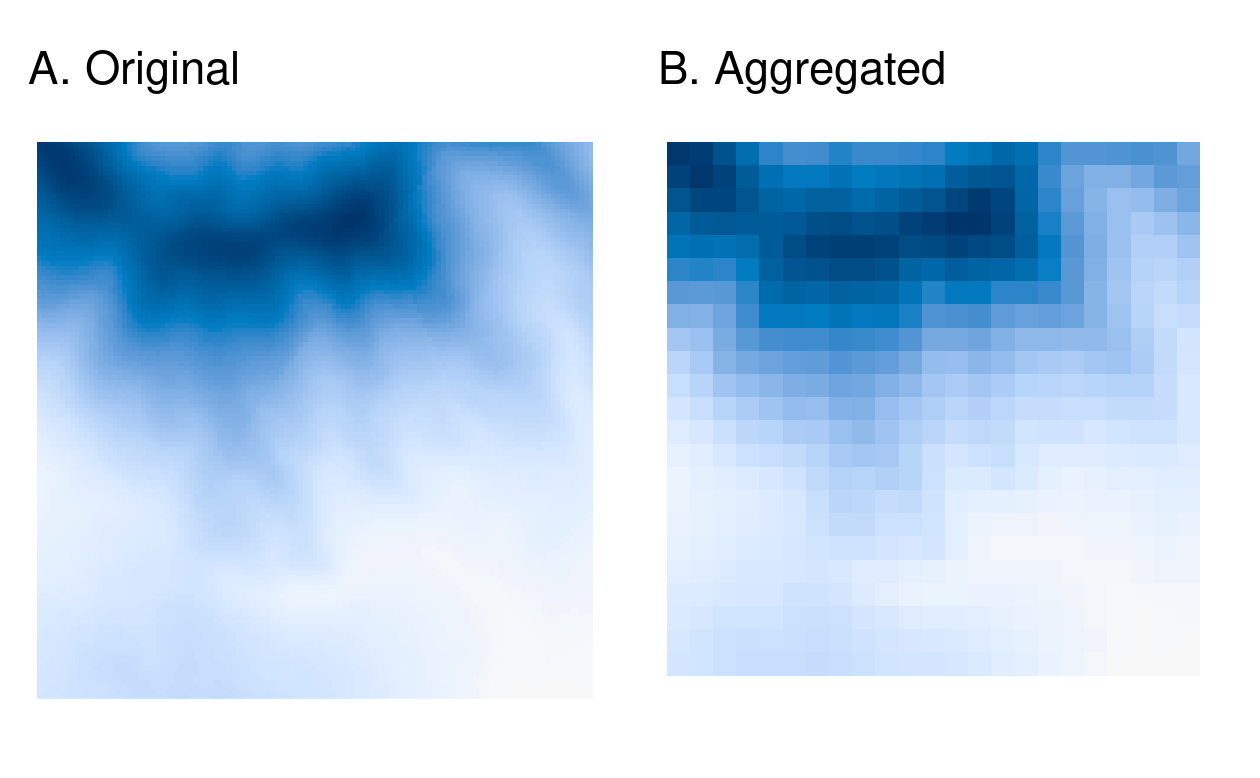
FIGURE 5.15: Original raster (left) and aggregated raster (right).
Table 5.2 compares the properties of the original and aggregated raster.
Notice that “decreasing” the resolution with aggregate() increases the resolution from \((30.85, 30.85)\) to \((154.25, 154.25)\).
This is done by decreasing the number of rows (nrow) and columns (ncol) (see Section 2.3).
The extent was slightly adjusted to accommodate the new grid size.
| Object | Resolution | Dimensions | Extent |
|---|---|---|---|
| dem | (30.85, 30.85) | 117 * 117 | 794599.1, 798208.6, 8931775, 8935384 |
| dem_agg | (154.25, 154.25) | 24 * 24 | 794599.1, 798301.1, 8931682, 8935384 |
The disagg() function increases the resolution of raster objects.
