4 Géotraitements
Prérequis
- Ce chapitre nécessité les mêmes paquets que ceux utilisés dans le chapitre 3:
- Vous devrez également charger deux jeux de données pour cette section 4.3
elev = rast(system.file("raster/elev.tif", package = "spData"))
grain = rast(system.file("raster/grain.tif", package = "spData"))4.1 Introduction
Les opérations spatiales, y compris les jointures spatiales entre les ensembles de données vectorielles et les opérations locales et focales sur les ensembles de données raster, constituent une partie essentielle de la géocomputation. Ce chapitre montre comment les objets spatiaux peuvent être modifiés d’une multitude de façons en fonction de leur emplacement et de leur forme. De nombreuses opérations spatiales ont un équivalent non spatial (par exemple via leurs attributs), de sorte que des concepts tels que la sélection et la jonction de jeux de données démontrés dans le chapitre précédent sont applicables ici. Cela est particulièrement vrai pour les opérations vectorielles : La section ?? sur la manipulation des tables attributaires fournit la base pour comprendre son équivalent spatial, à savoir la sélection spatial (traitée dans la section ??). La jointure spatiale (section ??) et l’agrégation (section 4.2.6) ont également des contreparties non spatiales, traitées dans le chapitre précédent.
Les opérations spatiales diffèrent toutefois des opérations non spatiales à plusieurs égards : Les jointures spatiales, par exemple, peuvent être effectuées de plusieurs manières — y compris la mise en correspondance d’entités qui se croisent ou se trouvent à une certaine distance de l’ensemble de données cible — alors que les jointures de table attributaire abordées dans la section ?? du chapitre précédent ne peuvent être effectuées que d’une seule manière (sauf lorsqu’on utilise des jointures floues, comme décrit dans la documentation du paquet fuzzyjoin). Les différents types de relations spatiales entre objets comme les superpositions/intersections et les objets disjoints, sont décrits dans la section ??. Un autre aspect unique des objets spatiaux est la distance : tous les objets spatiaux sont liés par l’espace et les calculs de distance peuvent être utilisés pour explorer la force de cette relation, comme décrit dans le contexte des données vectorielles à la section ??.
Les opérations spatiales sur les rasters comprennent la sélection — traité dans la section 4.3.1 — et la fusion de plusieurs ” tuiles ” raster en un seul objet, comme le montre la section ??. L’algèbre de raster couvre une gamme d’opérations qui modifient les valeurs des cellules, avec ou sans référence aux valeurs des cellules environnantes. Le concept d’algèbre de raster vital pour de nombreuses applications, est présenté dans la section ?? ; les opérations d’algèbre de raster locales, focales et zonales sont traitées respectivement dans les sections ??, ?? et ??. Les opérations d’algèbre globales, qui génèrent des statistiques synthétiques représentant l’ensemble d’un jeu de données raster, et les calculs de distance sur les données raster, sont abordés dans la section ??. Dans la dernière section avant les exercices (??), le processus de fusion de deux ensembles de données raster est abordé et démontré à l’aide d’un exemple reproductible.
4.2 Géotraitements sur des données vectorielles
Cette section fournit une vue d’ensemble des opérations spatiales sur les données géographiques vectorielles représentées sous forme de simple features du package sf. La section 4.3 présente les opérations spatiales sur les ensembles de données raster à l’aide des classes et des fonctions du paquet terra.
4.2.1 Sélection spatiale
La sélection spatial est le processus qui consiste à prendre un objet spatial et à renvoyer un nouvel objet contenant uniquement les caractéristiques en relation dans l’espace à un autre objet.
De manière analogue à la sélection d’attributs (traité dans la section ??), des sélection de jeux de données sf peuvent être créés avec l’opérateur de crochets ([) en utilisant la syntaxe x[y, , op = st_intersects], où x est un objet sf à partir duquel un sous-ensemble de lignes sera retourné, y est l’objet de sous-ensemble et , op = st_intersects est un argument optionnel qui spécifie la relation topologique (également connue sous le nom de prédicat binaire) utilisée pour faire la sélection.
La relation topologique par défaut utilisée lorsqu’un argument op n’est pas fourni est st_intersects() : la commande x[y, ] est identique à x[y, , op = st_intersects] montrée ci-dessus mais pas à x[y, , op = st_disjoint] (la signification de ces relations topologiques et des autres est décrite dans la section suivante).
La fonction filter() du tidyverse peut également être utilisée mais cette approche est plus verbeuse, comme nous le verrons dans les exemples ci-dessous.
To demonstrate spatial subsetting, we will use the nz and nz_height datasets in the spData package, which contain geographic data on the 16 main regions and 101 highest points in New Zealand, respectively (Figure 4.1), in a projected coordinate system.
The following code chunk creates an object representing Canterbury, then uses spatial subsetting to return all high points in the region:
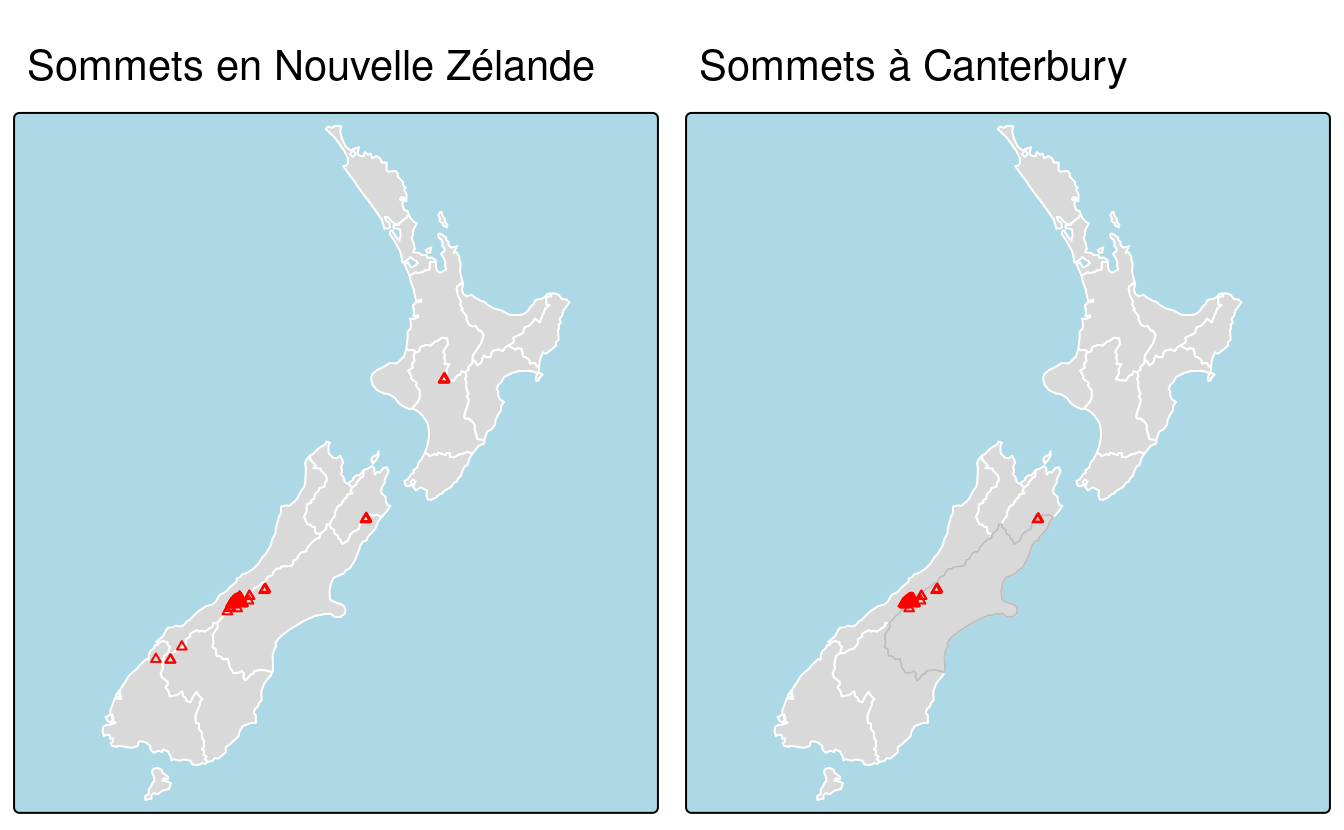
FIGURE 4.1: Exemple de sélection spatiale avec des triangles rouges représentant 101 points hauts en Nouvelle-Zélande, regroupés près de la région centrale de Canterbury (à gauche). Les points dans la région de Canterbury ont été créés avec l’opérateur de sélection [ (surligné en gris, à droite).
