1 Introducción
Este libro trata de utilizar el poder de los ordenadores para hacer cosas con los datos geográficos. Enseña una serie de habilidades espaciales, entre las que se incluyen: la lectura, escritura y manipulación de datos geográficos; la elaboración de mapas estáticos e interactivos; la aplicación de la geocomputación para resolver problemas del mundo real; y la modelización de fenómenos geográficos. Al demostrar cómo se pueden enlazar varias operaciones geográficas, en “trozos de código” reproducibles que intercalan la prosa, el libro también enseña un flujo de trabajo transparente y, por tanto, científico. Aprender a utilizar la gran cantidad de herramientas geoespaciales disponibles en la línea de comandos de R puede ser emocionante, pero crear otras nuevas puede ser realmente liberador. El uso del enfoque basado en la línea de comandos que se enseña a lo largo del libro, y las técnicas de programación que se tratan en el capítulo ??, pueden ayudar a eliminar las restricciones a tu creatividad impuestas por el software. Por lo tanto, después de leer el libro y completar los ejercicios, deberías sentirte capacitado con una sólida comprensión de las posibilidades abiertas por las impresionantes capacidades geográficas de R, nuevas habilidades para resolver problemas del mundo real con datos geográficos, y la capacidad de comunicar tu trabajo con mapas y código reproducible.
En las últimas décadas, el software libre y de código abierto dedicado al ámbito geoespacial (FOSS4G) ha progresado a un ritmo asombroso. Gracias a organizaciones como OSGeo, el análisis de datos geográficos ha dejado de ser algo exclusivo de quienes disponen de caros hardware y software: ahora cualquiera puede descargar y ejecutar bibliotecas espaciales de alto rendimiento. Los Sistemas de Información Geográfica (SIG, o GIS en inglés) de código abierto, como QGIS, han hecho accesible el análisis geográfico en todo el mundo. Los programas SIG tienden a enfatizar las interfaces gráficas para el usuario (GUIs), con la consecuencia no deseada de desalentar la reproducibilidad (aunque muchos pueden utilizarse desde la línea de comandos, como veremos en el capítulo ??). R, por el contrario, hace énfasis en la interfaz de la línea de comandos (CLI). Una comparación simplista entre los diferentes enfoques se ilustra en la Tabla 1.1.
| Atributo | GIS para Escritorio (GUI) | R |
|---|---|---|
| Disciplinas domésticas | Geografía | Computación, Estadística |
| Enfoque en el Software | Interfaz Gráfica del Usuario | Línea de comandos |
| Reproducibilidad | Mínima | Máxima |
Este libro está motivado por la importancia de la reproducibilidad para la investigación científica (véase la nota inferior). Su objetivo es hacer más accesibles los flujos de trabajo de los análisis de datos geográficos reproducibles, y demostrar el poder del software geoespacial abierto disponible desde la línea de comandos. “Las interfaces para otros software forman parte de R” (Eddelbuettel and Balamuta 2018). Esto significa que, además de las destacadas capacidades “internas”, R permite el acceso a muchas otras bibliotecas de software espacial, explicadas en la sección @ref(Por-qué-usar-R-para-la-geocomputación) y demostradas en el capítulo ??. Sin embargo, antes de entrar en los detalles del software, vale la pena dar un paso atrás y pensar en lo que entendemos por geocomputación.
La reproducibilidad es una de las principales ventajas de las interfaces de línea de comandos, pero ¿qué significa en la práctica? La definimos del siguiente modo:“Un proceso en el que los mismos resultados pueden ser generados por otros utilizando un código públicamente accesible”.
Esto puede sonar simple y fácil de lograr ( lo cual lo es si mantienes cuidadosamente tu código R en archivos de script), pero tiene profundas implicaciones para la enseñanza y el proceso científico (Pebesma, Nüst, and Bivand 2012).1.1 ¿Qué es la geocomputación?
‘Geocomputación’ es un término joven, que se remonta a la primera conferencia sobre el tema en 1996.1
Lo que distingue la geocomputación del término comúnmente utilizado (en aquel momento) “geografía cuantitativa”, según propusieron sus primeros defensores, es su énfasis en las aplicaciones “creativas y experimentales” (P. A. Longley et al. 1998) y en el desarrollo de nuevas herramientas y métodos (Openshaw and Abrahart 2000): “La geocomputación consiste en utilizar los distintos tipos de geodatos y en desarrollar geoherramientas relevantes dentro del contexto general de un enfoque ‘científico’”. Este libro pretende ir más allá de la enseñanza de los métodos y el código; al final de él, deberías ser capaz de utilizar tus conocimientos de geocomputación para realizar “un trabajo práctico que sea beneficioso o útil” (Openshaw and Abrahart 2000).