It comes with two methods on how to compute the values of the newly created cells: the default method (method = "near") simply gives all output cells the value of the input cell, and hence duplicates values, which translates into a ‘blocky’ output.
The bilinear method uses the four nearest pixel centers of the input image (orange colored points in Figure 5.16) to compute an average weighted by distance (arrows in Figure 5.16).
The value of the output cell is represented by a square in the upper left corner in Figure 5.16.
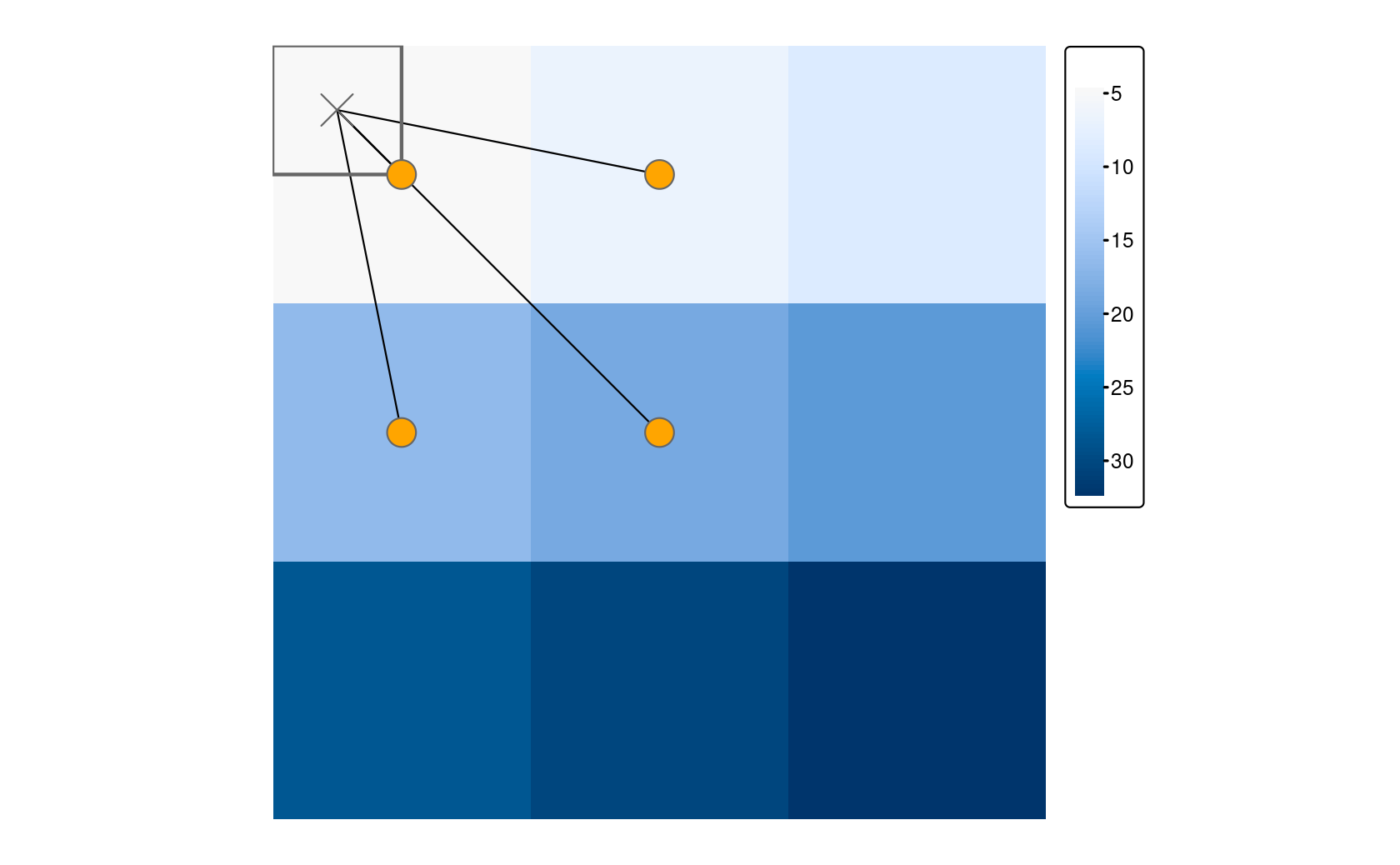
FIGURE 5.16: The distance-weighted average of the four closest input cells determine the output when using the bilinear method for disaggregation.