Comme pour la sélection d’attributs, la commande x[y, ] (équivalente à nz_height[canterbury, ]) sélectionne les caractéristiques d’une cible x en utilisant le contenu d’un objet source y.
Cependant, au lieu que y soit un vecteur de classe logical ou integer, pour la sélection spatiale, x et y doivent être des objets géographiques.
Plus précisément, les objets utilisés pour la sélection spatiale de cette manière doivent avoir la classe sf ou sfc : nz et nz_height sont tous deux des jeux de données vectorielles géographiques et ont la classe sf, et le résultat de l’opération renvoie un autre objet sf représentant les caractéristiques de l’objet cible nz_height qui intersectent (dans ce cas, les points hauts qui sont situés dans) la région de canterbury.
Diverses relations topologiques peuvent être utilisées pour le sélection spatiale. Elles déterminent le type de relation spatiale que les caractéristiques de l’objet cible doivent avoir avec l’objet de sélection.
Il peut s’agir de touches (touche), crosses (croisse) ou within (dedans), comme nous le verrons bientôt dans la section ??.
Le paramètre par défaut st_intersects est une relation topologique ‘attrape-tout’ qui retournera les éléments de la cible qui touchent, croissent ou sont within (dedans) l’objet source ‘sélectionnant’.
Comme indiqué ci-dessus, d’autres opérateurs spatiaux peuvent être spécifiés avec l’argument op =, comme le montre la commande suivante qui renvoie l’opposé de st_intersects(), les points qui ne sont pas en intersection avec Canterbury (voir la section ??) :
nz_height[canterbury, , op = st_disjoint], , — dans l´extrait de code précédent est inclus pour mettre en évidence op, le troisième argument dans [ pour les objets sf.
On peut l´utiliser pour modifier l´opération de sélection de plusieurs façons.
nz_height[canterbury, 2, op = st_disjoint], par exemple, retourne les mêmes lignes mais n´inclut que la deuxième colonne d´attributs (voir sf:::`[.sf et le `?sf`` pour plus de détails).
Pour de nombreuses applications, c’est tout ce que vous aurez besoin de savoir sur les sélections spatiales avec les données vectorielles !
Si vous êtes impatient d’en savoir plus sur les relations topologiques, au-delà de st_intersects() et st_disjoint(), passez à la section suivante (??).
Si vous êtes intéressé par les détails, y compris les autres façons de faire des sélections, c’est par ici.
Une autre façon d’effectuer une sélection spatiale est d’utiliser les objets retournés par les opérateurs topologiques. Ces objets peuvent être utiles en soi, par exemple lors de l’exploration du réseau de relations entre des régions contiguës, mais ils peuvent également être utilisés pour sélectionner comme le montre le morceau de code ci-dessous :
sel_sgbp = st_intersects(x = nz_height, y = canterbury)
class(sel_sgbp)
#> [1] "sgbp" "list"
sel_sgbp
#> Sparse geometry binary predicate list of length 101, where the
#> predicate was `intersects'
#> first 10 elements:
#> 1: (empty)
#> 2: (empty)
#> 3: (empty)
#> 4: (empty)
#> 5: 1
#> 6: 1
#> 7: 1
#> 8: 1
#> 9: 1
#> 10: 1
sel_logical = lengths(sel_sgbp) > 0
canterbury_height2 = nz_height[sel_logical, ]Le code ci-dessus crée un objet de classe sgbp (un prédicat binaire de géométrie “creuse”, une liste de longueur x dans l’opération spatiale) et le convertit ensuite en un vecteur logique sel_logical (contenant seulement les valeurs TRUE et FALSE, quelque chose qui peut aussi être utilisé par la fonction filtre de dplyr).
La fonction lengths() identifie les éléments de nz_height qui ont une intersection avec tout objet de y.
Dans ce cas, 1 est la plus grande valeur possible, mais pour des opérations plus complexes, on peut utiliser la méthode pour sélectionner uniquement les caractéristiques qui ont une intersection avec, par exemple, 2 caractéristiques ou plus de l’objet source.
sparse = FALSE (ce qui signifie retourner une matrice dense et non une matrice ‘creuse’) dans des opérateurs tels que st_intersects(). La commande st_intersects(x = nz_height, y = canterbury, sparse = FALSE)[, 1], par exemple, retournerait une sortie identique à sel_logical.
Note : la solution impliquant les objets sgbp est cependant plus généralisable, car elle fonctionne pour les opérations many-to-many et a des besoins en mémoire plus faibles.
Le même résultat peut être obtenu avec la fonction de sf st_filter() qui a été créée pour augmenter la compatibilité entre les objets sf et les manipulation de données de dplyr :
canterbury_height3 = nz_height |>
st_filter(y = canterbury, .predicate = st_intersects)A ce stade, il y a trois versions identiques (à l’exception des noms de lignes) de canterbury_height, une créée en utilisant l’opérateur [, une créée via un objet de sélection intermédiaire, et une autre utilisant la fonction de commodité de sf st_filter().
La section suivante explore différents types de relations spatiales, également connues sous le nom de prédicats binaires, qui peuvent être utilisées pour identifier si deux éléments sont spatialement liés ou non.
4.2.2 Relations topologiques
Les relations topologiques décrivent les relations spatiales entre les objets.
Les “relations topologiques binaires”, pour leur donner leur nom complet, sont des énoncés logiques (en ce sens que la réponse ne peut être que VRAI ou FAUX) sur les relations spatiales entre deux objets définis par des ensembles ordonnés de points (formant typiquement des points, des lignes et des polygones) en deux dimensions ou plus (Egenhofer and Herring 1990).
Cela peut sembler plutôt abstrait et, en effet, la définition et la classification des relations topologiques reposent sur des fondements mathématiques publiés pour la première fois sous forme de livre en 1966 (Spanier 1995), le domaine de la topologie algébrique se poursuivant au 21e siècle (Dieck 2008).