Sin embargo, nuestro enfoque difiere de los primeros en adoptarlo, como Stan Openshaw, en su énfasis en la reproducibilidad y la colaboración. A principios del siglo XXI, no era realista esperar que los lectores pudieran reproducir los ejemplos de código, debido a las barreras que impedían el acceso al hardware, el software y los datos necesarios. Si avanzamos dos décadas, las cosas han progresado rápidamente. Cualquiera que tenga acceso a un ordenador portátil con aproximadamente 4 GB de RAM puede esperar de forma realista poder instalar y ejecutar software de geocomputación sobre conjuntos de datos de acceso público, que están más disponibles que nunca (como veremos en el capítulo ??).2 A diferencia de los primeros trabajos en este campo, todo el trabajo presentado en este libro es reproducible utilizando el código y los datos de ejemplo proporcionados junto con el libro, en paquetes de R como spData, cuya instalación se trata en el capítulo 2.
La geocomputación está estrechamente relacionada con otros términos como: Ciencia de la Información Geográfica (GIScience); Geomática; Geoinformática; Ciencia de la Información Espacial; Ingeniería de la Geoinformación (P. Longley 2015); y Ciencia de los Datos Geográficos (GDS). Todos los términos comparten el énfasis en un enfoque “científico” (que implica que es reproducible y falsable) influenciado por los SIG, aunque sus orígenes y principales campos de aplicación difieren. La GDS, por ejemplo, enfatiza las habilidades de la “ciencia de datos” y los grandes conjuntos de datos, mientras que la Geoinformática tiende a centrarse en las estructuras de datos. Pero los solapamientos entre los términos son mayores que las diferencias entre ellos y utilizamos la geocomputación como un sinónimo aproximado que los engloba a todos: todos tratan de utilizar los datos geográficos para el trabajo científico aplicado. Sin embargo, a diferencia de los primeros usuarios del término, no pretendemos dar a entender que existe un campo académico cohesionado llamado “Geocomputación” (o “GeoComputación”, como lo llamaba Stan Openshaw). En cambio, definimos el término de la siguiente manera: trabajar con datos geográficos de forma computacional, centrándose en el código, la reproducibilidad y la modularidad.
La geocomputación es un término reciente pero está influenciado por ideas antiguas. Puede considerarse parte de la Geografía, la cual tiene más de 2000 años de historia (Talbert 2014); y una extensión de los Sistemas de Información Geográfica (SIG) (Neteler and Mitasova 2008), los cuales surgieron en la década de 1960 (Coppock and Rhind 1991).
Sin embargo, la geografía ha desempeñado un papel importante a la hora de explicar e influir la relación de la humanidad con el mundo natural mucho antes de la invención del ordenador. Los viajes de Alexander von Humboldt a Sudamérica a principios del siglo XIX ilustran este papel: las observaciones resultantes no solo sentaron las bases de las tradiciones de la geografía física y vegetal, sino que también allanaron el camino hacia las políticas de protección del mundo natural (Wulf 2015). Este libro pretende contribuir a la “Tradición Geográfica” (Livingstone 1992) aprovechando la potencia de los ordenadores modernos y el software de código abierto.
Los vínculos del libro con disciplinas más antiguas se reflejaron en los títulos sugeridos para el libro: Geografía con R y R para SIG. Cada uno tiene sus ventajas. El primero transmite el mensaje de que comprende mucho más que datos espaciales: los datos de atributos no espaciales se entremezclan inevitablemente con los datos geométricos, y la Geografía trata de algo más que de dónde está algo en el mapa. El segundo comunica que este un libro sobre el uso de R como un SIG, para realizar operaciones espaciales sobre datos geográficos (Bivand, Pebesma, and Gómez-Rubio 2013). Sin embargo, el término SIG transmite algunas connotaciones (véase la Tabla 1.1) que simplemente no comunican una de las mayores fortalezas de R: su capacidad basada en la consola para cambiar sin problemas entre las tareas de procesamiento, modelado y visualización de datos geográficos y no geográficos. Por el contrario, el término geocomputación implica una programación reproducible y creativa. Por supuesto, los algoritmos (geocomputacionales) son herramientas poderosas que pueden llegar a ser altamente complejas. Sin embargo, todos los algoritmos se componen de partes más pequeñas. Al enseñarte sus fundamentos y su estructura subyacente, pretendemos capacitarte para crear tus propias soluciones innovadoras a los problemas de datos geográficos.