Comparing the values of dem and dem_disagg tells us that they are not identical (you can also use compareGeom() or all.equal()).
However, this was hardly to be expected, since disaggregating is a simple interpolation technique.
It is important to keep in mind that disaggregating results in a finer resolution; the corresponding values, however, are only as accurate as their lower resolution source.
5.3.4 Resampling
The above methods of aggregation and disaggregation are only suitable when we want to change the resolution of our raster by the aggregation/disaggregation factor. However, what to do when we have two or more rasters with different resolutions and origins? This is the role of resampling – a process of computing values for new pixel locations. In short, this process takes the values of our original raster and recalculates new values for a target raster with custom resolution and origin (Figure 5.17).
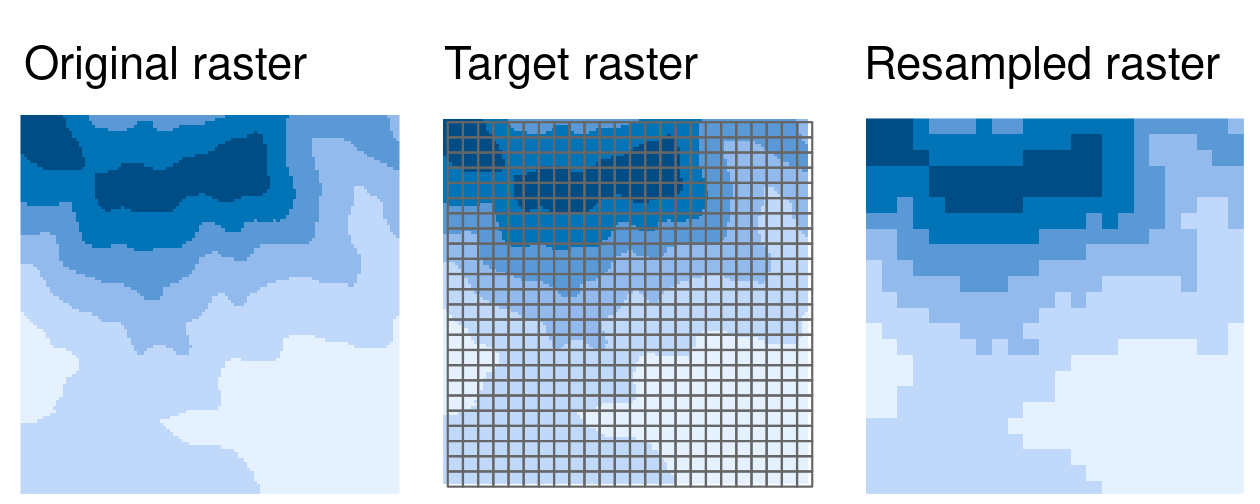
FIGURE 5.17: Resampling of an original (input) raster into a target raster with custom resolution and origin.
There are several methods for estimating values for a raster with different resolutions/origins, as shown in Figure 5.18. The main resampling methods include:
- Nearest neighbor: assigns the value of the nearest cell of the original raster to the cell of the target one. This is a fast simple technique that is usually suitable for resampling categorical rasters.
- Bilinear interpolation: assigns a weighted average of the four nearest cells from the original raster to the cell of the target one (Figure 5.16). This is the fastest method that is appropriate for continuous rasters.
