5 Opèrations géométriques
5.1 Introduction
Jusqu’à présent, ce livre a abordé la structure des jeux de données géographiques (chapitre 2), et la manière de les manipuler en fonction de leurs attributs non géographiques (chapitre 3) et de leurs relations spatiales (chapitre 4).
Ce chapitre se concentre sur la manipulation des éléments géographiques des objets géographiques, par exemple en simplifiant et en convertissant les géométries vectorielles, en recadrant les rasters et en convertissant les objets vectoriels en rasters et les rasters en vecteurs.
Après l’avoir lu — et avoir fait les exercices à la fin — vous devriez comprendre et contrôler la colonne géométrique des objets sf ainsi que l’étendue et l’emplacement géographique des pixels représentés dans les rasters par rapport à d’autres objets géographiques.
La section 5.2 couvre la transformation des géométries vectorielles avec des opérations “unaires” (ou fonction avec un argument) et “binaires” (fonction avec plus d’un argument). Les opérations unaires portent sur une seule géométrie de manière isolée, notamment la simplification (de lignes et de polygones), la création de tampons et de centroïdes, et le déplacement/la mise à l’échelle/la rotation de géométries uniques à l’aide de ” transformations affines ” (sections 5.2.1 à @ref(transformations affines)). Les transformations binaires modifient une géométrie en fonction de la forme d’une autre, y compris l’écrêtage et les unions géométriques (), traités respectivement dans les sections @ref(écrêtage) et @ref(unions géométriques). Les transformations de type (d’un polygone à une ligne, par exemple) sont présentées dans la section 5.2.8.
La section 5.3 couvre les transformations géométriques sur les objets rasters. Il s’agit de modifier la taille et le nombre des pixels, et de leur attribuer de nouvelles valeurs. Elle enseigne comment modifier la résolution (également appelée agrégation et désagrégation), l’étendue et l’origine d’un objet matriciel. Ces opérations sont particulièrement utiles si l’on souhaite aligner des rasters provenant de sources diverses. Les objets rasters alignés partagent une correspondance biunivoque entre les pixels, ce qui permet de les traiter à l’aide d’opérations d’algèbre raster, décrites dans la section ??. L’interaction entre les objets raster et vectoriels est traitée au chapitre 6. Elle montre comment les valeurs matricielles peuvent être “masquées” et “extraites” par des géométries vectorielles. Il est important de noter qu’elle montre comment ” polygoniser ” les données raster et ” rastériser ” les veceurs, ce qui rend les deux modèles de données plus interchangeables.
5.2 Opérations géométriques sur les données vectorielles
Cette section traite des opérations qui, d’une manière ou d’une autre, modifient la géométrie des objets vectoriels (sf).
Elle est plus avancée que les opérations sur les données spatiales présentées dans le chapitre précédent (dans la section 4.2), parce qu’ici nous allons plus loin dans la géométrie :
les fonctions présentées dans cette section fonctionnent sur les objets de la classe sfc en plus des objets de la classe sf.
5.2.1 Simplification
La simplification est un processus de généralisation des objets vectoriels (lignes et polygones) généralement destiné à être utilisé dans des cartes à plus petite échelle.
Une autre raison de simplifier les objets est de réduire la quantité de mémoire, d’espace disque et de bande passante qu’ils consomment :
il peut être judicieux de simplifier des géométries complexes avant de les publier sous forme de cartes interactives.
Le paquet sf fournit st_simplify(), qui utilise l’implémentation GEOS de l’algorithme de Douglas-Peucker pour réduire le nombre de sommets.
st_simplify() utilise la dTolerance pour contrôler le niveau de généralisation des unités de la carte (voir Douglas and Peucker 1973 pour plus de détails).
La figure 5.1 illustre la simplification d’une géométrie LINESTRING représentant la Seine et ses affluents.
La géométrie simplifiée a été créée par la commande suivante :
seine_simp = st_simplify(seine, dTolerance = 2000) # 2000 m
FIGURE 5.1: Comparaison de la géométrie originale et simplifiée de la Seine.
L’objet seine_simp résultant est une copie de l’objet original seine mais avec moins de vertices.
Le résultat étant visuellement plus simple (Figure 5.1, à droite) et consommant moins de mémoire que l’objet original, comme vérifié ci-dessous :
object.size(seine)
#> 18096 bytes
object.size(seine_simp)
#> 9112 bytesLa simplification est également applicable aux polygones.
Ceci est illustré par l’utilisation de us_states, représentant les États-Unis contigus.
Comme nous le montrons dans le chapitre 7, GEOS suppose que les données sont dans un CRS projeté et cela pourrait conduire à des résultats inattendus lors de l’utilisation d’un CRS géographique.
Par conséquent, la première étape consiste à projeter les données dans un CRS projeté adéquat, tel que le US National Atlas Equal Area (epsg = 2163) (à gauche sur la figure 5.2) :
us_states2163 = st_transform(us_states, "EPSG:2163")
us_states2163 = us_states2163st_simplify() works equally well with projected polygons:
us_states_simp1 = st_simplify(us_states2163, dTolerance = 100000) # 100 kmUne limitation de st_simplify() est qu’il simplifie les objets sur une base géométrique.
Cela signifie que la “topologie” est perdue, ce qui donne lieu à des polygones se superposant ou séparés par des vides, comme le montre la figure 5.2 (panneau du milieu).
ms_simplify() de rmapshaper fournit une alternative qui surmonte ce problème.
Par défaut, il utilise l’algorithme de Visvalingam, qui surmonte certaines limitations de l’algorithme de Douglas-Peucker (Visvalingam and Whyatt 1993).
L’extrait de code suivant utilise cette fonction pour simplifier us_states2163.
Le résultat n’a que 1% des sommets de l’entrée (fixée à l’aide de l’argument keep) mais son nombre d’objets reste intact car nous avons fixé keep_shapes = TRUE :21
# proportion des points à garder (0-1; par defaut 0.05)
us_states_simp2 = rmapshaper::ms_simplify(us_states2163, keep = 0.01,
keep_shapes = TRUE)Une alternative à la simplification est le lissage des limites des géométries des polygones et des linéaires (linestring). Elle est implémenté dans le package smoothr.
Le lissage interpole les arêtes des géométries et n’entraîne pas nécessairement une réduction du nombre de sommets, mais il peut être particulièrement utile lorsque l’on travaille avec des géométries qui résultent de la vectorisation spatiale d’un raster (un sujet traité dans le chapitre 6.
smoothr implémente trois techniques de lissage : une régression à noyau gaussien, l’algorithme de découpage en coins de Chaikin et l’interpolation par splines, qui sont tous décrits dans la vignette du paquetage et dans website.
Notez que, comme pour st_simplify(), les algorithmes de lissage ne préservent pas la ‘topologie’.
La fonction phare de smoothr est smooth(), où l’argument method spécifie la technique de lissage à utiliser.
Vous trouverez ci-dessous un exemple d’utilisation de la régression à noyau gaussien pour lisser les frontières des états américains en utilisant method=ksmooth.
L’argument smoothness contrôle la largeur de bande de la gaussienne qui est utilisée pour lisser la géométrie et a une valeur par défaut de 1.
us_states_simp3 = smoothr::smooth(us_states2163, method = 'ksmooth', smoothness = 6)Enfin, la comparaison visuelle de l’ensemble de données originales et des deux versions simplifiées montre des différences entre les sorties des algorithmes de Douglas-Peucker (st_simplify), de Visvalingam (ms_simplify) et de régression à noyau gaussien (smooth(method=ksmooth)) (Figure 5.2) :
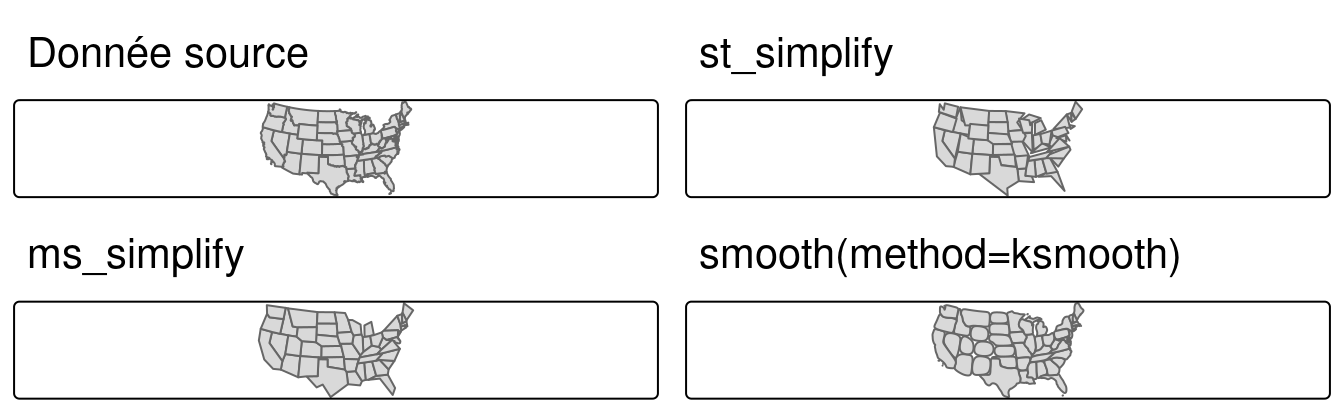
FIGURE 5.2: Simplification des polygones, comparant la géométrie originale des États-Unis continentaux avec des versions simplifiées, générées avec les fonctions des paquets sf (haut à droite) et rmapshaper (bas à gauche) et smoothr (bas à droite).
5.2.2 Centroïdes
Les opérations de centroïdes identifient le centre des objets géographiques. Comme pour les mesures statistiques de tendance centrale (y compris les définitions de la moyenne et de la médiane), il existe de nombreuses façons de définir le centre géographique d’un objet. Toutes créent des représentations par un point unique d’objets vectoriels plus complexes.
Le centroïde géographique est sans doute l’opération la plus couramment utilisée.
Ce type d’opération (souvent jute appelé “centroïde”) représente le centre de masse d’un objet spatial (pensez à une assiette en équilibre sur votre doigt).
Les centroïdes géographiques ont de nombreuses utilisations, par exemple pour créer une représentation ponctuelle simple de géométries complexes, ou pour estimer les distances entre polygones.
Ils peuvent être calculés à l’aide de la fonction sf st_centroid(), comme le montre le code ci-dessous, qui génère les centroïdes géographiques de régions de Nouvelle-Zélande et d’affluents de la Seine, illustrés par des points noirs sur la figure 5.3.
nz_centroid = st_centroid(nz)
seine_centroid = st_centroid(seine)Parfois, le centroïde géographique se trouve en dehors des limites de l’objet parent (pensez à un beignet).
Dans ce cas, les opérations dites de point sur la surface peuvent être utilisées pour garantir que le point se trouvera dans l’objet parent (par exemple, pour étiqueter des objets de type multipolygones irréguliers tels que des îles), comme l’illustrent les points rouges de la figure 5.3.
Remarquez que ces points rouges se trouvent toujours sur leurs objets parents.