1.2 ¿Por qué usar R para la geocomputación?
Los primeros geógrafos utilizaron diversas herramientas, como barómetros, brújulas y sextantes, para avanzar en el conocimiento del mundo (Wulf 2015). Solo con la invención del cronómetro marino en 1761 fue posible calcular la longitud en el mar, lo que permitió a los barcos tomar rutas más directas.
Hoy en día es difícil imaginar tal falta de datos geográficos. Todos los teléfonos inteligentes tienen un receptor de posicionamiento global (GPS) y una multitud de sensores en dispositivos que van desde satélites y vehículos semiautónomos hasta científicos ciudadanos que miden incesantemente cada parte del mundo. El ritmo de producción de datos es abrumador. Un vehículo autónomo, por ejemplo, puede generar 100 GB de datos al día (The Economist 2016). Los datos de teledetección de los satélites se han vuelto demasiado grandes para analizar los datos correspondientes con un solo ordenador, lo que ha dado lugar a iniciativas como OpenEO.
Esta “revolución de los geodatos” impulsa la demanda de equipos informáticos de alto rendimiento y de software eficientes y escalables para manejar y extraer la señal del ruido, con el fin de comprender y quizás cambiar el mundo. Las bases de datos espaciales permiten almacenar y generar subconjuntos manejables de los vastos almacenes de datos geográficos, haciendo que las interfaces para obtener conocimientos de ellos sean herramientas vitales para el futuro. R es una de esas herramientas, con capacidades avanzadas de análisis, modelización y visualización. En este contexto, el libro no se centra en el lenguaje en sí (véase wickham_advanced_2014?). En su lugar, utilizamos R como una “herramienta para trabajar” para entender el mundo, de forma similar al uso que Humboldt hizo de las herramientas para obtener una comprensión profunda de la naturaleza en toda su complejidad e interconexiones (véase Wulf 2015). Aunque la programación puede parecer una actividad reduccionista, el objetivo es enseñar geocomputación con R no solo por diversión, sino para entender el mundo.
R es un lenguaje y entorno de código abierto y multiplataforma para la computación estadística y los gráficos (r-project.org/). Con una amplia gama de paquetes, R también permite la estadística geoespacial avanzada, la modelización y la visualización. Los nuevos entornos de desarrollo integrados (IDE), como RStudio, han hecho que R sea más fácil de usar para muchos, facilitando la elaboración de mapas con un panel dedicado a la visualización interactiva.
En su esencia, R es un lenguaje de programación funcional orientado a objetos (wickham_advanced_2014?), y fue diseñado específicamente como una interfaz interactiva para otro software (Chambers 2016). Este último también incluye muchos “puentes” hacia el hallazgo de un tesoro del software SIG, “geolibrerías” y funciones (véase el capítulo ??). Por tanto, es ideal para crear rápidamente “geoherramientas”, sin necesidad de dominar lenguajes de nivel inferior (en comparación con R) como C, FORTRAN o Java (véase la sección @ref(software-para-geocomputación)). Esto puede ser como liberarse del metafórico “techo de cristal” impuesto por los sistemas de información geográfica basados en GUI o patentados (véase la Tabla 1.1 para una definición de GUI). Además, R facilita el acceso a otros lenguajes: los paquetes Rcpp y reticulate permiten acceder a código de C++ y Python, por ejemplo. Esto significa que R puede utilizarse como “puente” hacia una amplia gama de programas geoespaciales (véase la sección @ref(software-para-geocomputación)).
Otro ejemplo que muestra la flexibilidad y la evolución de las capacidades geográficas de R es la elaboración de mapas interactivos. Como veremos en el Capítulo ??, la afirmación de que R tiene “facilidades interactivas [para elaborar gráficos] limitadas” (Bivand, Pebesma, and Gómez-Rubio 2013) ya no es cierta. Así lo demuestra el siguiente fragmento de código, que crea la Figura 1.1 (las funciones que generan el gráfico se tratan en la Sección ??).
library(leaflet)
popup = c("Robin", "Jakub", "Jannes", "Mireia")
leaflet() %>%
addProviderTiles("NASAGIBS.ViirsEarthAtNight2012") %>%
addMarkers(c(-3, 23, 11, 2), c(52, 53, 49, 42), popup = popup)FIGURE 1.1: Los marcadores azules indican la procedencia de los autores. El mapa base es una imagen en mosaico de la Tierra de noche proporcionada por la NASA. Interactúa con la versión en línea en geocompr.robinlovelace.net, por ejemplo, ampliando la imagen y haciendo clic en las ventanas emergentes.