- Cubic interpolation: uses values of the 16 nearest cells of the original raster to determine the output cell value, applying third-order polynomial functions. Used for continuous rasters and results in a smoother surface compared to bilinear interpolation but is computationally more demanding.
- Cubic spline interpolation: also uses values of the 16 nearest cells of the original raster to determine the output cell value, but applies cubic splines (piece-wise third-order polynomial functions). Used for continuous rasters.
- Lanczos windowed sinc resampling: uses values of the 36 nearest cells of the original raster to determine the output cell value. Used for continuous rasters.26
The above explanation highlights that only nearest neighbor resampling is suitable for categorical rasters, while all methods can be used (with different outcomes) for continuous rasters. Please note also that the methods gain both in complexity and processing time from top to bottom. Moreover, resampling can be done using statistics (e.g., minimum or mode) of all contributing cells.
To apply resampling, the terra package provides a resample() function.
It accepts an input raster (x), a raster with target spatial properties (y), and a resampling method (method).
We need a raster with target spatial properties to see how the resample() function works.
For this example, we create target_rast, but you would often use an already existing raster object.
target_rast = rast(xmin = 794650, xmax = 798250,
ymin = 8931750, ymax = 8935350,
resolution = 300, crs = "EPSG:32717")Next, we need to provide our two raster objects as the first two arguments and one of the resampling methods described above.
dem_resampl = resample(dem, y = target_rast, method = "bilinear")Figure 5.18 shows a comparison of different resampling methods on the dem object.
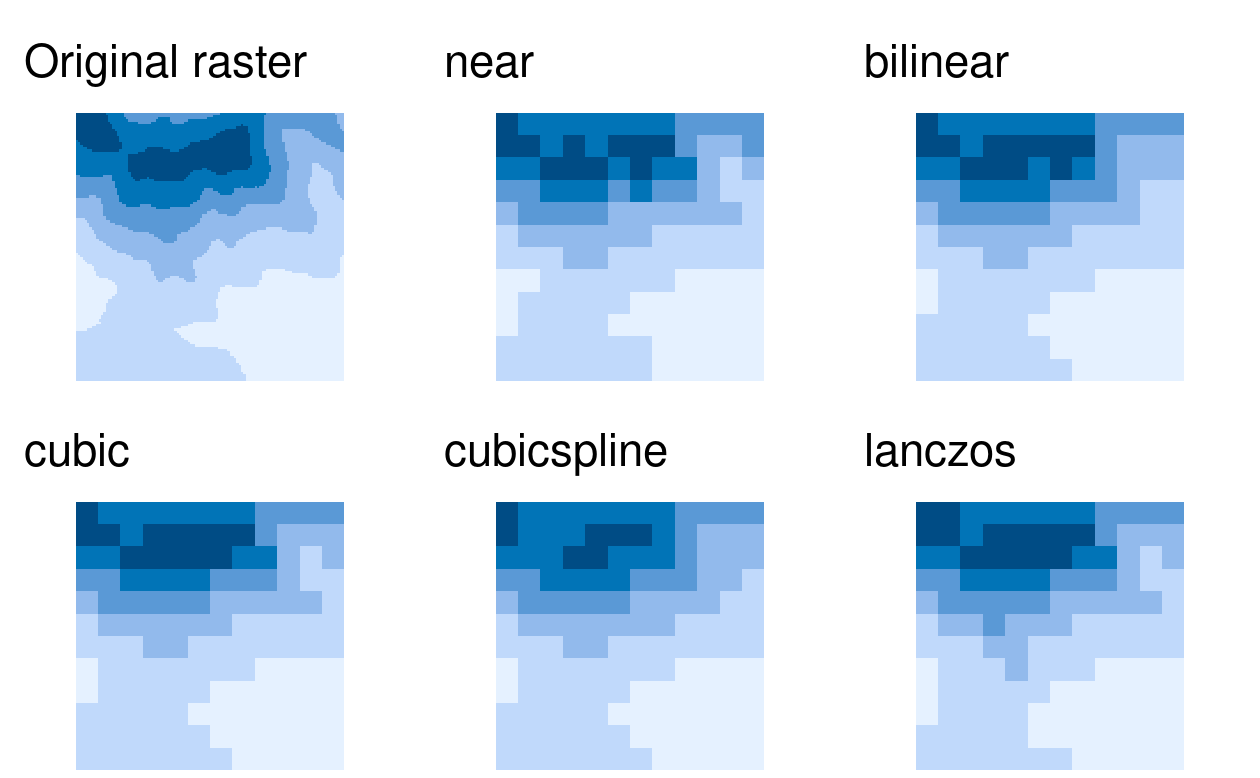
FIGURE 5.18: Visual comparison of the original raster and five different resampling methods.