Malgré leur origine mathématique, les relations topologiques peuvent être comprises intuitivement en se référant à des visualisations de fonctions couramment utilisées qui testent les types courants de relations spatiales.
La figure 4.2 montre une variété de paires géométriques et leurs relations associées.
Les troisième et quatrième paires de la figure 4.2 (de gauche à droite puis vers le bas) montrent que, pour certaines relations, l’ordre est important : alors que les relations equals, intersects, crosses, touches et overlaps sont symétriques, ce qui signifie que si function(x, y) est vraie, function(y, x) le sera aussi, les relations dans lesquelles l’ordre des géométries est important, comme contains et within, ne le sont pas.
Remarquez que chaque paire de géométries possède une chaîne “DE-9IM” telle que FF2F11212, décrite dans la section suivante.
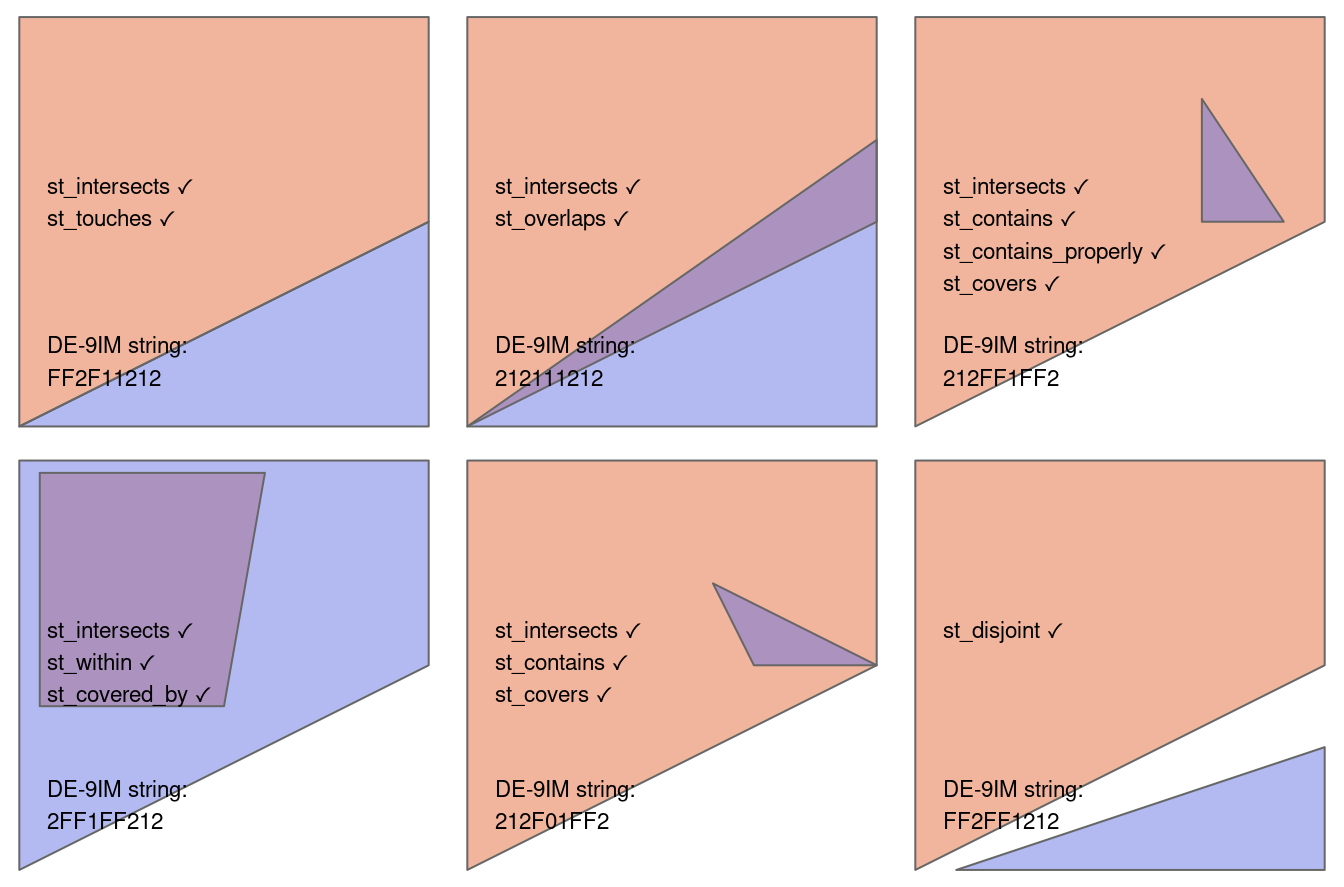
FIGURE 4.2: Relations topologiques entre géométries vectorielles, inspirées des figures 1 et 2 d’Egenhofer et Herring (1990). Les relations pour lesquelles la fonction(x, y) est vraie sont imprimées pour chaque paire de géométries, x étant représenté en rose et y en bleu. La nature de la relation spatiale pour chaque paire est décrite par la chaîne de caractères du Dimensionally Extended 9-Intersection Model.
Dans sf, les fonctions testant les différents types de relations topologiques sont appelées binary predicates”, comme décrit dans la vignette Manipulating Simple Feature Geometries, qui peut être consultée avec la commande vignette("sf3"), et dans la page d’aide ?geos_binary_pred.
Pour voir comment les relations topologiques fonctionnent en pratique, créons un exemple simple et reproductible, en nous appuyant sur les relations illustrées dans la Figure 4.2 et en consolidant les connaissances sur la représentation des géométries vectorielles acquises dans un chapitre précédent (Section 2.2.4).
Notez que pour créer des données tabulaires représentant les coordonnées (x et y) des sommets du polygone, nous utilisons la fonction R de base cbind() pour créer une matrice représentant les points de coordonnées, un POLYGON, et enfin un objet sfc, comme décrit au chapitre 2) :
polygon_matrix = cbind(
x = c(0, 0, 1, 1, 0),
y = c(0, 1, 1, 0.5, 0)
)
polygon_sfc = st_sfc(st_polygon(list(polygon_matrix)))Nous allons créer des géométries supplémentaires pour démontrer les relations spatiales à l’aide des commandes suivantes qui, lorsqu’elles sont tracées sur le polygone créé ci-dessus, se rapportent les unes aux autres dans l’espace, comme le montre la Figure 4.3.