Hace unos años habría sido difícil elaborar la Figura 1.1 con R, más aún en forma de mapa interactivo. Esto ilustra la flexibilidad de R y cómo, gracias a desarrollos como knitr y leaflet, puede utilizarse como interfaz con otro software, un tema que se repetirá a lo largo de este libro. El uso del código de R, por tanto, permite enseñar geocomputación con referencia a ejemplos reproducibles como el proporcionado en la Figura 1.1 en lugar de conceptos abstractos.
1.3 Software para geocomputación
R es un poderoso lenguaje para la geocomputación, pero hay muchas otras opciones para el análisis de datos geográficos que ofrecen miles de funciones geográficas. El conocimiento de otros lenguajes para la geocomputación ayudará a decidir cuándo una herramienta diferente puede ser más apropiada para una tarea específica, y a situar a R en el amplio ecosistema geoespacial. Esta sección presenta brevemente los lenguajes C++, Java y Python para la geocomputación, como preparación para el capítulo ??.
Una importante característica de R (y de Python) es que es un lenguaje interpretado. Esto es ventajoso porque permite la programación interactiva en un bucle de lectura-evaluación-impresión (REPL): el código introducido en la consola se ejecuta inmediatamente y el resultado se imprime, en lugar de esperar a la etapa intermedia de compilación. Por otra parte, los lenguajes compilados, como C++ y Java, tienden a ejecutarse más rápidamente (una vez que han sido compilados).
C++ proporciona la base de muchos paquetes SIG, como QGIS, GRASS y SAGA, por lo que es un punto de partida apropiado. El C++ bien escrito es muy rápido, lo que lo convierte en una buena opción para aplicaciones de rendimiento crítico, como el procesamiento de grandes conjuntos de datos geográficos, pero es más difícil de aprender que Python o R. El C++ se ha vuelto más accesible con el paquete Rcpp, el cual proporciona una buena ” vía de entrada ” a la programación en C para los usuarios de R. El dominio de estos lenguajes de bajo nivel abre la posibilidad de crear nuevos “geoalgoritmos” de alto rendimiento y de comprender mejor el funcionamiento del software SIG (véase el capítulo ??).
Java es otro lenguaje importante y versátil para la geocomputación. Los paquetes de SIG gvSig, OpenJump y uDig están escritos en Java. Hay muchas bibliotecas de SIG escritas en Java, como GeoTools y JTS, la Topología Suite de Java (GEOS es un puerto C++ de JTS). Además, muchas aplicaciones de servidores de mapas utilizan Java, como Geoserver/Geonode, deegree y 52°North WPS.
La sintaxis orientada a objetos de Java es similar a la de C++. Una de las principales ventajas de Java es que es independiente de las plataformas (lo que es inusual para un lenguaje compilado) y es altamente escalable, lo cual lo convierte en un lenguaje adecuado para IDEs como RStudio, con el cual se ha escrito este libro. Java tiene menos herramientas para el modelado estadístico y la visualización que Python o R, aunque puede utilizarse para la ciencia de datos (Brzustowicz 2017).
Python es un lenguaje importante para la geocomputación, especialmente porque muchos SIG de escritorio, como GRASS, SAGA y QGIS, proporcionan una API de Python (véase el capítulo ??). Al igual que R, es una herramienta popular para la ciencia de los datos. Ambos lenguajes están orientados a objetos y tienen muchas áreas de solapamiento, lo cual ha llevado a iniciativas como el paquete reticulate, que facilita el acceso a Python desde R, y la iniciativa de Ursa Labs para apoyar las bibliotecas portátiles en beneficio de todo el ecosistema de ciencia de datos de código abierto.
En la práctica, tanto R como Python tienen sus puntos fuertes y, hasta cierto punto, cuál de ellos se utiliza es menos importante que el ámbito de aplicación y la comunicación de los resultados. El aprendizaje de cualquiera de los dos permite empezar a aprender el otro. Sin embargo, R tiene grandes ventajas sobre Python para la geocomputación. Entre ellas se encuentra el hecho de que soporta mucho mejor los modelos de datos geográficos vectoriales y rasterizados en el propio lenguaje (véase el capítulo 2) y las correspondientes posibilidades de visualización (véanse los capítulos 2 y ??). Igualmente importante es el hecho de que R tiene un soporte incomparable para la estadística, incluida la estadística espacial, con cientos de paquetes (a diferencia de Python) que soportan miles de métodos estadísticos.