Ils ont été créés avec st_point_on_surface() comme suit :22
nz_pos = st_point_on_surface(nz)
seine_pos = st_point_on_surface(seine)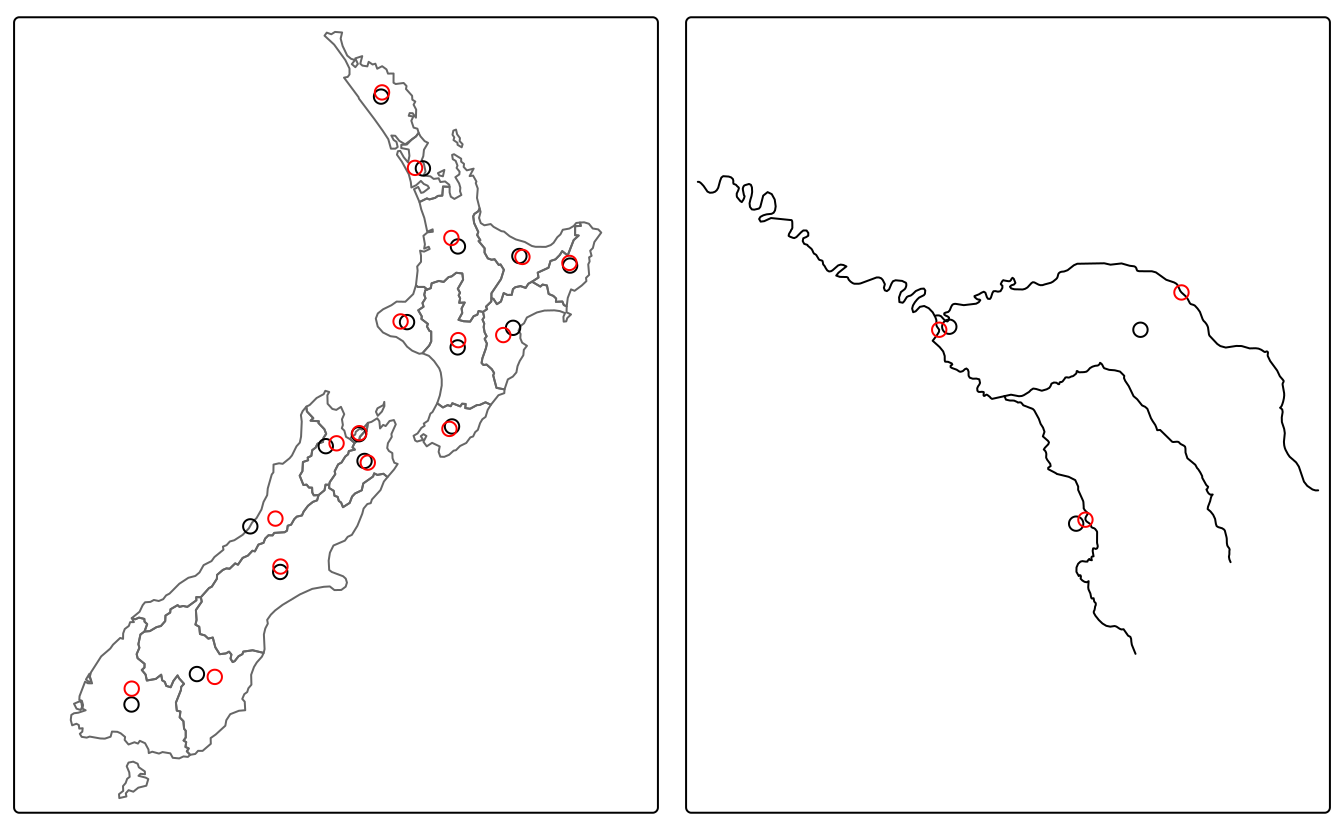
FIGURE 5.3: Centroïdes (points noirs) et points sur la surface (points rouges) des ensembles de données des régions de Nouvelle-Zélande (à gauche) et de la Seine (à droite).
Il existe d’autres types de centroïdes, notamment le centre de Chebyshev et le centre visuel. Nous ne les explorerons pas ici, mais il est possible de les calculer à l’aide de R, comme nous le verrons dans le chapitre ??.
5.2.3 Buffers/tampons
Les buffers ou tampons sont des polygones représentant la zone située à une distance donnée d’une caractéristique géométrique : Que le type d’origine soit un point, une ligne ou un polygone, la sortie est toujours un polygone. Contrairement à la simplification (qui est souvent utilisée pour la visualisation et la réduction de la taille des fichiers), la mise en mémoire tampon est généralement utilisée pour l’analyse des données géographiques. Combien de points se trouvent à une distance donnée de cette ligne ? Quels groupes démographiques se trouvent à une distance de déplacement de ce nouveau magasin ? Il est possible de répondre à ce genre de questions et de les visualiser en créant des tampons autour des entités géographiques d’intérêt.
La figure 5.4 illustre des buffers de différentes tailles (5 et 50 km) entourant la Seine et ses affluents.
Les commandes ci-dessous, utilisées pour créer ces buffers, montrent que la commande st_buffer() nécessite au moins deux arguments : une géométrie d’entrée et une distance, fournie dans les unités du SRC (dans ce cas, les mètres) :
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.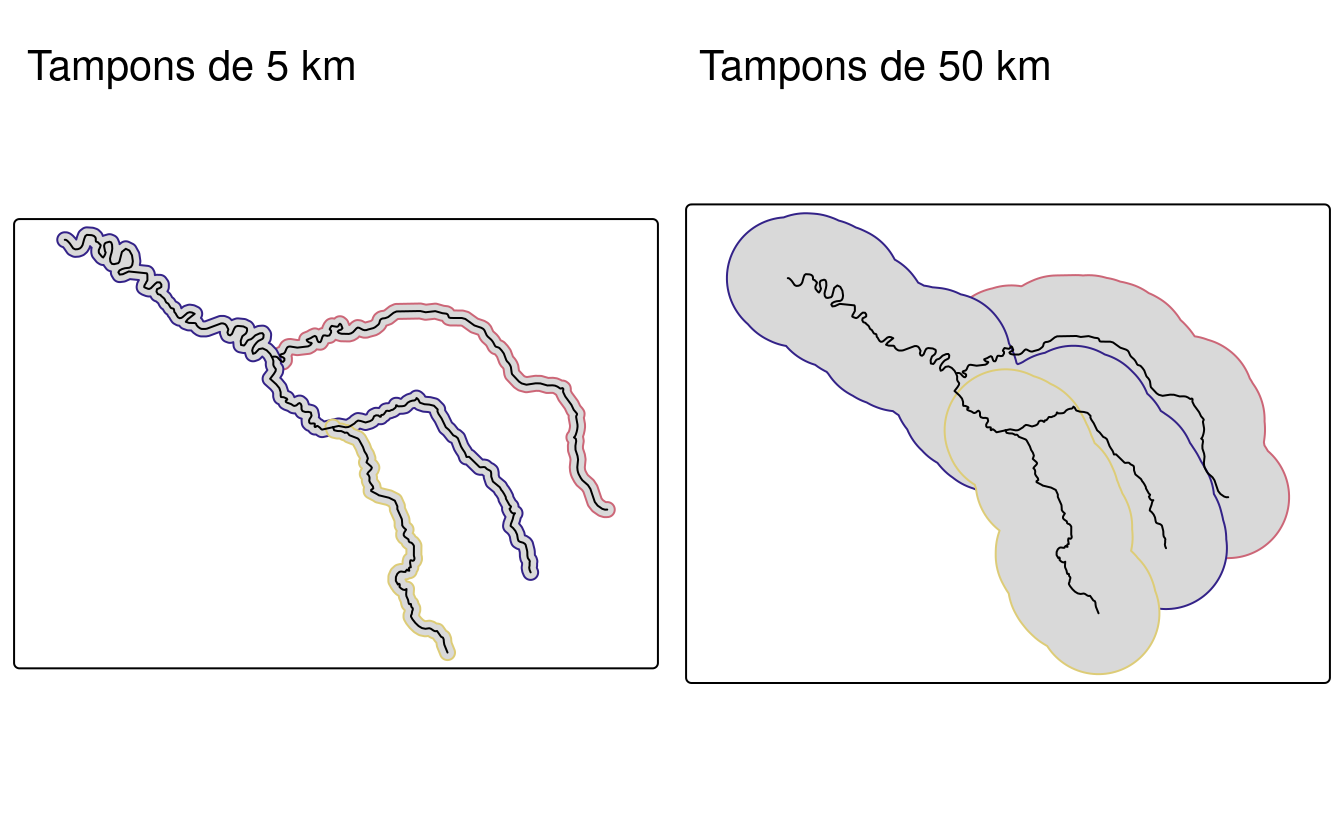
FIGURE 5.4: Tampons de 5 km autour du jeu de données de la Seine (à gauche) et de 50 km (à droite). Notez les couleurs, qui reflètent le fait qu’un tampon est créé par élément géométrique.
st_buffer() est nQuadSegs, qui signifie ‘nombre de segments par quadrant’ et qui est fixé par défaut à 30 (ce qui signifie que les cercles créés par les buffers sont composés de \(4 \times 30 = 120\) lignes).
Cet argument a rarement besoin d´être défini.
Les cas inhabituels où il peut être utile incluent lorsque la mémoire consommée par la sortie d´une opération de tampon est une préoccupation majeure (dans ce cas, il devrait être réduit) ou lorsque la très haute précision est nécessaire (dans ce cas, il devrait être augmenté).
5.2.4 Application affine
Une application affine est une transformation qui préserve les lignes et le parallélisme.
Cependant, les angles ou la longueur ne sont pas nécessairement préservés.
Les transformations affines comprennent, entre autres, le déplacement (translation), la mise à l’échelle et la rotation.
En outre, il est possible d’utiliser n’importe quelle combinaison de celles-ci.
Les applications affines sont une partie essentielle de la géocomputation.
Par exemple, le décalage est nécessaire pour le placement d’étiquettes, la mise à l’échelle est utilisée dans les cartogrammes de zones non contiguës (voir la section ??), et de nombreuses transformations affines sont appliquées lors de la reprojection ou de l’amélioration de la géométrie créée à partir d’une carte déformée ou mal projetée.
Le paquet sf implémente la transformation affine pour les objets des classes sfg et sfc.
nz_sfc = st_geometry(nz)Le décalage déplace chaque point de la même distance en unités cartographiques. Cela peut être fait en ajoutant un vecteur numérique à un objet vectoriel. Par exemple, le code ci-dessous déplace toutes les coordonnées y de 100 000 mètres vers le nord, mais laisse les coordonnées x intactes (panneau gauche de la figure 5.5).
nz_shift = nz_sfc + c(0, 100000)La mise à l’échelle agrandit ou rétrécit les objets par un facteur.
Elle peut être appliquée de manière globale ou locale.
La mise à l’échelle globale augmente ou diminue toutes les valeurs des coordonnées par rapport aux coordonnées d’origine, tout en gardant intactes les relations topologiques de toutes les géométries.
Elle peut être effectuée par soustraction ou multiplication d’un objet sfg ou sfc.
Le changement à l’échelle locale traite les géométries indépendamment et nécessite des points autour desquels les géométries vont être mises à l’échelle, par exemple des centroïdes.
Dans l’exemple ci-dessous, chaque géométrie est réduite d’un facteur deux autour des centroïdes (panneau central de la figure 5.5).
Pour cela, chaque objet est d’abord décalé de manière à ce que son centre ait les coordonnées 0, 0 ((nz_sfc - nz_centroid_sfc)).
Ensuite, les tailles des géométries sont réduites de moitié (* 0.5).