The resample() function also has some additional resampling methods, including sum, min, q1, med, q3, max, average, mode, and rms.
All of them calculate a given statistic based on the values of all non-NA contributing grid cells.
For example, sum is useful when each raster cell represents a spatially extensive variable (e.g., number of people).
As an effect of using sum, the resampled raster should have the same total number of people as the original one.
As you will see in Section 7.8, raster reprojection is a special case of resampling when our target raster has a different CRS than the original raster.
Most geometry operations in terra are user-friendly, rather fast, and work on large raster objects. However, there could be some cases when terra is not the most performant either for extensive rasters or many raster files, and some alternatives should be considered.
The most established alternatives come with the GDAL library. It contains several utility functions, including:
-
gdalinfo- lists various information about a raster file, including its resolution, CRS, bounding box, and more -
gdal_translate- converts raster data between different file formats -
gdal_rasterize- converts vector data into raster files -
gdalwarp- allows for raster mosaicing, resampling, cropping, and reprojecting
sf::gdal_utils(), the gdalUtilities package, or via system commands (see Section 10.6).
Importantly, all of these functions expect a raster file path as an input and often return their output as a raster file (for example, gdalUtilities::gdal_translate("my_file.tif", "new_file.tif", t_srs = "EPSG:4326")).
This is very different from the usual terra approach, which expects SpatRaster objects as inputs.
5.4 Exercises
E1. Generate and plot simplified versions of the nz dataset.
Experiment with different values of keep (ranging from 0.5 to 0.00005) for ms_simplify() and dTolerance (from 100 to 100,000) st_simplify().
- At what value does the form of the result start to break down for each method, making New Zealand unrecognizable?
- Advanced: What is different about the geometry type of the results from
st_simplify()compared with the geometry type ofms_simplify()? What problems does this create and how can this be resolved?
E2. In the first exercise in Chapter Spatial Data Operations it was established that Canterbury region had 70 of the 101 highest points in New Zealand.
Using st_buffer(), how many points in nz_height are within 100 km of Canterbury?
E3. Find the geographic centroid of New Zealand. How far is it from the geographic centroid of Canterbury?
E4. Most world maps have a north-up orientation.
A world map with a south-up orientation could be created by a reflection (one of the affine transformations not mentioned in this chapter) of the world object’s geometry.
Write code to do so.
Hint: you can to use the rotation() function from this chapter for this transformation.
Bonus: create an upside-down map of your country.
E5. Run the code in Section 5.2.6. With reference to the objects created in that section, subset the point in p that is contained within x and y.
- Using base subsetting operators.
- Using an intermediary object created with
st_intersection().
E6. Calculate the length of the boundary lines of US states in meters.
Which state has the longest border and which has the shortest?
Hint: The st_length function computes the length of a LINESTRING or MULTILINESTRING geometry.
E7. Read the srtm.tif file into R (srtm = rast(system.file("raster/srtm.tif", package = "spDataLarge"))).
This raster has a resolution of 0.00083 * 0.00083 degrees.
Change its resolution to 0.01 * 0.01 degrees using all of the methods available in the terra package.
Visualize the results.
Can you notice any differences between the results of these resampling methods?