La mayor ventaja de Python es que es un lenguaje de programación de propósito general. Se utiliza en muchos ámbitos, como el software de escritorio, los juegos de ordenador, los sitios web y la ‘ciencia de los datos’. Python es a menudo el único lenguaje compartido entre diferentes comunidades (de geocomputación) y puede considerarse como el “pegamento” que mantiene unidos muchos programas de SIG. Se puede acceder a muchos geoalgoritmos, incluidos los de QGIS y ArcMap, desde la línea de comandos de Python, lo que lo convierte en un lenguaje idóneo para iniciarse en los SIG de línea de comandos.^[
Los módulos de Python que proporcionan acceso a los geoalgoritmos incluyen grass.script para GRASS,
saga-python para SAGA-GIS,
processing para QGIS y arcpy para ArcGIS.
]
Sin embargo, para la estadística espacial y el modelado predictivo, R es considerablemente mejor. Esto no significa que haya que elegir entre R o Python: Python soporta la mayoría de las técnicas estadísticas comunes (aunque R tiende a soportar antes los nuevos desarrollos en estadística espacial) y muchos conceptos aprendidos en Python pueden aplicarse al mundo de R. Al igual que R, Python también soporta el análisis y la manipulación de datos geográficos con paquetes como osgeo, Shapely, NumPy y PyGeoProcessing (Garrard 2016).
1.4 El ecosistema espacial de R
Hay muchas maneras de manejar datos geográficos en R, con docenas de paquetes en el área.3 En este libro nos esforzamos por enseñar el estado del arte en el campo, al tiempo que nos aseguramos de que los métodos estén preparados para el futuro. Al igual que muchas áreas de desarrollo de software, el ecosistema espacial de R está evolucionando rápidamente (Figura 1.2). Puesto que R es de código abierto, estos desarrollos pueden construirse fácilmente a partir de trabajos anteriores, “subiendo a hombros de gigantes”, como dijo Isaac Newton en 1675. Este enfoque es ventajoso porque fomenta la colaboración y evita “reinventar la rueda”. El paquete sf (tratado en el capítulo 2), por ejemplo, se basa en su predecesor sp.