Notez l’utilisation de la fonction st_as_sf() et de l’argument coords pour convertir efficacement un tableau de données contenant des colonnes représentant des coordonnées en un objet sf contenant des points :
line_sfc = st_sfc(st_linestring(cbind(
x = c(0.4, 1),
y = c(0.2, 0.5)
)))
# créer des points
point_df = data.frame(
x = c(0.2, 0.7, 0.4),
y = c(0.1, 0.2, 0.8)
)
point_sf = st_as_sf(point_df, coords = c("x", "y"))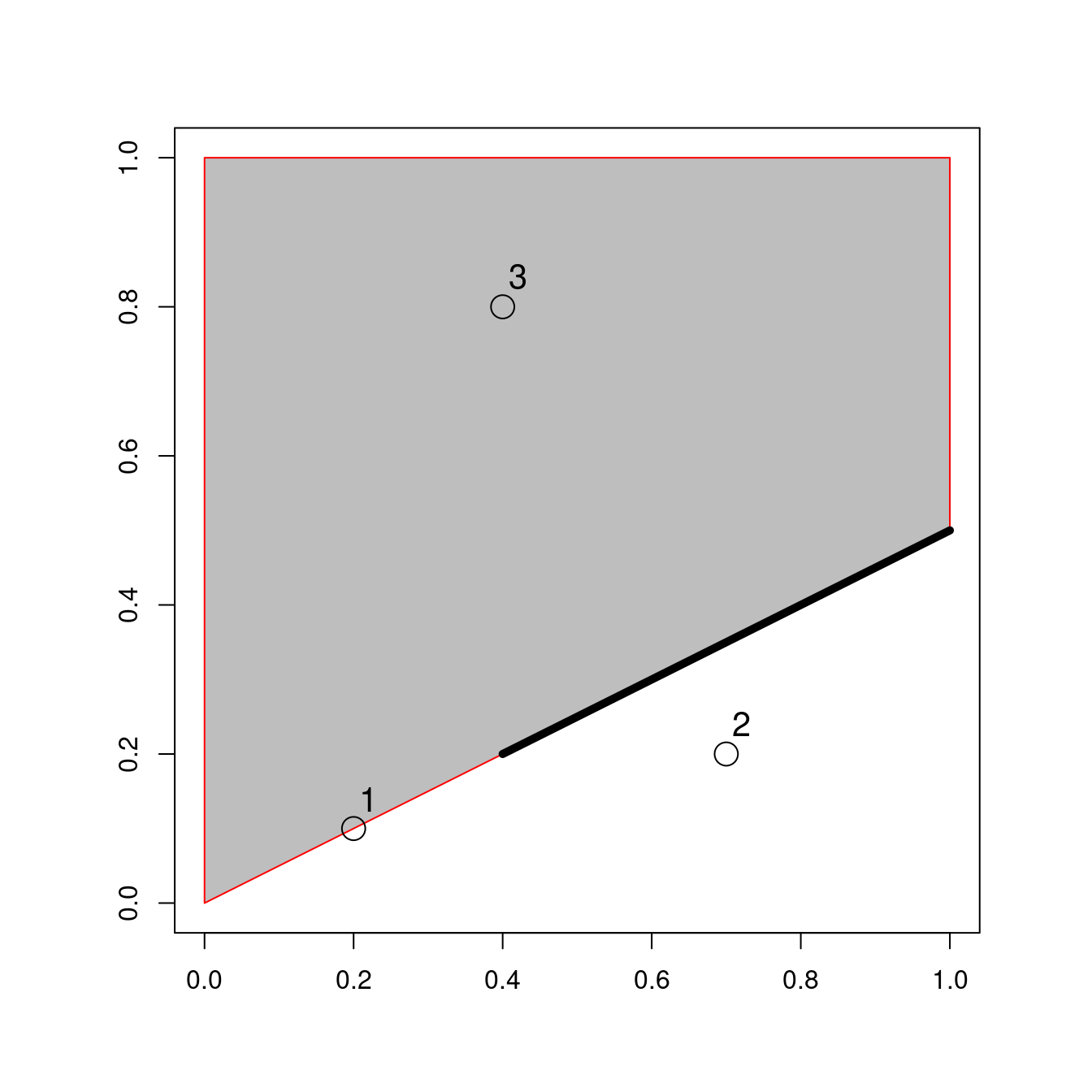
FIGURE 4.3: Points (point_df 1 à 3), ligne et polygones arrangés pour illustrer les relations topologiques.
Une première question simple pourrait être : quels sont les points de point_sf en intersection avec le polygone polygon_sfc ?
On peut répondre à cette question par inspection (les points 1 et 3 sont respectivement en contact et à l’intérieur du polygone).
On peut répondre à cette question avec le prédicat spatial st_intersects() comme suit:
st_intersects(point_sf, polygon_sfc)
#> Sparse geometry binary predicate... `intersects'
#> 1: 1
#> 2: (empty)
#> 3: 1Le résultat devrait correspondre à votre intuition :
des résultats positifs (1) sont retournés pour le premier et le troisième point, et un résultat négatif (représenté par un vecteur vide “(empty)”) pour le deuxième en dehors de la frontière du polygone.
Ce qui peut être inattendu, c’est que le résultat se présente sous la forme d’une liste de vecteurs.
Cette sortie matrice creuse n’enregistre une relation que si elle existe, ce qui réduit les besoins en mémoire des opérations topologiques sur les objets avec de nombreuses entités.
Comme nous l’avons vu dans la section précédente, une matrice dense composée de valeurs TRUE ou FALSE est retournée lorsque sparse = FALSE :
st_intersects(point_sf, polygon_sfc, sparse = FALSE)
#> [,1]
#> [1,] TRUE
#> [2,] FALSE
#> [3,] TRUEDans la sortie ci-dessus, chaque ligne représente un élément dans l’objet cible (l’argument x) et chaque colonne représente un élément dans l’objet de sélection (y).
Dans ce cas, il n’y a qu’un seul élément dans l’objet y polygon_sfc, donc le résultat, qui peut être utilisé pour la sélection comme nous l’avons vu dans la section ??, n’a qu’une seule colonne.
st_intersects() renvoie TRUE même dans les cas où les éléments se touchent juste : intersects est une opération topologique “fourre-tout” qui identifie de nombreux types de relations spatiales, comme l’illustre la figure 4.2.
Il y a des questions plus restrictives, par exemple : quels sont les points situés à l’intérieur du polygone, et quelles sont les caractéristiques qui sont sur ou qui contiennent une frontière partagée avec y ?
On peut répondre à ces questions de la manière suivante (résultats non montrés) :
st_within(point_sf, polygon_sfc)
st_touches(point_sf, polygon_sfc)Notez que bien que le premier point touche la limite du polygone, il n’est pas à l’intérieur de celui-ci ; le troisième point est à l’intérieur du polygone mais ne touche aucune partie de sa frontière.
L’opposé de st_intersects() est st_disjoint(), qui retourne uniquement les objets qui n’ont aucun rapport spatial avec l’objet sélectionné (ici [, 1] convertit le résultat en vecteur) :
st_disjoint(point_sf, polygon_sfc, sparse = FALSE)[, 1]
#> [1] FALSE TRUE FALSELa fonction st_is_within_distance() détecte les éléments qui touchent presque l’objet de sélection. La fonction a un argument supplémentaire dist.
Il peut être utilisé pour définir la distance à laquelle les objets cibles doivent se trouver avant d’être sélectionnés.
Remarquez que bien que le point 2 soit à plus de 0,2 unités de distance du sommet le plus proche de polygon_sfc, il est quand même sélectionné lorsque la distance est fixée à 0,2.
En effet, la distance est mesurée par rapport à l’arête la plus proche, dans ce cas la partie du polygone qui se trouve directement au-dessus du point 2 dans la figure ??.
(Vous pouvez vérifier que la distance réelle entre le point 2 et le polygone est de 0,13 avec la commande st_distance(point_sf, polygon_sfc)).