Enfin, le centroïde de chaque objet est ramené aux coordonnées des données d’entrée (+ nz_centroid_sfc).
nz_centroid_sfc = st_centroid(nz_sfc)
nz_scale = (nz_sfc - nz_centroid_sfc) * 0.5 + nz_centroid_sfcLa rotation de coordonnées bidimensionnelles nécessite une matrice de rotation :
\[ R = \begin{bmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \\ \end{bmatrix} \]
Elle fait tourner les points dans le sens des aiguilles d’une montre. La matrice de rotation peut être implémentée dans R comme suit :
rotation = function(a){
r = a * pi / 180 #degrées en radians
matrix(c(cos(r), sin(r), -sin(r), cos(r)), nrow = 2, ncol = 2)
} La fonction rotation accepte un argument a - un angle de rotation en degrés.
La rotation peut être effectuée autour de points sélectionnés, comme les centroïdes (panneau de droite de la figure 5.5).
Voir vignette("sf3") pour plus d’exemples.
nz_rotate = (nz_sfc - nz_centroid_sfc) * rotation(30) + nz_centroid_sfc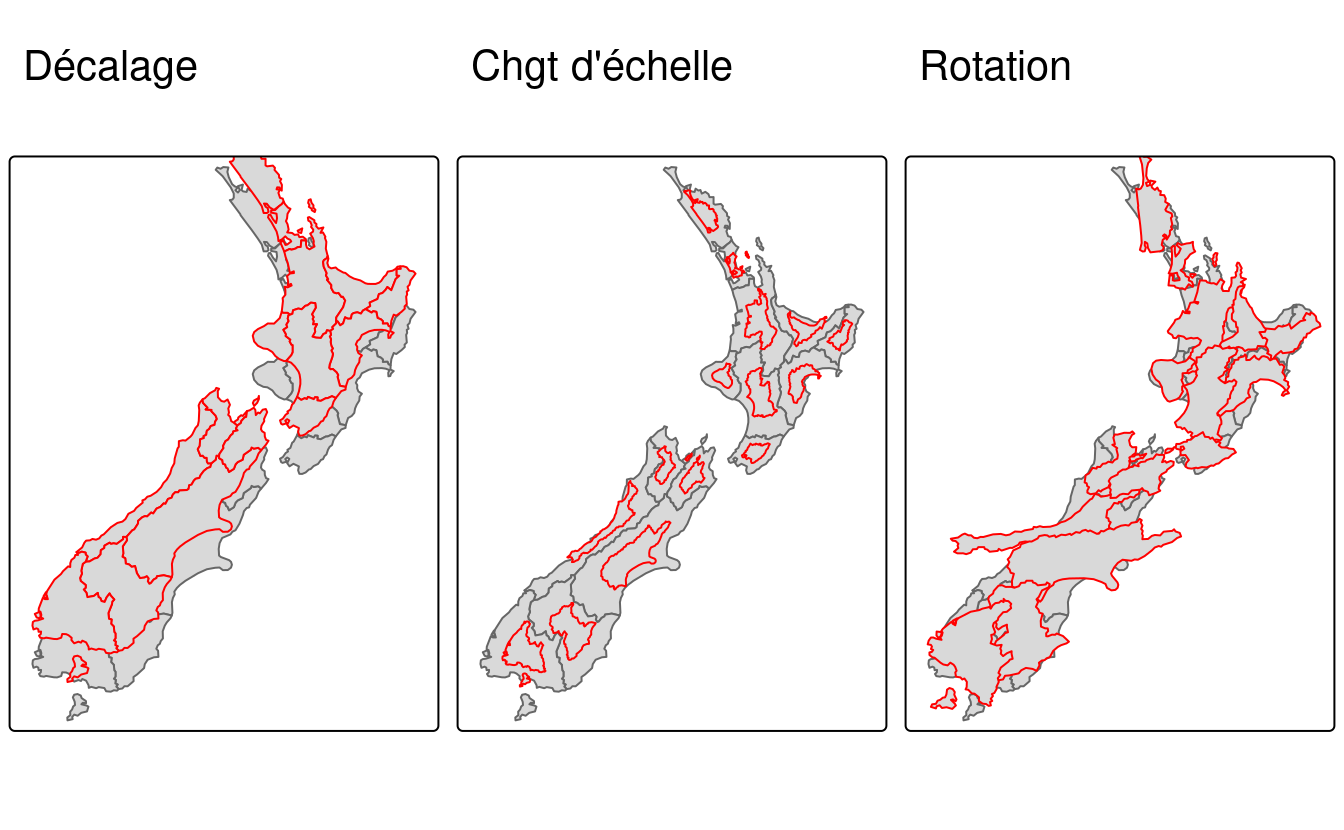
FIGURE 5.5: Illustrations des transformations affines : décalage, échelle et rotation.
Enfin, les géométries nouvellement créées peuvent remplacer les anciennes avec la fonction st_set_geometry() :
nz_scale_sf = st_set_geometry(nz, nz_scale)5.2.5 Découper
Le découpage spatial est une forme de sélection spatiale qui implique des changements dans les colonnes géométriques d’au moins certaines des entités affectées.
Le découpage ne peut s’appliquer qu’à des éléments plus complexes que des points : les lignes, les polygones et leurs équivalents “multi”. Pour illustrer le concept, nous allons commencer par un exemple simple : deux cercles superposés dont le point central est distant d’une unité et dont le rayon est de un (Figure 5.6).
b = st_sfc(st_point(c(0, 1)), st_point(c(1, 1))) # créer 2 points
b = st_buffer(b, dist = 1) # convertir les points en cercles
plot(b, border = "grey")
text(x = c(-0.5, 1.5), y = 1, labels = c("x", "y"), cex = 3) # ajout du texte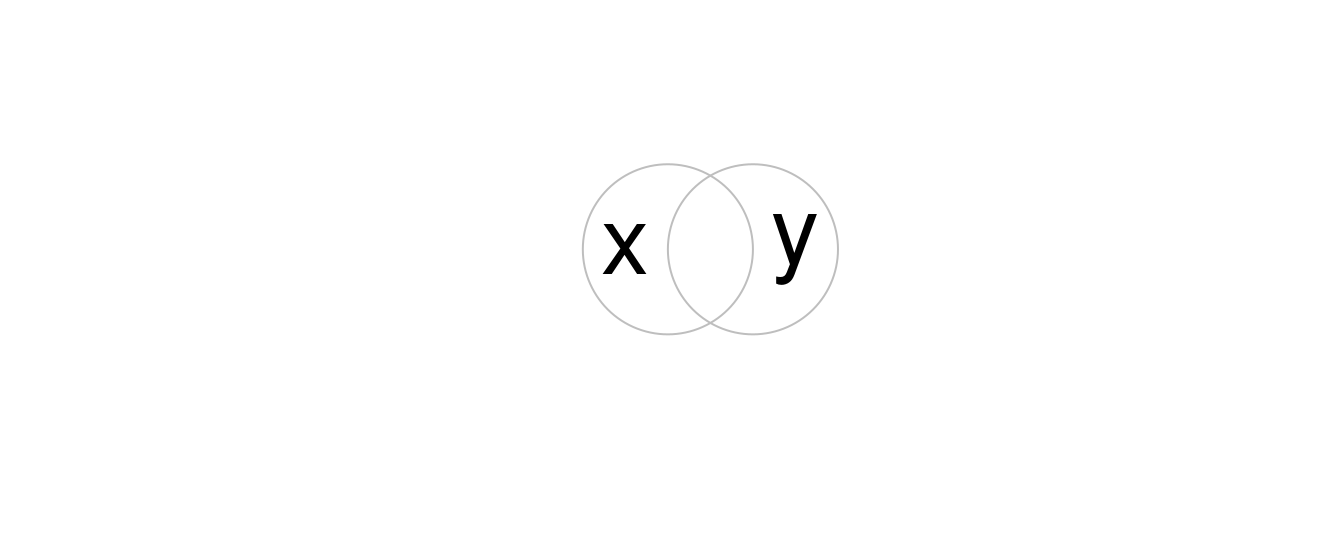
FIGURE 5.6: cercles superposés.
Imaginez que vous voulez sélectionner non pas un cercle ou l’autre, mais l’espace couvert par les deux x et y.
Cela peut être fait en utilisant la fonction st_intersection(), illustrée en utilisant des objets nommés x et y qui représentent les cercles de gauche et de droite (Figure 5.7).
x = b[1]
y = b[2]
x_and_y = st_intersection(x, y)
plot(b, border = "grey")
plot(x_and_y, col = "lightgrey", border = "grey", add = TRUE) # surface intersectée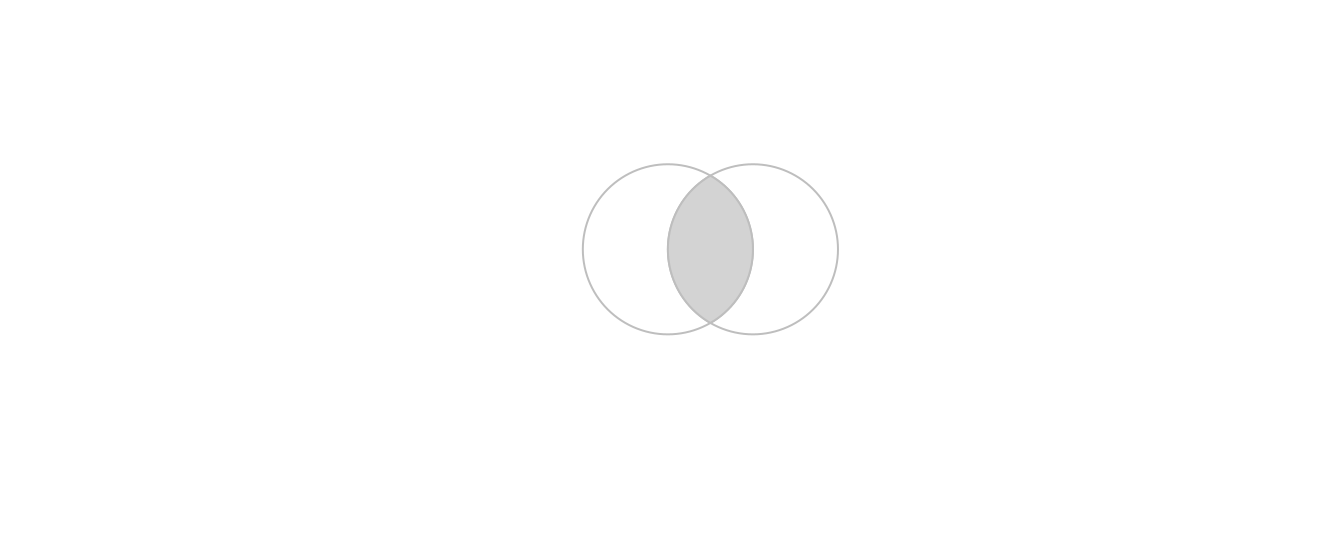
FIGURE 5.7: Cercles superposés avec une couleur grise pour indiquer l’intersection entre eux
Le passage de code suivant montre comment cela fonctionne pour toutes les combinaisons du diagramme de Venn représentant x et y, inspiré de la Figure 5.1 du livre R for Data Science (Grolemund and Wickham 2016).