El aumento del tiempo de desarrollo (y del interés) en ‘R-spatial’ se ha producido tras la concesión de una subvención por parte del R Consortium para el desarrollo del soporte para Funciones Simples, un estándar y modelo de código abierto para almacenar y acceder a geometrías vectoriales. Esto dio lugar al paquete sf (tratado en la sección 2.2.1). Múltiples sitios reflejan el inmenso interés por sf. Esto es especialmente cierto en el caso de los archivos de R-sig-Geo Archives, una lista de correos electrónicos en abierto que contiene mucha sabiduría de R-spatial acumulada a lo largo de los años.
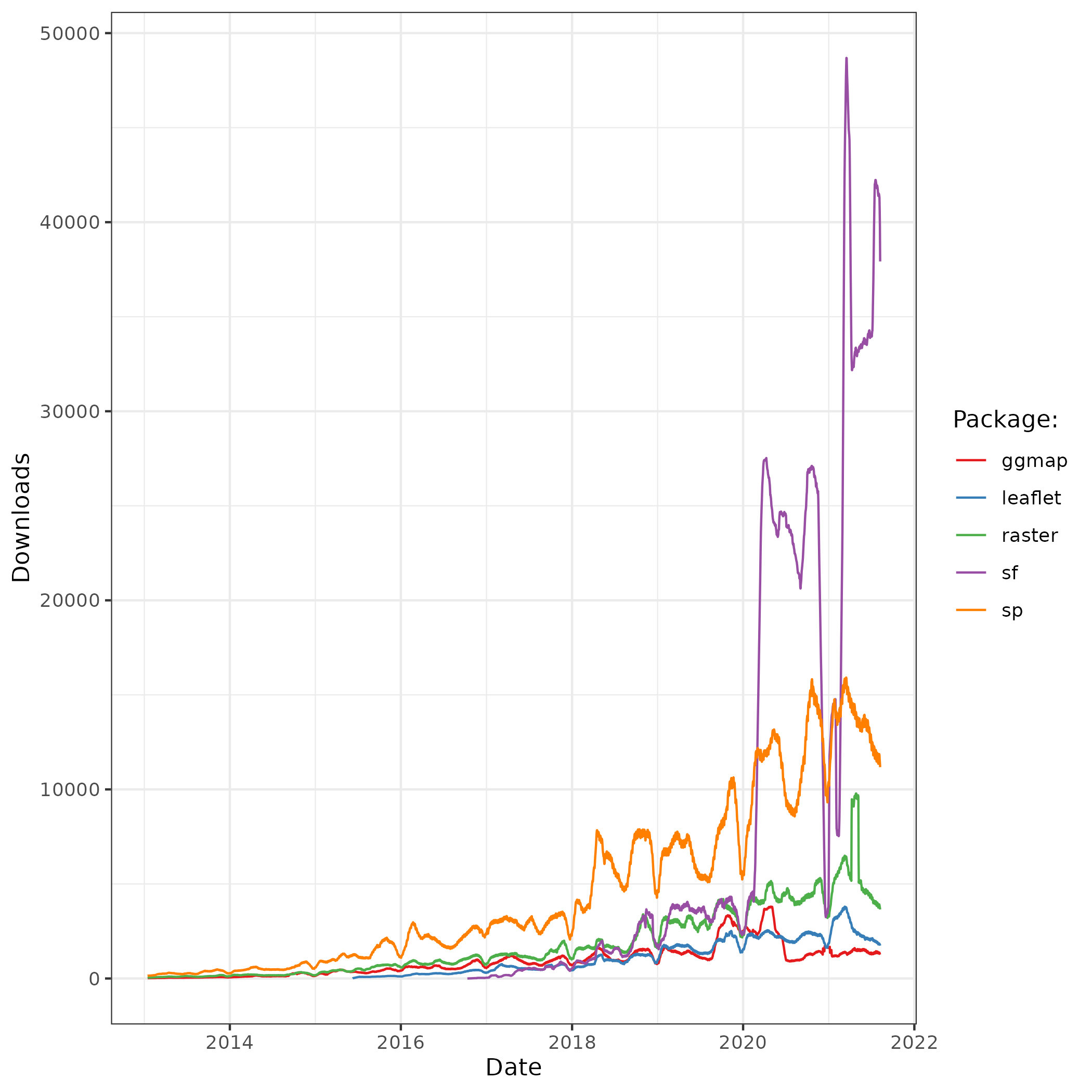
FIGURE 1.2: La popularidad de los paquetes espaciales en R. El eje Y muestra el número medio de descargas por día, dentro de una ventana móvil de 30 días, de paquetes espaciales destacados.
Cabe destacar que los cambios en la comunidad de R en general, como por ejemplo el paquete de procesamiento de datos dplyr (publicado en 2014), han influido en los cambios del ecosistema espacial de R. Junto con otros paquetes que tienen un estilo compartido y un énfasis en los “datos ordenados” (“tidy data”) (incluyendo, por ejemplo, ggplot2), dplyr se colocó en el “metapaquete” tidyverse a finales de 2016.
El enfoque de tidyverse, centrado en los datos de forma larga y en las funciones rápidas de nombre intuitivo, se ha hecho inmensamente popular. Esto ha dado lugar a una demanda de “datos geográficos ordenados” que ha sido satisfecha en parte por sf y otros enfoques como tabularaster. Una característica evidente del tidyverse es la tendencia a que los paquetes trabajen en armonía. No existe un ‘geoverso’ equivalente, pero hay intentos de armonización entre los paquetes alojados en la organización r-spatial y el número creciente de paquetes que utilizan sf (Tabla 1.2).
| Paquete | Descargas |
|---|---|
| ggplot2 | 64784 |
| jsonlite | 32271 |
| isoband | 19760 |
| plotly | 6426 |
| raster | 3732 |
1.5 La historia de R-spatial
El uso de paquetes espaciales recientes como sf tiene muchas ventajas, pero también es importante ser consciente de la historia de las capacidades espaciales de R: muchas funciones, casos de uso y material didáctico están contenidos en paquetes más antiguos. Estos pueden seguir siendo útiles hoy en día, siempre que se sepa dónde buscar.