Le prédicat spatial binaire “is within distance” (es à distance de) est démontré dans l’extrait de code ci-dessous, dont les résultats montrent que chaque point est à moins de 0,2 unité du polygone :
st_is_within_distance(point_sf, polygon_sfc, dist = 0.2, sparse = FALSE)[, 1]
#> [1] TRUE TRUE TRUEst_join, mentionnée dans la section suivante, utilise également l´indexation spatiale.
Vous pouvez en savoir plus à l´adresse suivante https://www.r-spatial.org/r/2017/06/22/spatial-index.html.
4.2.3 Les chaines DE-9IM
Les prédicats binaires présentés dans la section précédente reposent sur le modèle Dimensionally Extended 9-Intersection Model (DE-9IM). Comme le suggère son nom cryptique, ce n’est pas un sujet facile. Y consacrer du temps peut être utile afin d’améliorer notre compréhension des relations spatiales. En outre, les utilisations avancées de DE-9IM incluent la création de prédicats spatiaux personnalisés. Ce modèle était à l’origine intitulé ” DE + 9IM ” par ses inventeurs, en référence à la ” dimension des intersections des limites, des intérieurs et des extérieurs de deux entités ” (Clementini and Di Felice 1995), mais il est désormais désigné par DE-9IM (Shen, Chen, and Liu 2018).
Pour démontrer le fonctionnement des chaînes DE-9IM, examinons les différentes façons dont la première paire de géométries peut-être reliée dans la figure 4.2.
La figure 4.4 illustre le modèle à 9 intersections (9IM). Elle montre les intersections entre chaque combinaison possible entre l’intérieur, la limite et l’extérieur de chaque objet. Chaque composant du premier objet x est disposé en colonnes et que chaque composant de y est disposé en lignes, un graphique à facettes est créé avec les intersections entre chaque élément mises en évidence.
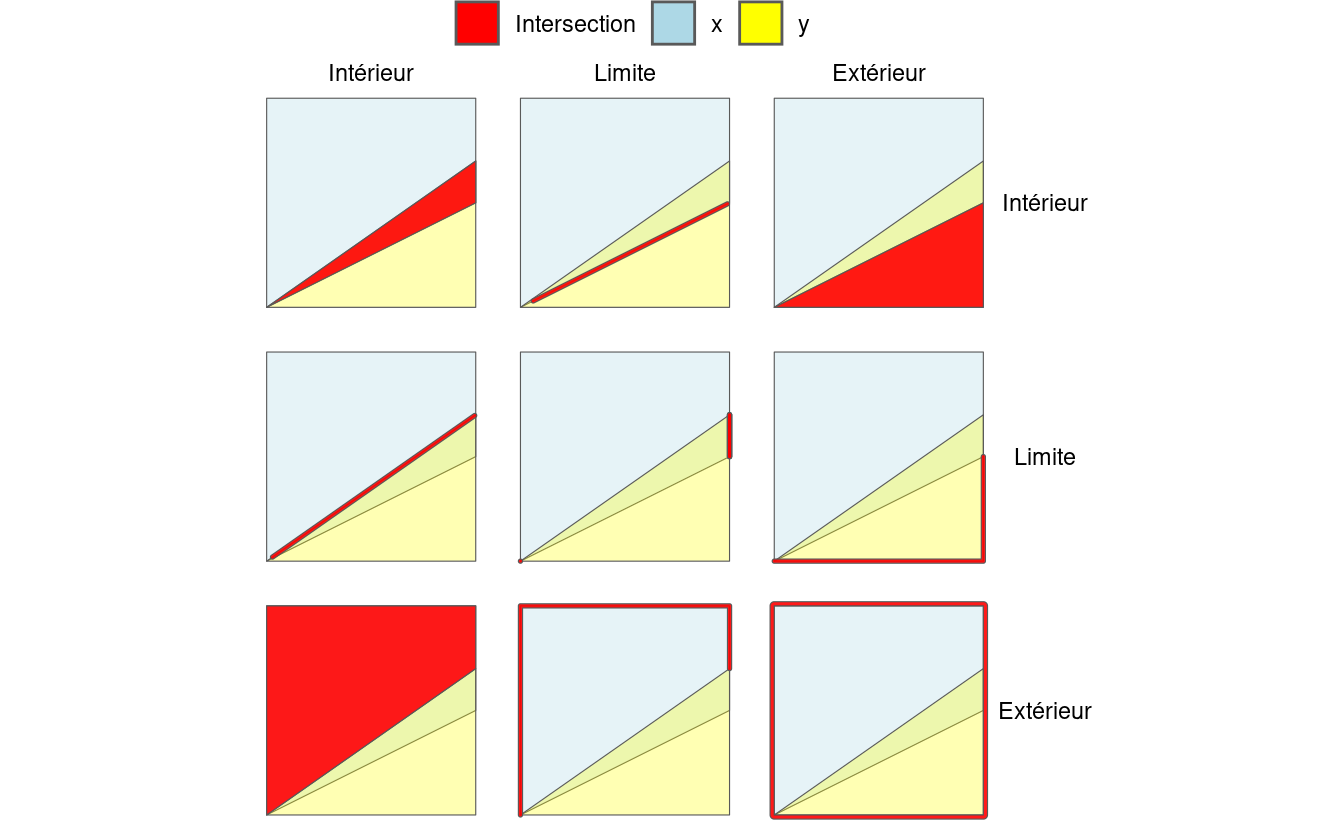
FIGURE 4.4: Illustration du fonctionnement du Modèle Dimensionnel Étendu à 9 Intersections (DE-9IM). Les couleurs qui ne figurent pas dans la légende représentent le chevauchement entre les différentes composantes. Les lignes épaisses mettent en évidence les intersections bidimensionnelles, par exemple entre la limite de l’objet x et l’intérieur de l’objet y, illustrées dans la facette supérieure du milieu.
Les chaînes DE-9IM sont dérivées de la dimension de chaque type de relation. Dans ce cas, les intersections rouges de la figure 4.4 ont des dimensions de 0 (points), 1 (lignes) et 2 (polygones), comme le montre le tableau 4.1.
| Intérieur (x) | Limite (x) | Extérieur (x) | |
|---|---|---|---|
| Intérieur (y) | 2 | 1 | 2 |
| Limite (y) | 1 | 1 | 1 |
| Extérieur (y) | 2 | 1 | 2 |
En aplatissant cette matrice “ligne par ligne” (c’est-à-dire en concaténant la première ligne, puis la deuxième, puis la troisième), on obtient la chaîne 212111212.
Un autre exemple va permettre d’expliciter ce système :
la relation représentée sur la figure 4.2 (la troisième paire de polygones dans la troisième colonne et la première ligne) peut être définie dans le système DE-9IM comme suit :
- Les intersections entre l’intérieur du grand objet
xet l’intérieur, la limite et l’extérieur deyont des dimensions respectives de 2, 1 et 2. - Les intersections entre la frontière du grand objet
xet l’intérieur, la frontière et l’extérieur deyont des dimensions respectives de F, F et 1, où “F” signifie “faux”, les objets sont disjoints. - Les intersections entre l’extérieur de
xet l’intérieur, la limite et l’extérieur deyont des dimensions respectives de F, F et 2 : l’extérieur du plus grand objet ne touche pas l’intérieur ou la limite dey, mais l’extérieur du plus petit et du plus grand objet couvre la même surface.