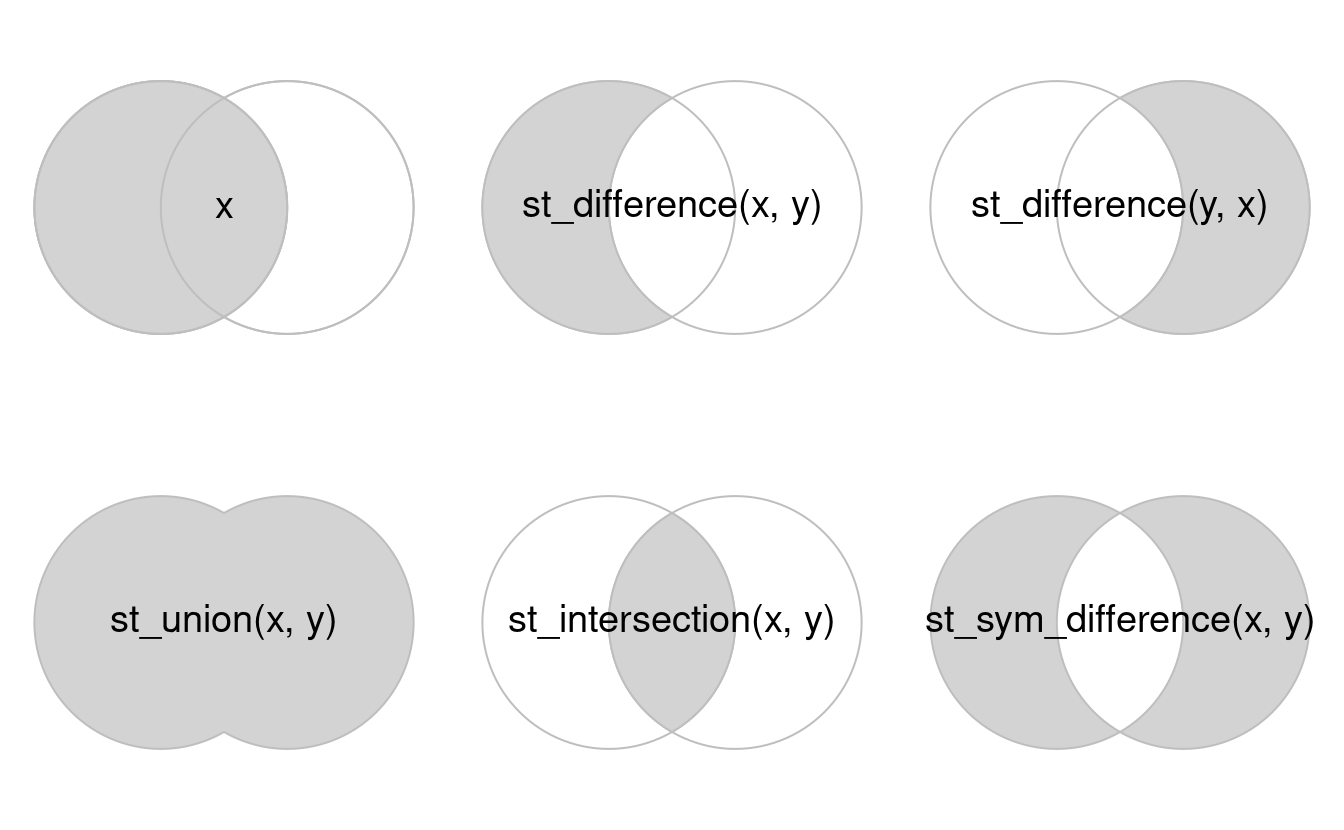
FIGURE 5.8: Équivalents spatiaux des opérateurs logiques.
5.2.6 Sélection et découpage
Le découpage d’objets peut modifier leur géométrie, mais il peut également sélectionner des objets, en ne renvoyant que les entités qui intersectent (ou intersectent partiellement) un objet de découpage/sélection.
Pour illustrer ce point, nous allons sélectionner les points qui incluent dans le cadre englobant (bounding box) des cercles x et y de la figure 5.8.
Certains points seront à l’intérieur d’un seul cercle, d’autres à l’intérieur des deux et d’autres encore à l’intérieur d’aucun.
st_sample() est utilisé ci-dessous pour générer une distribution simple et aléatoire de points à l’intérieur de l’étendue des cercles x et y, ce qui donne le résultat illustré dans la Figure 5.9, ce qui soulève la question suivante : comment sous-ensembler les points pour ne renvoyer que le point qui intersecte à la fois x et y ?
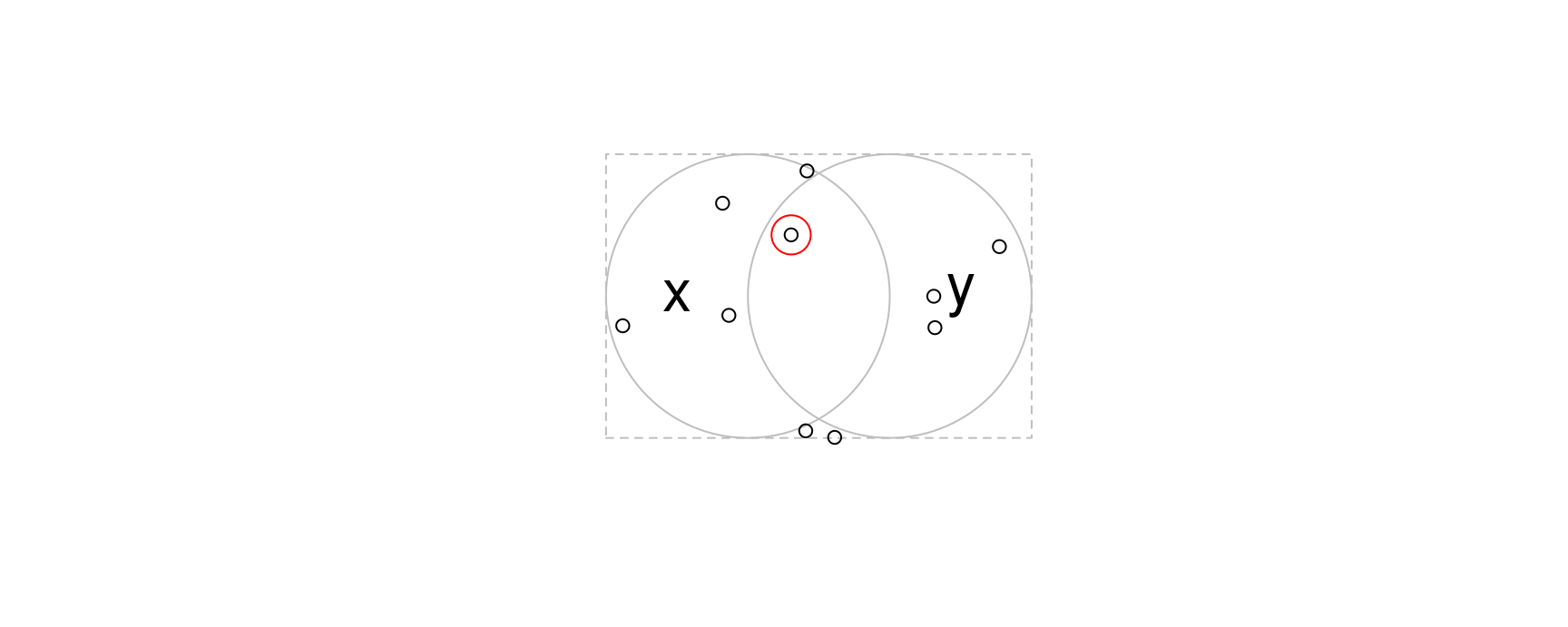
FIGURE 5.9: Points distribués de manière aléatoire dans le cadre englobant les cercles x et y. Les points qui croisent les deux objets x et y sont mis en évidence.
bb = st_bbox(st_union(x, y))
box = st_as_sfc(bb)
set.seed(2017)
p = st_sample(x = box, size = 10)
x_and_y = st_intersection(x, y)Le code ci-dessous montre trois façons d’obtenir le même résultat.
Nous pouvons utiliser directement l’intersection index{vecteur!intersection} dexety(représentée parx_et_ydans l'extrait de code précédent) comme objet de sélection, comme le montre la première ligne du morceau de code ci-dessous. Nous pouvons également trouver l'intersection entre les points d'entrée représentés parpet l'objet de sélection et de découpagex_et_y, comme le montre la deuxième ligne du code ci-dessous. Cette deuxième approche renvoie les entités qui ont une intersection partielle avecx_and_ymais avec des géométries modifiées pour les entités dont les surfaces recoupent celle de l'objet de sélection. La troisième approche consiste à créer un objet de sélection en utilisant le prédicat spatial binairest_intersects()`, introduit dans le chapitre précédent.
Les résultats sont identiques (à l’exception de différences superficielles dans les noms d’attributs), mais l’implémentation diffère substantiellement :
p_xy1 = p[x_and_y]
p_xy2 = st_intersection(p, x_and_y)
sel_p_xy = st_intersects(p, x, sparse = FALSE)[, 1] &
st_intersects(p, y, sparse = FALSE)[, 1]
p_xy3 = p[sel_p_xy]Bien que l’exemple ci-dessus soit plutôt trivial et fourni à des fins éducatives plutôt qu’appliquées, et que nous encouragions le lecteur à reproduire les résultats pour approfondir sa compréhension de la manipulation des objets vectoriels géographiques dans R, il soulève une question importante : quelle implémentation utiliser ? En général, les implémentations les plus concises doivent être privilégiées, ce qui signifie la première approche ci-dessus. Nous reviendrons sur la question du choix entre différentes implémentations d’une même technique ou d’un même algorithme au chapitre ??.
5.2.7 GUnions de géométries
Comme nous l’avons vu dans la section ??, l’agrégation spatiale peut dissoudre silencieusement les géométries des polygones se touchant dans le même groupe.
Cela est démontré dans le code ci-dessous dans lequel 49 us_states sont agrégés en 4 régions à l’aide des fonctions de R base et du tidyverse (voir les résultats dans la figure 5.10) :
regions = aggregate(x = us_states[, "total_pop_15"], by = list(us_states$REGION),
FUN = sum, na.rm = TRUE)
regions2 = us_states |>
group_by(REGION) |>
summarize(pop = sum(total_pop_15, na.rm = TRUE))#> [plot mode] fit legend/component: Some legend items or map compoments do not fit well, and are therefore rescaled. Set the tmap option 'component.autoscale' to FALSE to disable rescaling.
FIGURE 5.10: Agrégation spatiale sur des polygones contigus, illustrée par l’agrégation de la population des États américains en régions, la population étant représentée par une couleur. Notez que l’opération dissout automatiquement les frontières entre les états.
Que se passe-t-il au niveau des géométries ?
En coulisses, aggregate() et summarize() combinent les géométries et dissolvent les frontières entre elles en utilisant st_union().
Ceci est démontré par le code ci-dessous qui crée une union des Etats-Unis de l’Ouest :
us_west = us_states[us_states$REGION == "West", ]
us_west_union = st_union(us_west)La fonction peut prendre deux géométries et les unir, comme le montre ll code ci-dessous qui crée un bloc occidental uni incorporant le Texas (défi : reproduire et représenter le résultat) :
texas = us_states[us_states$NAME == "Texas", ]
texas_union = st_union(us_west_union, texas)5.2.8 Transformations de type
La transformation d’un type de géométrie en un autre (casting) est une opération puissante.
Elle est implémentée dans la fonction st_cast() du package sf.
Il est important de noter que la fonction st_cast() se comporte différemment selon qu’il s’agit d’un objet géométrique simple (sfg), d’une entité avec une colonne géométrique simple (sfc) ou d’un objet entité simple.