Las capacidades espaciales de R se originaron en los primeros paquetes espaciales del lenguaje S (Bivand and Gebhardt 2000). En la década de 1990 se desarrollaron numerosos scripts en S y un puñado de paquetes para la estadística espacial. Los paquetes de R surgieron a partir de ellos y en el año 2000 había paquetes de R para varios métodos espaciales “análisis de patrones puntuales, geoestadística, análisis exploratorio de datos espaciales y econometría espacial”, según un artículo presentado en GeoComputation 2000 (Bivand and Neteler 2000). Algunos de ellos, especialmente spatial, sgeostat y splancs, siguen estando disponibles en CRAN (B. S. Rowlingson and Diggle 1993; B. Rowlingson and Diggle 2017; Venables and Ripley 2002; Majure and Gebhardt 2016).
Un artículo posterior en R News (el predecesor de The R Journal) contenía una visión general del software estadístico espacial en R en ese momento, gran parte del cual se basaba en código anterior escrito para S/S-PLUS (Ripley 2001). Esta visión general describía paquetes para el suavizado y la interpolación espacial, incluyendo akima y geoR (Akima and Gebhardt 2016; Jr and Diggle 2016), y el análisis de patrones de puntos, incluyendo splancs (B. Rowlingson and Diggle 2017) y spatstat (Baddeley, Rubak, and Turner 2015).
La siguiente publicación de R News (Volumen 1/3) volvió a poner los paquetes espaciales en el punto de mira, con una introducción más detallada a splancs y un comentario sobre las perspectivas futuras de la estadística espacial (Bivand 2001). Además, la publicación introdujo dos paquetes para probar la autocorrelación espacial que finalmente se convirtieron en parte de spdep (Bivand 2017). En particular, el comentario menciona la necesidad de estandarizar las interfaces espaciales, los mecanismos eficientes para el intercambio de datos con SIG y el manejo de metadatos espaciales como los sistemas de referencia de coordenadas (CRS).
maptools [escrito por Nicholas Lewin-Koh; Bivand and Lewin-Koh (2017)] es otro paquete importante de esta época. Inicialmente, maptools solo contenía una envoltura alrededor de shapelib y permitía la lectura de ESRI Shapefiles en listas anidadas de geometría. La clase S3 correspondiente y hoy en día obsoleta llamada “Map” almacenaba esta lista junto a un dataframe de atributos. El trabajo sobre la representación de la clase “Map” fue, sin embargo, importante, ya que alimentó directamente a sp antes de su publicación en CRAN.
En 2003, Roger Bivand publicó una revisión extendida de los paquetes espaciales. Propuso un sistema de clases para soportar los “objetos de datos ofrecidos por GDAL”, incluyendo los tipos ‘fundamentales’ punto, línea, polígono y raster. Además, sugería que las interfaces con bibliotecas externas debían ser la base de los paquetes modulares de R (Bivand 2003). En gran medida, estas ideas se materializaron en los paquetes rgdal y sp. Estos proporcionaron una base para el análisis de datos espaciales con R, tal como se describe en Análisis de datos espaciales aplicados con R (Applied Spatial Data Analysis with R en inglés) (ASDAR) (Bivand, Pebesma, and Gómez-Rubio 2013), publicado por primera vez en 2008. Diez años más tarde, las capacidades espaciales de R han evolucionado sustancialmente, pero siguen basándose en las ideas expuestas por Bivand (2003): las interfaces para GDAL y PROJ, por ejemplo, siguen potenciando las capacidades de I/O de datos geográficos de alto rendimiento y de transformación de CRS (véanse los capítulos ?? y ??, respectivamente).
rgdal, publicado en 2003, proporcionó vínculos GDAL para R que mejoraron en gran medida su capacidad para importar datos de formatos de datos geográficos que antes no estaban disponibles. La versión inicial sólo admitía controladores raster, pero las mejoras posteriores proporcionaron soporte para sistemas de referencia de coordenadas (a través de la librería PROJ), reproyecciones e importación de formatos de archivos vectoriales (véase el capítulo ?? para más información sobre los formatos de archivo). Muchas de estas capacidades adicionales fueron desarrolladas por Barry Rowlingson y publicadas en el código base de rgdal en 2006 (véase B. Rowlingson et al. 2003 y R-help(véase Rowlingson et al. 2003 y la lista de correos electrónicos de R-help para el contexto).
sp, publicado en 2005, superó la incapacidad de R para distinguir entre los objetos espaciales y los no espaciales (Pebesma and Bivand 2005).
sp surgió de un taller celebrado en Viena en 2003 y estuvo alojado en sourceforge antes de migrar a R-Forge. Antes de 2005, las coordenadas geográficas se trataban generalmente como cualquier otro número. sp cambió esto con sus clases y métodos genéricos que soportan puntos, líneas, polígonos y cuadrículas, y datos de atributos.
sp almacena información como el cuadro delimitador, el sistema de referencia de coordenadas y los atributos en ranuras de objetos espaciales que utilizan el sistema de clases S4, lo que permite que las operaciones de datos funcionen con datos geográficos (véase la sección @ref(por-qué-simple-features)).