Ces trois composants, une fois concaténés, créent la chaîne 212, FF1, et FF2.
C’est le même résultat que celui obtenu par la fonction st_relate() (voir le code source de ce chapitre pour voir comment les autres géométries de la figure 4.2 ont été créées) :
xy2sfc = function(x, y) st_sfc(st_polygon(list(cbind(x, y))))
x = xy2sfc(x = c(0, 0, 1, 1, 0), y = c(0, 1, 1, 0.5, 0))
y = xy2sfc(x = c(0.7, 0.7, 0.9, 0.7), y = c(0.8, 0.5, 0.5, 0.8))
st_relate(x, y)
#> [,1]
#> [1,] "212FF1FF2"La compréhension des chaînes DE-9IM permet de développer de nouveaux prédicats spatiaux binaires.
La page d’aide ?st_relate contient des définitions de fonctions pour les relations “reine” et “tour” dans lesquelles les polygones partagent une frontière ou seulement un point, respectivement.
Les relations “reine” signifient que les relations “frontière-frontière” (la cellule de la deuxième colonne et de la deuxième ligne de la table 4.1, ou le cinquième élément de la chaîne DE-9IM) ne doivent pas être vides, ce qui correspond au pattern F***T****, tandis que pour les relations “tour”, le même élément doit être 1 (ce qui signifie une intersection linéaire).
Ces relations sont implémentées comme suit :
st_queen = function(x, y) st_relate(x, y, pattern = "F***T****")
st_rook = function(x, y) st_relate(x, y, pattern = "F***1****")A partir de l’objet x créé précédemment, nous pouvons utiliser les fonctions nouvellement créées pour trouver quels éléments de la grille sont une ‘reine’ et une ‘tour’ par rapport à la case centrale de la grille comme suit :
grid = st_make_grid(x, n = 3)
grid_sf = st_sf(grid)
grid_sf$queens = lengths(st_queen(grid, grid[5])) > 0
plot(grid, col = grid_sf$queens)
grid_sf$rooks = lengths(st_rook(grid, grid[5])) > 0
plot(grid, col = grid_sf$rooks)#> -- tmap v3 code detected --
#> [v3->v4] tm_polygons(): migrate the argument(s) related to the scale of the visual variable 'fill', namely 'palette' (rename to 'values') to 'fill.scale = tm_scale(<HERE>)'
#> [v3->v4] tm_polygons(): use 'fill' for the fill color of polygons/symbols (instead of 'col'), and 'col' for the outlines (instead of 'border.col')
FIGURE 4.5: Démonstration de prédicats spatiaux binaires personnalisés permettant de trouver les relations ‘reine’ (à gauche) et ‘tour’ (à droite) par rapport à la case centrale dans une grille à 9 géométries.
4.2.4 Jointure spatiale
La jointure de deux jeux de données non spatiales repose sur une variable “clé” partagée, comme décrit dans la section ??.
La jointure de données spatiales applique le même concept, mais s’appuie sur les relations spatiales, décrites dans la section précédente.
Comme pour les données attributaires, la jointure ajoute de nouvelles colonnes à l’objet cible (l’argument x dans les fonctions de jointure), à partir d’un objet source (y).
Le processus est illustré par l’exemple suivant : imaginez que vous disposez de dix points répartis au hasard sur la surface de la Terre et que vous demandez, pour les points qui se trouvent sur la terre ferme, dans quels pays se trouvent-ils ? La mise en œuvre de cette idée dans un [exemple reproductible] (https://github.com/Robinlovelace/geocompr/blob/main/code/04-spatial-join.R) renforcera vos compétences en matière de traitement des données géographiques et vous montrera comment fonctionnent les jointures spatiales. Le point de départ consiste à créer des points dispersés de manière aléatoire sur la surface de la Terre :
set.seed(2018) # définir la seed pour la reproductibilité
(bb = st_bbox(world)) # les limites de la terre
#> xmin ymin xmax ymax
#> -180.0 -89.9 180.0 83.6
random_df = data.frame(
x = runif(n = 10, min = bb[1], max = bb[3]),
y = runif(n = 10, min = bb[2], max = bb[4])
)
random_points = random_df |>
st_as_sf(coords = c("x", "y")) |> # définir les coordonnés
st_set_crs("EPSG:4326") # définir le CRSLe scénario illustré dans la Figure 4.6 montre que l’objet random_points (en haut à gauche) n’a pas d’attributs, alors que le world (en haut à droite) a des attributs, y compris les noms de pays indiqués pour un échantillon de pays dans la légende.
Les jointures spatiales sont implémentées avec st_join(), comme illustré dans l’extrait de code ci-dessous.
La sortie est l’objet random_joined qui est illustré dans la Figure 4.6 (en bas à gauche).
Avant de créer l’ensemble de données jointes, nous utilisons la sélection spatiale pour créer world_random, qui contient uniquement les pays qui contiennent des points aléatoires, afin de vérifier que le nombre de noms de pays retournés dans l’ensemble de données jointes doit être de quatre (cf. le panneau supérieur droit de la Figure 4.6).
world_random = world[random_points, ]
nrow(world_random)
#> [1] 4
random_joined = st_join(random_points, world["name_long"])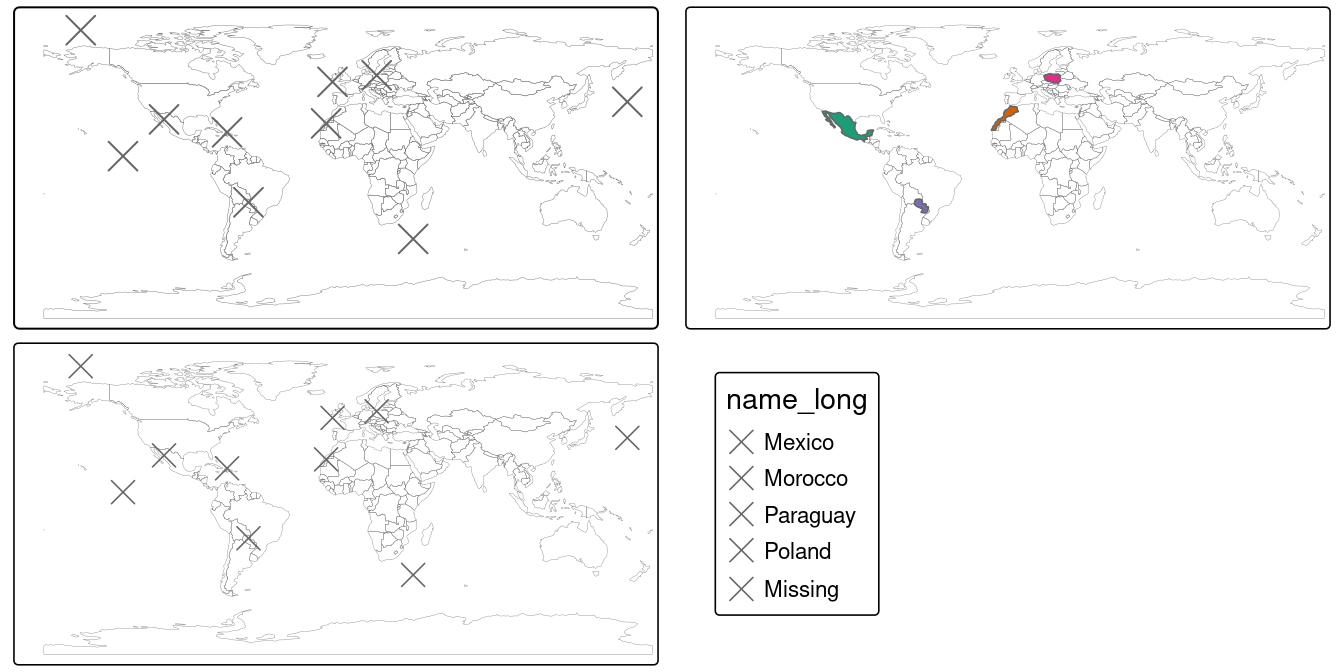
FIGURE 4.6: Illustration d’une jointure spatiale. Une nouvelle variable attributaire est ajoutée aux points aléatoires (en haut à gauche) de l’objet monde source (en haut à droite), ce qui donne les données représentées dans le dernier panneau.