Créons un multipoint pour illustrer le fonctionnement des transformations de type géométrique sur des objets de géométrie simple (sfg) :
multipoint = st_multipoint(matrix(c(1, 3, 5, 1, 3, 1), ncol = 2))Dans ce cas, st_cast() peut être utile pour transformer le nouvel objet en linestring (linéaire) ou en polygone (Figure 5.11) :
#> -- tmap v3 code detected --
#> [v3->v4] polygons(): use 'fill' for the fill color of polygons/symbols (instead of 'col'), and 'col' for the outlines (instead of 'border.col')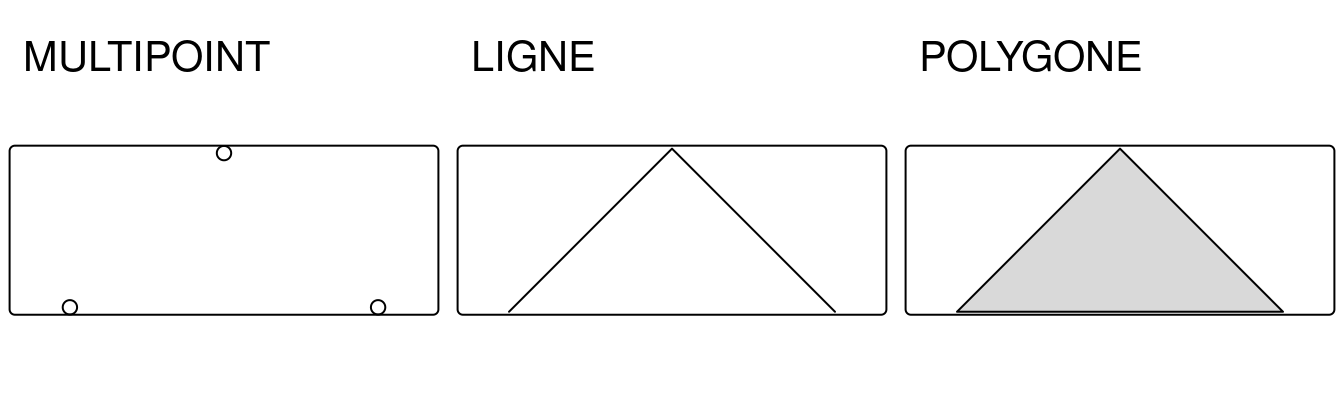
FIGURE 5.11: Exemples de lignes et de polygones créés à partir d’une géométrie multipoint
La conversion de multipoint en ligne est une opération courante qui crée un objet ligne à partir d’observations ponctuelles ordonnées, telles que des mesures GPS ou des sources géolocalisés. Cela permet d’effectuer des opérations spatiales telles que la longueur du chemin parcouru. La conversion de multipoint ou de linestring en polygone est souvent utilisée pour calculer une surface, par exemple à partir de l’ensemble des mesures GPS prises autour d’un lac ou des coins d’un terrain à bâtir.
Le processus de transformation peut également être inversé en utilisant st_cast() :
multipoint_2 = st_cast(linestring, "MULTIPOINT")
multipoint_3 = st_cast(polyg, "MULTIPOINT")
all.equal(multipoint, multipoint_2)
#> [1] TRUE
all.equal(multipoint, multipoint_3)
#> [1] TRUEsfg), st_cast permet également de transformer des géométries de non-multi-types vers des multi-types (par exemple, POINT vers MULTIPOINT) et de multi-types vers des non-multi-types.
Toutefois, dans le deuxième groupe de cas, seul le premier élément de l´ancien objet est conservé.
La transformation en différent types géométrique des d’entités de type simple colonne (sfc) et des objets d’entités simples fonctionnent de la même manière que pour les entités de géométries simples (sfg) dans la plupart des cas.
Une différence importante est la conversion des multi-types en non-multi-types.
À la suite de ce processus, les multi-objets, sf ou sfg sont divisés en plusieurs non-multi-objets.
Le tableau 5.1 montre les transformations de type géométrique possibles sur les objets d’entités simples.
Les géométries d’entités simples (représentées par la première colonne du tableau) peuvent être transformées en plusieurs types de géométrie, représentés par les colonnes du tableau 5.1
Plusieurs des transformations ne sont pas possibles, par exemple, vous ne pouvez pas convertir un point unique en un multilinéaire (multilinestring) ou un polygone (ainsi les cellules [1, 4:5] dans le tableau sont NA).
Certaines transformations divisent un seul élément en plusieurs sous-éléments, en “étendant” les objets sf (en ajoutant de nouvelles lignes avec des valeurs d’attributs dupliquées).
Par exemple, lorsqu’une géométrie multipoint composée de cinq paires de coordonnées est transformée en une géométrie “POINT”, la sortie contiendra cinq entités.
| POI | MPOI | LIN | MLIN | POL | MPOL | GC | |
|---|---|---|---|---|---|---|---|
| POI(1) | 1 | 1 | 1 | NA | NA | NA | NA |
| MPOI(1) | 4 | 1 | 1 | 1 | 1 | NA | NA |
| LIN(1) | 5 | 1 | 1 | 1 | 1 | NA | NA |
| MLIN(1) | 7 | 2 | 2 | 1 | NA | NA | NA |
| POL(1) | 5 | 1 | 1 | 1 | 1 | 1 | NA |
| MPOL(1) | 10 | 1 | NA | 1 | 2 | 1 | 1 |
| GC(1) | 9 | 1 | NA | NA | NA | NA | 1 |
Note: Note : Les valeurs comme (1) représentent le nombre d’entités ; NA signifie que l’opération n’est pas possible. Abréviations : POI, LIN, POL et GC font référence à POINT, LINESTRING, POLYGON et GEOMETRYCOLLECTION. La version MULTI de ces types de géométrie est indiquée par un M précédent, par exemple, MPOI est l’acronyme de MULTIPOINT.
Essayons d’appliquer des transformations de type géométrique sur un nouvel objet, multilinestring_sf, à titre d’exemple (à gauche sur la Figure 5.12) :
multilinestring_list = list(matrix(c(1, 4, 5, 3), ncol = 2),
matrix(c(4, 4, 4, 1), ncol = 2),
matrix(c(2, 4, 2, 2), ncol = 2))
multilinestring = st_multilinestring(multilinestring_list)
multilinestring_sf = st_sf(geom = st_sfc(multilinestring))
multilinestring_sf
#> Simple feature collection with 1 feature and 0 fields
#> Geometry type: MULTILINESTRING
#> Dimension: XY
#> Bounding box: xmin: 1 ymin: 1 xmax: 4 ymax: 5
#> CRS: NA
#> geom
#> 1 MULTILINESTRING ((1 5, 4 3)...Vous pouvez l’imaginer comme un réseau routier ou fluvial.
Le nouvel objet n’a qu’une seule ligne qui définit toutes les lignes.
Cela limite le nombre d’opérations qui peuvent être faites, par exemple, cela empêche d’ajouter des noms à chaque segment de ligne ou de calculer les longueurs des lignes individuelles.
La fonction st_cast() peut être utilisée dans cette situation, car elle sépare un mutlilinestring en trois linestrings :
linestring_sf2 = st_cast(multilinestring_sf, "LINESTRING")
linestring_sf2
#> Simple feature collection with 3 features and 0 fields
#> Geometry type: LINESTRING
#> Dimension: XY
#> Bounding box: xmin: 1 ymin: 1 xmax: 4 ymax: 5
#> CRS: NA
#> geom
#> 1 LINESTRING (1 5, 4 3)
#> 2 LINESTRING (4 4, 4 1)
#> 3 LINESTRING (2 2, 4 2)#> [cols4all] color palettes: use palettes from the R package cols4all. Run 'cols4all::c4a_gui()' to explore them. The old palette name "Set2" is named "set2" (in long format "brewer.set2")
#> Multiple palettes called "set2 found: "brewer.set2", "hcl.set2". The first one, "brewer.set2", is returned.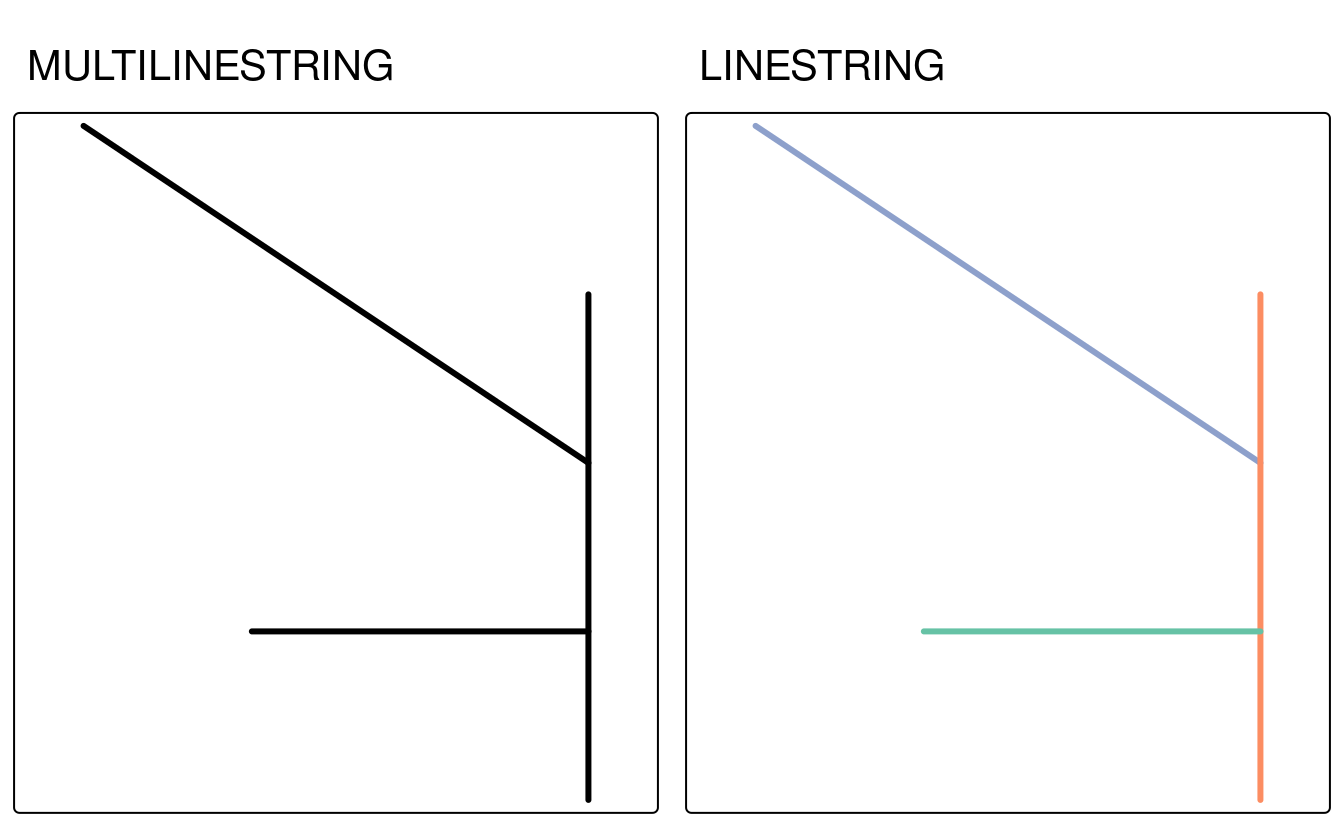
FIGURE 5.12: Exemples de transformation de type de géométrie entre MULTILINESTRING (à gauche) et LINESTRING (à droite).