Además, sp proporciona métodos genéricos como summary() y plot() para datos geográficos.
En la década siguiente, las clases sp se popularizaron rápidamente para los datos geográficos en R y el número de paquetes que dependían de él se incrementó de unos 20 en 2008 a más de 100 en 2013 (Bivand, Pebesma, and Gómez-Rubio 2013).
En 2018, casi 500 paquetes dependen de sp, lo que lo convierte en una parte importante del ecosistema de R. Entre los paquetes R más destacados que utilizan sp se encuentran: gstat, para geoestadística espacial y espacio-temporal; geosphere, para trigonometría esférica; y adehabitat, utilizado para el análisis de la selección de hábitat por parte de los animales (Pebesma and Graeler 2018; Calenge 2006; Hijmans 2016).
Mientras que rgdal y sp resolvían muchos problemas espaciales, R seguía careciendo de la capacidad de realizar operaciones geométricas (véase el capítulo ??).
Colin Rundel abordó este problema desarrollando rgeos, una interfaz de R para la librería de geometría en código abierto (GEOS) durante un proyecto de Google Summer of Code en 2010 (Bivand and Rundel 2018).
rgeos permitió a GEOS manipular objetos sp, con funciones como gIntersection().
Otra limitación de sp — su limitado apoyo a los datos raster — fue superada por raster, publicado por primera vez en 2010 (Hijmans 2017). Su sistema de clases y sus funciones soportan una serie de operaciones de rasterización, como se indica en la sección 2.3. Una característica clave de raster es su capacidad para trabajar con conjuntos de datos que son demasiado grandes para caber en la memoria RAM (la interfaz de R con PostGIS admite operaciones fuera del disco sobre datos geográficos vectoriales). raster también admite el álgebra de mapas (véase la sección ??).
Paralelamente a estos desarrollos de sistemas de clases y métodos, llegó el apoyo a R como interfaz para el software SIG dedicado. GRASS (Bivand 2000) y los paquetes posteriores spgrass6 y rgrass7 (para GRASS GIS 6 y 7, respectivamente) fueron ejemplos destacados en esta dirección (Bivand 2016a, 2016b). Otros ejemplos de puentes entre R y SIG son RSAGA (Brenning, Bangs, and Becker 2018, publicado por primera vez en 2008), RPyGeo (Brenning 2012, publicado por primera vez en 2008) y RQGIS (Muenchow, Schratz, and Brenning 2017, publicado por primera vez en 2016) (véase el capítulo ??).
La visualización no fue un foco de atención al principio, ya que la mayor parte del desarrollo de R-spatial se centró en el análisis y las operaciones geográficas.
sp proporcionó métodos para la elaboración de mapas utilizando el sistema de graficación de base y de lattice, pero la demanda estaba creciendo para las capacidades de elaboración de mapas avanzados, especialmente después del lanzamiento de ggplot2 en 2007.
ggmap amplió las capacidades espaciales de ggplot2 (Kahle and Wickham 2013), facilitando el acceso a los segmentos del “basemap” desde servicios en línea como Google Maps.
Aunque ggmap facilitaba la elaboración de mapas con ggplot2, su utilidad estaba limitada por la necesidad de fortificar los objetos espaciales, lo que significa convertirlos en largos dataframes.
Aunque esto funciona bien para los puntos, es computacionalmente ineficiente para las líneas y los polígonos, ya que cada coordenada (vértice) se convierte en una fila, lo que da lugar a enormes dataframes para representar geometrías complejas.
Aunque la visualización geográfica tendía a centrarse en los datos vectoriales, la visualización rasterizada está soportada en raster y recibió un impulso con el lanzamiento de rasterVis, el cual se describe en un libro sobre el tema de la visualización de datos espaciales y temporales (Lamigueiro 2018).
A partir de 2018, la creación de mapas en R es un tema candente con paquetes dedicados como tmap, leaflet y mapview, todos ellos compatibles con el sistema de clases proporcionado por sf, en el cual se centra el siguiente capítulo (véase el capítulo ?? para obtener más información sobre la visualización).