Par défaut, st_join() effectue une jointure à gauche (left join), ce qui signifie que le résultat est un objet contenant toutes les lignes de x, y compris les lignes sans correspondance dans y (voir la section ??), mais il peut également effectuer des jointures internes en définissant l’argument left = FALSE.
Comme pour les sélections spatiales, l’opérateur topologique par défaut utilisé par st_join() est st_intersects(), qui peut être modifié en définissant l’argument join (cf. ?st_join pour plus de détails).
L’exemple ci-dessus montre l’ajout d’une colonne d’une couche de polygones à une couche de points, mais la même approche fonctionne indépendamment des types de géométrie.
Dans de tels cas, par exemple lorsque x contient des polygones, dont chacun correspond à plusieurs objets dans y, les jointures spatiales résulteront en des caractéristiques dupliquées, crée une nouvelle ligne pour chaque correspondance dans y.
4.2.5 Jointure sans chevauchement
Parfois, deux jeux de données géographiques ne se touchent pas mais ont quand même une forte relation géographique.
Les jeux de données cycle_hire et cycle_hire_osm, présent dans le paquet spData, en sont un bon exemple.
Leur tracé montre qu’ils sont souvent étroitement liés mais qu’ils ne se touchent pas, comme le montre la figure 4.7, dont une version de base est créée avec le code suivant ci-dessous :
plot(st_geometry(cycle_hire), col = "blue")
plot(st_geometry(cycle_hire_osm), add = TRUE, pch = 3, col = "red")Nous pouvons vérifier si certains points se superposent avec st_intersects() :
any(st_touches(cycle_hire, cycle_hire_osm, sparse = FALSE))
#> [1] FALSEFIGURE 4.7: La distribution spatiale des points de location de vélos à Londres, basée sur les données officielles (bleu) et les données OpenStreetMap (rouge).
Imaginons que nous ayons besoin de joindre la variable “capacité” de cycle_hire_osm aux données officielles “cible” contenues dans cycle_hire.
Dans ce cas, une jointure sans chevauchement est nécessaire.
La méthode la plus simple est d’utiliser l’opérateur topologique st_is_within_distance(), comme démontré ci-dessous en utilisant une distance seuil de 20 m (notez que cela fonctionne avec des données projetées et non projetées).
sel = st_is_within_distance(cycle_hire, cycle_hire_osm, dist = 20)
summary(lengths(sel) > 0)
#> Mode FALSE TRUE
#> logical 304 438Cela montre qu’il y a 438 des points dans l’objet cible cycle_hire dans la distance seuil (20 m) de cycle_hire_osm.
Comment récupérer les valeurs associées aux points respectifs de cycle_hire_osm ?
La solution est à nouveau avec st_join(), mais avec un argument dist supplémentaire (fixé à 20 m en dessous) :
z = st_join(cycle_hire, cycle_hire_osm, st_is_within_distance, dist = 20)
nrow(cycle_hire)
#> [1] 742
nrow(z)
#> [1] 762Remarquez que le nombre de lignes dans le résultat joint est supérieur à la cible.
Cela est dû au fait que certaines stations de location de vélos dans cycle_hire ont plusieurs correspondances dans cycle_hire_osm.
Pour agréger les valeurs des points qui se chevauchent et renvoyer la moyenne, nous pouvons utiliser les méthodes d’agrégation apprises au chapitre 3, ce qui donne un objet avec le même nombre de lignes que la cible :
z = z %>%
group_by(id) %>%
summarize(capacity = mean(capacity))
nrow(z) == nrow(cycle_hire)
#> [1] TRUELa capacité des stations proches peut être vérifiée en comparant les cartes de la capacité des données source cycle_hire_osm avec les résultats dans ce nouvel objet (cartes non montrées) :
Le résultat de cette jointure a utilisé une opération spatiale pour modifier les données attributaires associées aux entités simples ; la géométrie associée à chaque entité est restée inchangée.
4.2.6 Agrégats spatiaux
Comme pour l’agrégation de données attributaires, l’agrégation de données spatiales condense les données : les sorties agrégées comportent moins de lignes que les entrées non agrégées.
Les fonctions d’agrégation statistiques, telles que la moyenne ou la somme, résument plusieurs valeurs d’une variable et renvoient une seule valeur par variable de regroupement.
La section ?? a montré comment aggregate() et group_by() |> summarize() condensent les données basées sur des variables d’attributs, cette section montre comment les mêmes fonctions fonctionnent avec des objets spatiaux.
Pour revenir à l’exemple de la Nouvelle-Zélande, imaginez que vous voulez connaître la hauteur moyenne des points hauts de chaque région : c’est la géométrie de la source (y ou nz dans ce cas) qui définit comment les valeurs de l’objet cible (x ou nz_height) sont regroupées.
Ceci peut être fait en une seule ligne de code avec la méthode aggregate() de la base R :
nz_agg = aggregate(x = nz_height, by = nz, FUN = mean)Le résultat de la commande précédente est un objet sf ayant la même géométrie que l’objet d’agrégation (spatiale) (nz), ce que vous pouvez vérifier avec la commande identical(st_geometry(nz), st_geometry(nz_agg)).
Le résultat de l’opération précédente est illustré dans la Figure 4.8, qui montre la valeur moyenne des caractéristiques de nz_height dans chacune des 16 régions de la Nouvelle-Zélande.