Le nouvel objet permet la création d’attributs (voir la section 3.2.5) et la mesure de la longueur :
linestring_sf2$name = c("Riddle Rd", "Marshall Ave", "Foulke St")
linestring_sf2$length = st_length(linestring_sf2)
linestring_sf2
#> Simple feature collection with 3 features and 2 fields
#> Geometry type: LINESTRING
#> Dimension: XY
#> Bounding box: xmin: 1 ymin: 1 xmax: 4 ymax: 5
#> CRS: NA
#> geom name length
#> 1 LINESTRING (1 5, 4 3) Riddle Rd 3.61
#> 2 LINESTRING (4 4, 4 1) Marshall Ave 3.00
#> 3 LINESTRING (2 2, 4 2) Foulke St 2.005.3 Opérations géométriques sur les données raster
Les opérations géométriques sur des raster comprennent le décalage, le retournement, la mise en miroir, la mise à l’échelle, la rotation ou la déformation des images. Ces opérations sont nécessaires pour une variété d’applications, y compris le géoréférencement, utilisé pour permettre aux images d’être superposées sur une carte précise avec un CRS connu (Liu and Mason 2009). Il existe une variété de techniques de géoréférencement, notamment :
- Géorectification basée sur des points de contrôle au sol connus
- Orthorectification, qui tient également compte de la topographie locale.
- L’enregistrement d’images est utilisé pour combiner des images de la même chose mais prises par différents capteurs en alignant une image sur une autre (en termes de système de coordonnées et de résolution).
R est plutôt inadapté pour les deux premiers points car ceux-ci nécessitent souvent une intervention manuelle, c’est pourquoi ils sont généralement réalisés à l’aide d’un logiciel SIG dédié (voir également le chapitre : ??). En revanche, l’alignement de plusieurs images est possible dans R et cette section montre entre autres comment le faire. Cela implique souvent de modifier l’étendue, la résolution et l’origine d’une image. Une projection correspondante est bien sûr également nécessaire, mais elle est déjà traitée dans la section 7.8.
Dans tous les cas, il existe d’autres raisons d’effectuer une opération géométrique sur une seule image raster. Par exemple, dans le chapitre ?? nous définissons les zones métropolitaines en Allemagne comme des pixels de 20 km2 avec plus de 500.000 habitants. La trame d’habitants d’origine a cependant une résolution de 1 km2, c’est pourquoi nous allons diminuer (agréger) la résolution d’un facteur 20 (voir le chapitre ??). Une autre raison d’agréger une image matricielle est simplement de réduire le temps d’exécution ou d’économiser de l’espace disque. Bien entendu, cela n’est possible que si la tâche à accomplir permet une résolution plus grossière.
5.3.1 Intersections géométriques
Dans la section 4.3.1, nous avons montré comment extraire des valeurs d’un raster superposé à d’autres objets spatiaux.
Pour récupérer une sortie spatiale, nous pouvons utiliser pratiquement la même syntaxe de sélection.
La seule différence est que nous devons préciser que nous souhaitons conserver la structure matricielle en mettant l’argument drop à FALSE.
Ceci retournera un objet raster contenant les cellules dont les points médians se chevauchent avec clip.
elev = rast(system.file("raster/elev.tif", package = "spData"))
clip = rast(xmin = 0.9, xmax = 1.8, ymin = -0.45, ymax = 0.45,
resolution = 0.3, vals = rep(1, 9))
elev[clip, drop = FALSE]
#> class : SpatRaster
#> dimensions : 2, 1, 1 (nrow, ncol, nlyr)
#> resolution : 0.5, 0.5 (x, y)
#> extent : 1, 1.5, -0.5, 0.5 (xmin, xmax, ymin, ymax)
#> coord. ref. : lon/lat WGS 84 (EPSG:4326)
#> source(s) : memory
#> varname : elev
#> name : elev
#> min value : 18
#> max value : 24Pour la même opération, nous pouvons également utiliser les commandes intersect() et crop().
5.3.2 Étendue et origine
Lors de la fusion ou de l’exécution de l’algèbre raster sur des rasters, leur résolution, leur projection, leur origine et/ou leur étendue doivent correspondre. Sinon, comment ajouter les valeurs d’un raster ayant une résolution de 0,2 degré décimal à un second raster ayant une résolution de 1 degré décimal ? Le même problème se pose lorsque nous souhaitons fusionner des images satellite provenant de différents capteurs avec des projections et des résolutions différentes. Nous pouvons traiter de telles disparités en alignant les trames.
Dans le cas le plus simple, deux images ne diffèrent que par leur étendue. Le code suivant ajoute une ligne et deux colonnes de chaque côté de l’image raster tout en fixant toutes les nouvelles valeurs à une altitude de 1000 mètres (Figure 5.13).
elev = rast(system.file("raster/elev.tif", package = "spData"))
elev_2 = extend(elev, c(1, 2))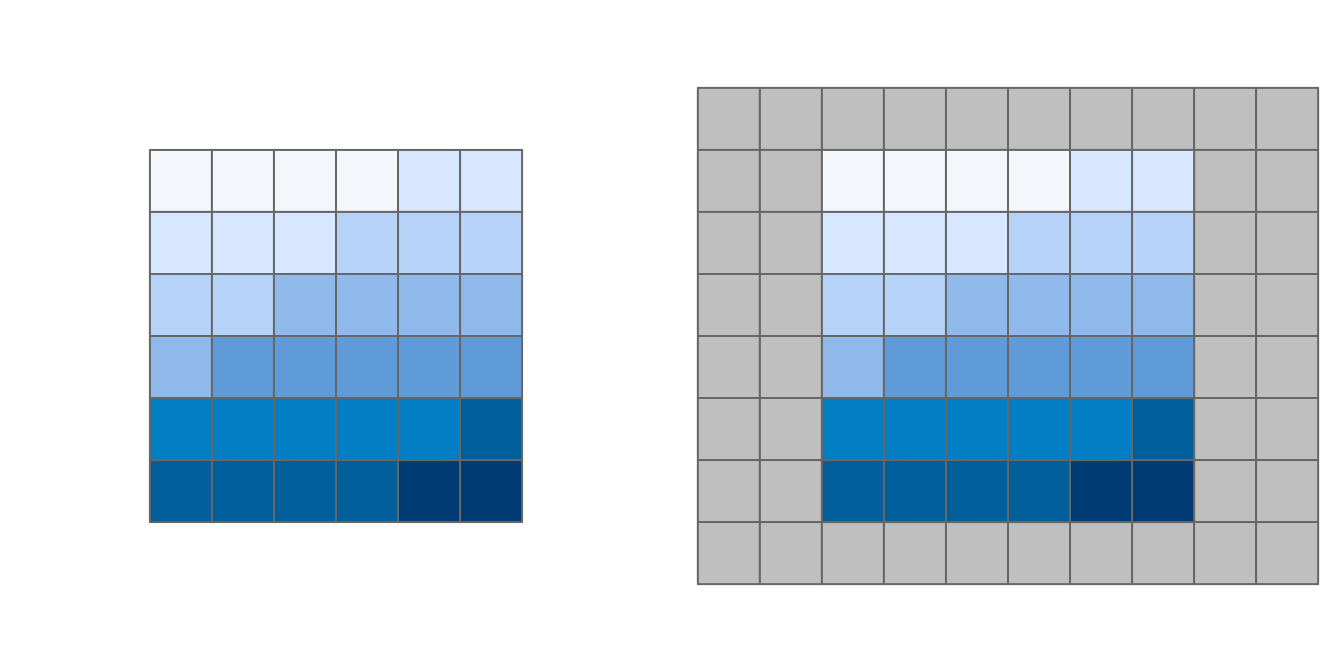
FIGURE 5.13: Trame originale (à gauche) et la même trame (à droite) agrandie d’une ligne en haut et en bas et de deux colonnes à gauche et à droite.
Performing an algebraic operation on two objects with differing extents in R, the terra package returns an error.
elev_3 = elev + elev_2
#> Error: [+] extents do not matchCependant, nous pouvons aligner l’étendue de deux rasters avec extend().
Au lieu d’indiquer à la fonction le nombre de lignes ou de colonnes à ajouter (comme nous l’avons fait précédemment), nous lui permettons de le déterminer en utilisant un autre objet raster.
Ici, nous étendons l’objet elev à l’étendue de elev_2.
Les lignes et colonnes nouvellement ajoutées prennent la valeur NA.
elev_4 = extend(elev, elev_2)L’origine d’un raster est le coin de la cellule le plus proche des coordonnées (0, 0).
La fonction origin() renvoie les coordonnées de l’origine.
Dans l’exemple ci-dessous, un coin de cellule existe avec les coordonnées (0, 0), mais ce n’est pas toujours le cas.
origin(elev_4)
#> [1] 0 0Si deux rasters ont des origines différentes, leurs cellules ne se chevauchent pas complètement, ce qui rends l’algèbre raster impossible.
Pour changer l’origine – utilisez origin().23
La figure 5.14 révèle l’effet de la modification de l’origine de cette manière.
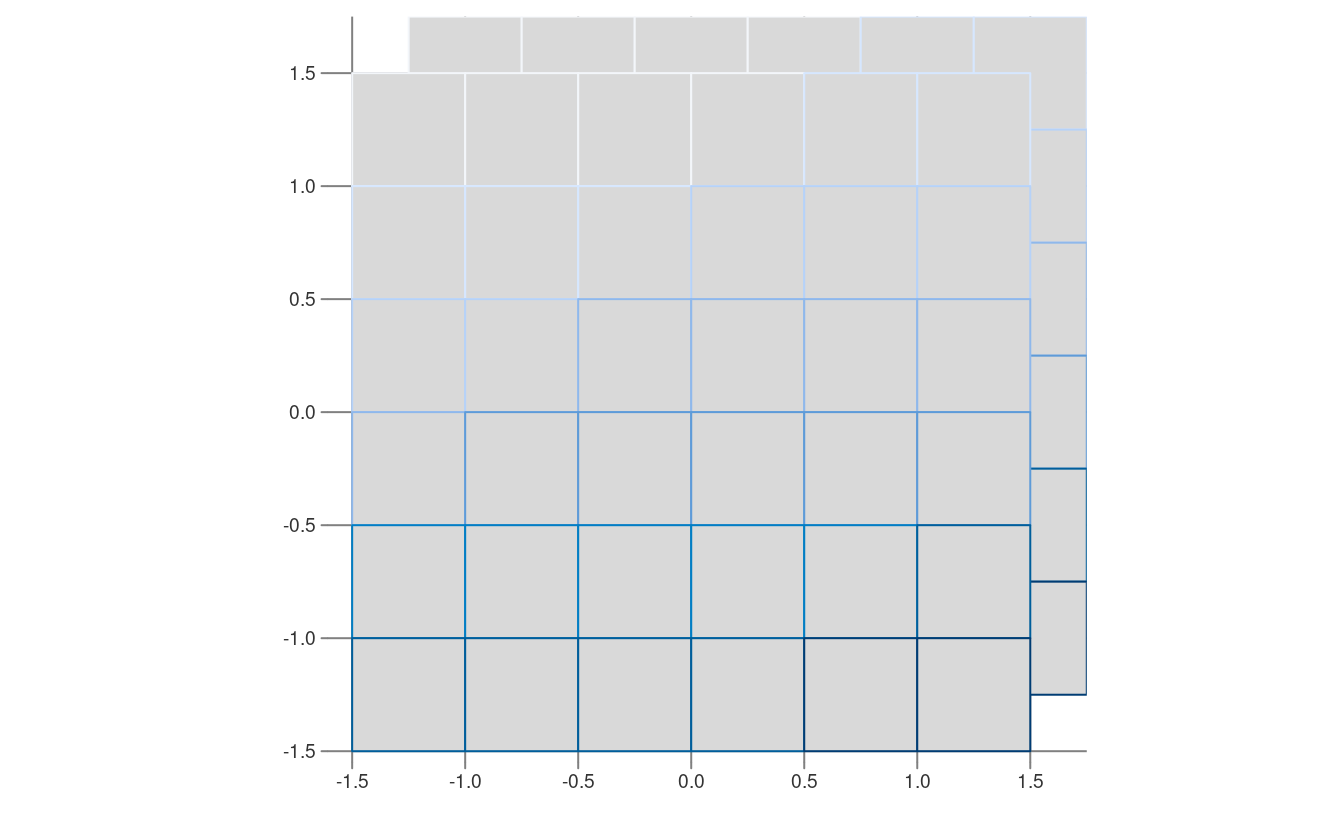
FIGURE 5.14: Rasters avec des valeurs identiques mais des origines différentes.
Notez que le changement de résolution (section suivante) modifie souvent aussi l’origine.
5.3.3 Agrégation et désagrégation
Les jeux de données raster peuvent également différer en ce qui concerne leur résolution.
Pour faire correspondre les résolutions, on peut soit diminuer (aggregate()) soit augmenter (disagg()) la résolution des rasters.24
À titre d’exemple, nous modifions ici la résolution spatiale de dem (trouvé dans le paquet spDataLarge) par un facteur 5 (Figure 5.15).
De plus, la valeur de la cellule de sortie doit correspondre à la moyenne des cellules d’entrée (notez que l’on pourrait également utiliser d’autres fonctions, telles que median(), sum(), etc ):
dem = rast(system.file("raster/dem.tif", package = "spDataLarge"))
dem_agg = aggregate(dem, fact = 5, fun = mean)#> -- tmap v3 code detected --
#> [v3->v4] tm_raster(): instead of 'style = "cont"', use 'col.scale = tm_scale_continuous()'
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.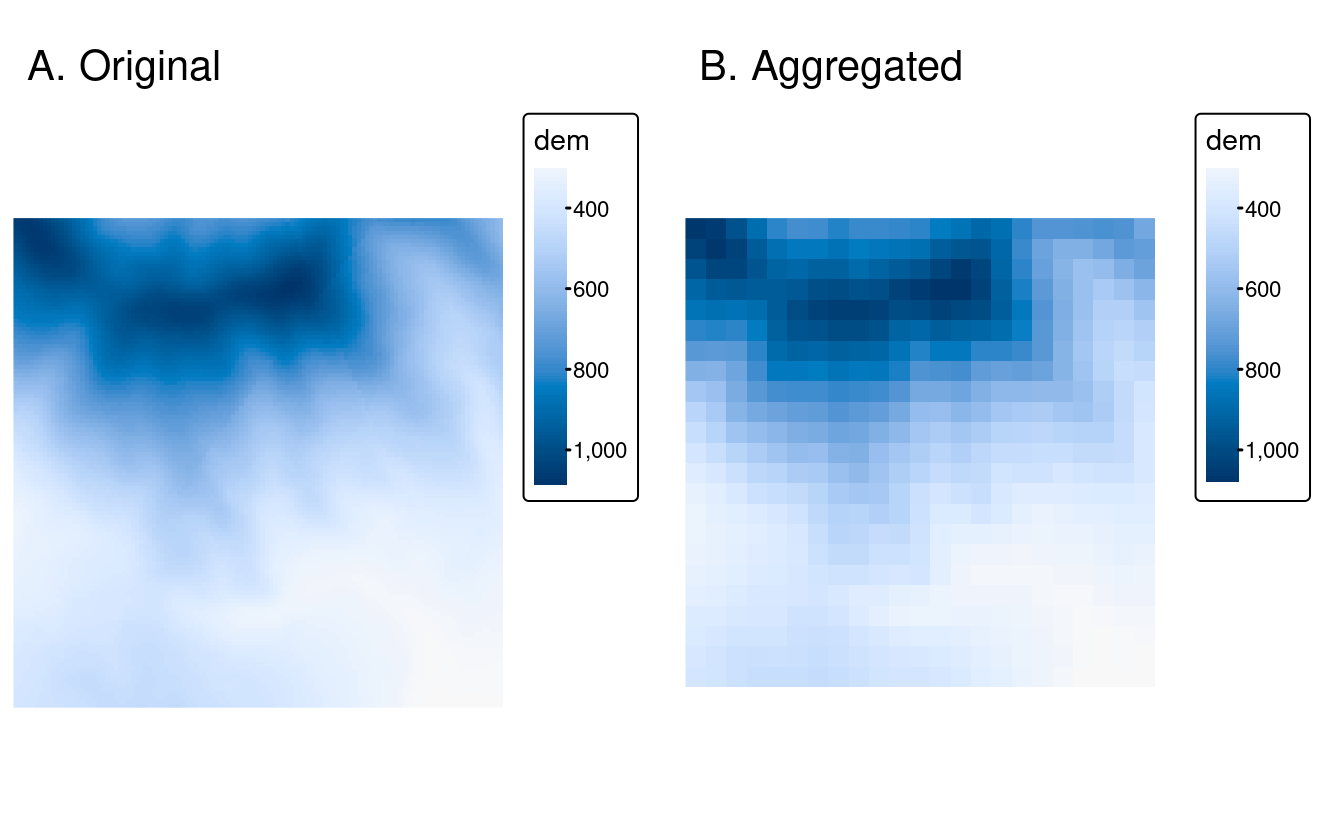
FIGURE 5.15: Raster original (gauche). Raster agrégé (droite).
La fonction disagg() augmente la résolution des objets matriciels, en fournissant deux méthodes pour assigner des valeurs aux cellules nouvellement créées : la méthode par défaut (method = "near") donne simplement à toutes les cellules de sortie la valeur de la cellule d’entrée, et donc duplique les valeurs, ce qui conduit à une sortie “en bloc”.
La méthode bilinear utilise les quatre centres de pixels les plus proches de l’image d’entrée (points de couleur saumon sur la figure 5.16) pour calculer une moyenne pondérée par la distance (flèches sur la figure 5.16.
La valeur de la cellule de sortie est représentée par un carré dans le coin supérieur gauche de la figure 5.16).
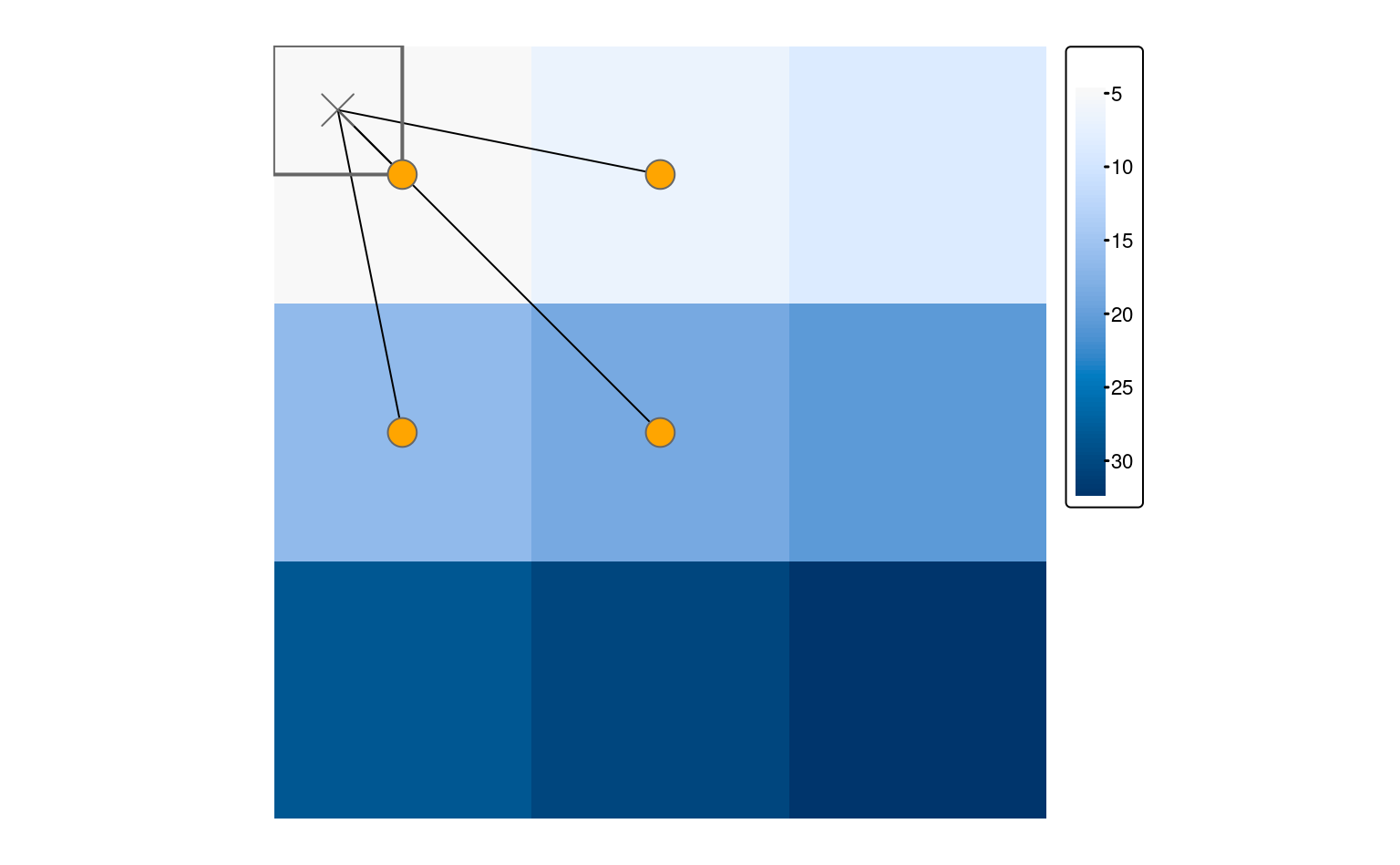
FIGURE 5.16: La moyenne pondérée par la distance des quatre cellules d’entrée les plus proches détermine la sortie lors de l’utilisation de la méthode bilinéaire pour la désagrégation.
En comparant les valeurs de dem et dem_disagg, on constate qu’elles ne sont pas identiques (vous pouvez aussi utiliser compareGeom() ou all.equal()).
Cependant, il ne fallait pas s’y attendre, puisque la désagrégation est une simple technique d’interpolation.
Il est important de garder à l’esprit que la désagrégation permet d’obtenir une résolution plus fine ; les valeurs correspondantes, cependant, ne peuvent qu’êtres aussi précises que leur source de résolution initiale.
5.3.4 Rééchantillonnage
Les méthodes d’agrégation et de désagrégation ci-dessus ne conviennent que lorsque nous voulons modifier la résolution de notre raster par le facteur d’agrégation/désagrégation. Cependant, que faire lorsque nous avons deux ou plusieurs raster avec des résolutions et des origines différentes ? C’est le rôle du rééchantillonnage - un processus de calcul des valeurs pour les nouveaux emplacements des pixels. En bref, ce processus prend les valeurs de notre raster original et recalcule de nouvelles valeurs pour un raster cible avec une résolution et une origine personnalisées.
Il existe plusieurs méthodes pour estimer les valeurs d’un raster avec différentes résolutions/origines, comme le montre la figure 5.17. Ces méthodes comprennent :
- Plus proche voisin - attribue la valeur de la cellule la plus proche du raster original à la cellule du raster cible. Cette méthode est rapide et convient généralement aux réechantillonnage de raster de catégories.
- Interpolation bilinéaire - affecte une moyenne pondérée des quatre cellules les plus proches de l’image originale à la cellule de l’image cible (Figure 5.16). Il s’agit de la méthode la plus rapide pour les rasters continus
- Interpolation cubique - utilise les valeurs des 16 cellules les plus proches de la trame d’origine pour déterminer la valeur de la cellule de sortie, en appliquant des fonctions polynomiales du troisième ordre. Elle est aussi utilisée pour les raster continus. Elle permet d’obtenir une surface plus lissée que l’interpolation bilinéaire, mais elle est également plus exigeante en termes de calcul.
- Interpolation par spline cubique - utilise également les valeurs des 16 cellules les plus proches de la trame d’origine pour déterminer la valeur de la cellule de sortie, mais applique des splines cubiques (fonctions polynomiales du troisième ordre par morceaux) pour obtenir les résultats. Elle est utilisée pour les trames continues
- Rééchantillonnage par fenêtré de Lanczos - utilise les valeurs des 36 cellules les plus proches de la trame d’origine pour déterminer la valeur de la cellule de sortie. Il est utilisé pour les raster continues25
Les explications ci-dessus mettent en évidence le fait que seul le rééchantillonnage par voisin le plus proche est adapté aux rasters contenant des catégories, alors que toutes les méthodes peuvent être utilisées (avec des résultats différents) pour les matrices continues. En outre, chaque méthode successive nécessite plus de temps de traitement.
Pour appliquer le rééchantillonnage, le package terra fournit une fonction resample().
Elle accepte un raster d’entrée (x), un raster avec des propriétés spatiales cibles (y), et une méthode de rééchantillonnage (method).
Nous avons besoin d’un raster avec des propriétés spatiales cibles pour voir comment la fonction resample() fonctionne.
Pour cet exemple, nous créons target_rast, mais vous utiliserez souvent un objet raster déjà existant.
target_rast = rast(xmin = 794600, xmax = 798200,
ymin = 8931800, ymax = 8935400,
resolution = 150, crs = "EPSG:32717")Ensuite, nous devons fournir nos deux objets rasters comme deux premiers arguments et l’une des méthodes de rééchantillonnage décrites ci-dessus.
dem_resampl = resample(dem, y = target_rast, method = "bilinear")La figure 5.17 montre une comparaison de différentes méthodes de rééchantillonnage sur l’objet dem.
#> -- tmap v3 code detected --
#> [v3->v4] tm_raster(): migrate the argument(s) related to the scale of the visual variable 'col', namely 'breaks' to 'col.scale = tm_scale(<HERE>)'
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> [v3->v4] tm_raster(): use 'col.legend = tm_legend_hide()' instead of 'legend.show = FALSE
#> Warning: The 'main.title' argument of 'tm_layout()' is deprecated as of tmap
#> 4.0. Please use 'tm_title()' instead.
#> [plot mode] fit legend/component: Some legend items or map compoments do not fit well, and are therefore rescaled. Set the tmap option 'component.autoscale' to FALSE to disable rescaling.
#> [plot mode] fit legend/component: Some legend items or map compoments do not fit well, and are therefore rescaled. Set the tmap option 'component.autoscale' to FALSE to disable rescaling.
#> [plot mode] fit legend/component: Some legend items or map compoments do not fit well, and are therefore rescaled. Set the tmap option 'component.autoscale' to FALSE to disable rescaling.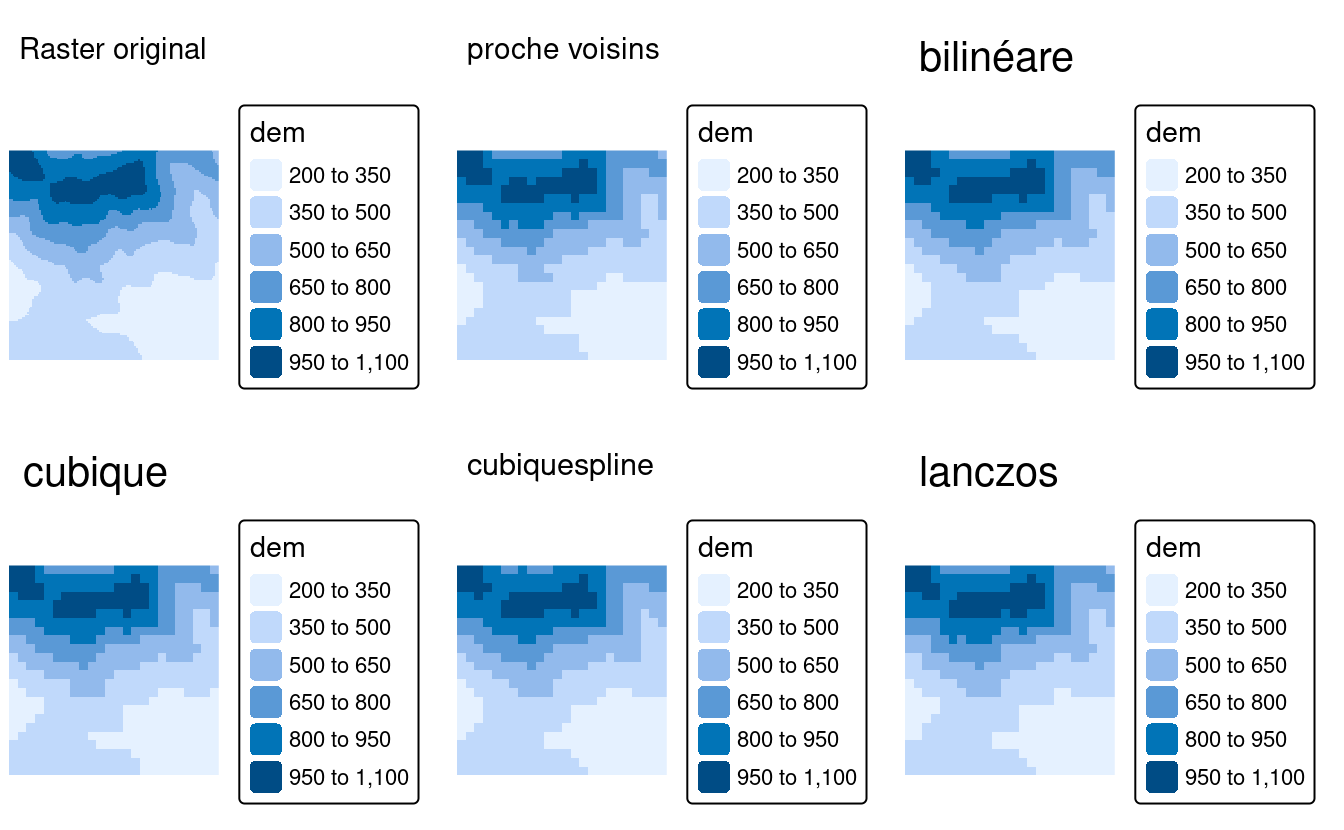
FIGURE 5.17: Comparaison visuelle du raster d’entré et de cinq méthodes de rééchantillonnage différentes.
La fonction resample() dispose également de quelques méthodes de rééchantillonnage supplémentaires, dont sum, min, q1, med, q3, max, average, mode, et rms.
Elles calculent toutes une statistique donnée en se basant sur les valeurs de toutes les cellules de la grille (hors NA).
Par exemple, sum est utile lorsque chaque cellule de raster représente une variable étendue dans l’espace (par exemple, le nombre de personnes).
En utilisant sum, le raster ré-échantillonné devrait avoir le même nombre total de personnes que le raster original.
Comme vous le verrez dans la section 7.8, la reprojection de raster est un cas particulier de rééchantillonnage lorsque notre raster cible a un CRS différent de la trame d’origine.
La plupart des opérations géométriques dans terra sont conviviales, plutôt rapides, et fonctionnent sur de grands objets rasters. Cependant, il peut y avoir des cas où terra n´est pas le plus performant, que ce soit pour des objets rasters étendus ou pour de nombreux fichiers rasters, et où des alternatives doivent être envisagées.
Les alternatives les plus établies sont fournies par la bibliothèque GDAL. Elle contient plusieurs fonctions utilitaires, dont :
-
gdalinfo- liste diverses informations sur un fichier raster, y compris sa résolution, son CRS, sa boîte de délimitation, et plus encore. -
gdal_translate- convertit les données raster entre différents formats de fichiers. -
gdal_rasterize- Convertit les données vectorielles en fichiers raster. -
gdalwarp- permet le mosaïquage, le rééchantillonnage, le recadrage et la reprojection de données matricielles.
gdalUtilities::gdal_translate("mon_fichier.tif", "nouveau_fichier.tif", t_srs = "EPSG:4326")).
Ceci est très différent de l´approche habituelle de terra, qui attend des objets SpatRaster en entrée.
5.4 Exercises
E1. Générer et représenter des versions simplifiées de l’ensemble de données nz.
Expérimentez avec différentes valeurs de keep (allant de 0,5 à 0,00005) pour ms_simplify() et dTolerance (de 100 à 100 000) pour st_simplify().
- À partir de quelle valeur la forme du résultat commence-t-elle à se dégrader pour chaque méthode, rendant la Nouvelle-Zélande méconnaissable ?
- Avancé : Qu’est-ce qui est différent dans le type de géométrie des résultats de
st_simplify()par rapport au type de géométrie dems_simplify()? Quels problèmes cela crée-t-il et comment peut-on les résoudre ?
E2. Dans le premier exercice du chapitre Opérations sur les données spatiales, il a été établi que la région de Canterbury comptait 70 des 101 points les plus élevés de Nouvelle-Zélande.
En utilisant st_buffer(), combien de points dans nz_height sont à moins de 100 km de Canterbury ?
E3. Trouvez le centroïde géographique de la Nouvelle-Zélande. A quelle distance se trouve-t-il du centroïde géographique de Canterbury ?
E4. La plupart des cartes du monde sont orientées du nord vers le haut.
Une carte du monde orientée vers le sud pourrait être créée par une réflexion (une des transformations affines non mentionnées dans ce chapitre) de la géométrie de l’objet world.
Comment faire ?
Astuce : vous devez utiliser un vecteur à deux éléments pour cette transformation.
Bonus : créez une carte de votre pays à l’envers.
E5. Sélectionnez le point dans p qui est contenu dans x et y.
- En utilisant les opérateurs de sélection de base.
- En utilisant un objet intermédiaire créé avec
st_intersection().
E6. Calculez la longueur des limites des États américains en mètres.
Quel État a la frontière la plus longue et quel État a la plus courte ?
Indice : La fonction st_length calcule la longueur d’une géométrie LINESTRING ou MULTILINESTRING.
E7. Lire le fichier srtm.tif dans R (srtm = rast(system.file("raster/srtm.tif", package = "spDataLarge"))).
Ce raster a une résolution de 0.00083 par 0.00083 degrés.
Changez sa résolution à 0,01 par 0,01 degrés en utilisant toutes les méthodes disponibles dans le paquet terra.
Visualisez les résultats.
Pouvez-vous remarquer des différences entre les résultats de ces différentes méthodes de rééchantillonnage ?