Le même résultat peut également être généré en passant la sortie de st_join() dans les fonctions ‘tidy’ group_by() et summarize() comme suit :
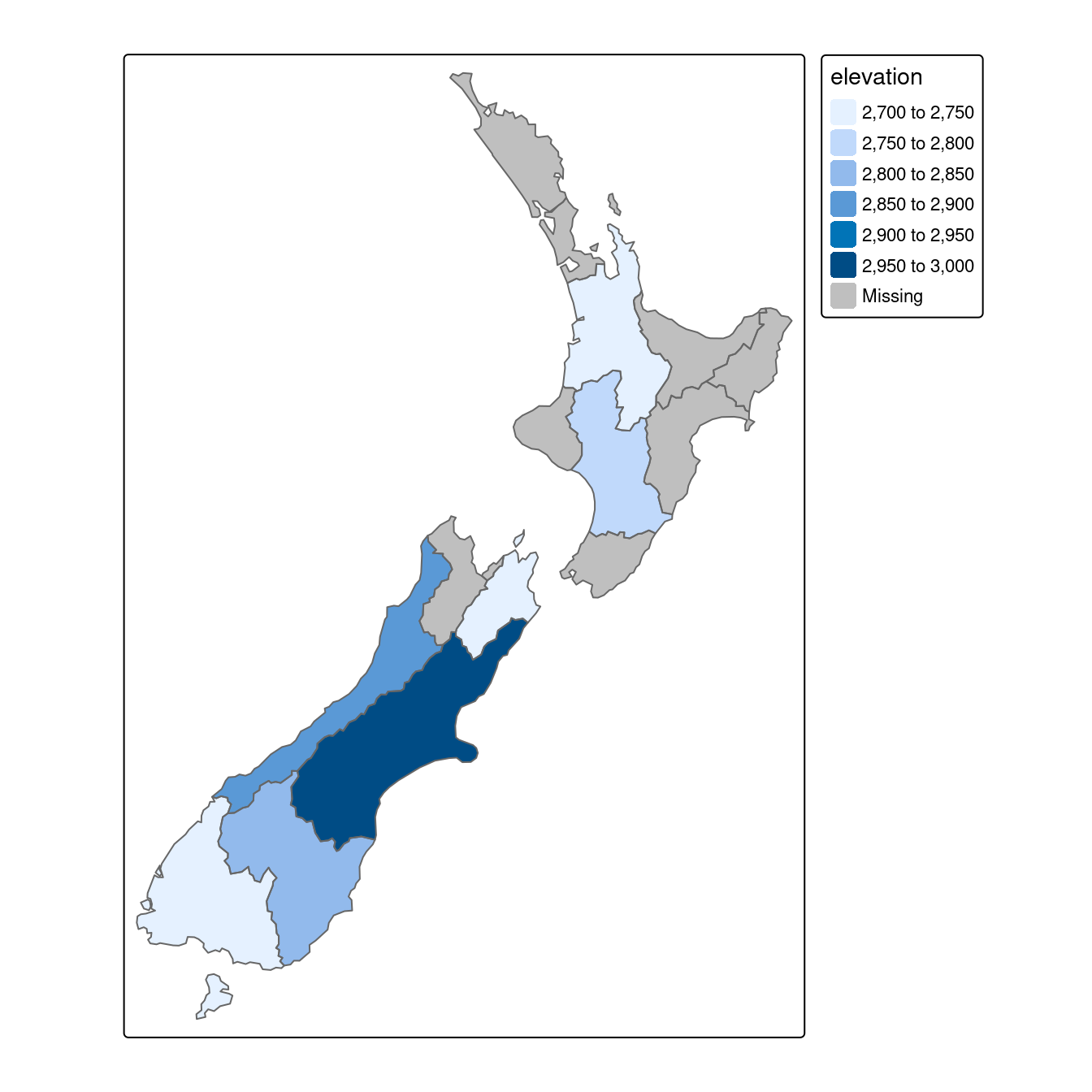
FIGURE 4.8: Hauteur moyenne des 101 points culminants par régions de la Nouvelle-Zélande.
nz_agg2 = st_join(x = nz, y = nz_height) |>
group_by(Name) |>
summarize(elevation = mean(elevation, na.rm = TRUE))Les entités nz_agg résultants ont la même géométrie que l’objet d’agrégation nz mais avec une nouvelle colonne résumant les valeurs de x dans chaque région en utilisant la fonction mean().
D’autres fonctions peuvent, bien sûr, remplacer mean() comme la median(), sd() ou d’autres fonctions qui retournent une seule valeur par groupe.
Remarque : une différence entre les approches aggregate() et group_by() |> summarize() est que la première donne des valeurs NA pour les noms de régions non correspondantes, tandis que la seconde préserve les noms de régions.
L’approche “tidy” est plus flexible en termes de fonctions d’agrégation et de noms de colonnes des résultats.
Les opérations d’agrégation créant de nouvelles géométries sont décrites dans la section ??.
4.2.7 Jointure de couches sans superposition parfaite
La congruence spatiale est un concept important lié à l’agrégation spatiale.
Un objet d’agrégation (que nous appellerons y) est congruent avec l’objet cible (x) si les deux objets ont des frontières communes.
C’est souvent le cas des données sur les limites administratives, où des unités plus grandes — telles que les Middle Layer Super Output Areas (MSOAs) au Royaume-Uni ou les districts dans de nombreux autres pays européens — sont composées de nombreuses unités plus petites.
Les objets d’agrégation non congruent, en revanche, ne partagent pas de frontières communes avec la cible (Qiu, Zhang, and Zhou 2012). C’est un problème pour l’agrégation spatiale (et d’autres opérations spatiales) illustrée dans la figure 4.9 : agréger le centroïde de chaque sous-zone ne donnera pas de résultats précis. L’interpolation surfacique résout ce problème en transférant les valeurs d’un ensemble d’unités surfaciques à un autre, à l’aide d’une gamme d’algorithmes comprenant des approches simples de pondération de la surface et des approches plus sophistiquées telles que les méthodes ” pycnophylactiques ” (Tobler 1979).

FIGURE 4.9: Illustration des entités surfaciques congruentes (à gauche) et non congruentes (à droite) par rapport à des zones d’agrégation plus grandes (bordures bleues translucides).
Le paquet spData contient un jeux de données nommé incongruent (polygones colorés avec des bordures noires dans le panneau de droite de la Figure 4.9) et un ensemble de données nommé aggregating_zones (les deux polygones avec la bordure bleue translucide dans le panneau de droite de la Figure 4.9).
Supposons que la colonne valeur de incongruent se réfère au revenu régional total en millions d’euros.
Comment pouvons-nous transférer les valeurs des neuf polygones spatiaux sous-jacents dans les deux polygones de aggregating_zones ?
La méthode la plus simple est l’interpolation spatiale pondérée par la surface, qui transfère les valeurs de l’objet non congruent vers une nouvelle colonne dans aggregating_zones proportionnellement à la surface de recouvrement : plus l’intersection spatiale entre les caractéristiques d’entrée et de sortie est grande, plus la valeur correspondante est grande.
Ceci est implémenté dans st_interpolate_aw(), comme démontré dans le morceau de code ci-dessous.
iv = incongruent["value"] # garde uniquement les valeurs à transférer
agg_aw = st_interpolate_aw(iv, aggregating_zones, extensive = TRUE)
#> Warning in st_interpolate_aw.sf(iv, aggregating_zones, extensive = TRUE):
#> st_interpolate_aw assumes attributes are constant or uniform over areas of x
agg_aw$value
#> [1] 19.6 25.7Dans notre cas, il est utile d’additionner les valeurs des intersections qui se trouvent dans les zones d’agrégation, car le revenu total est une variable dite spatialement extensive (qui augmente avec la superficie), en supposant que le revenu est réparti uniformément dans les zones plus petites (d’où le message d’avertissement ci-dessus).
Il en va différemment pour les variables spatialement intensives telles que le revenu moyen ou les pourcentages, qui n’augmentent pas avec la superficie.
st_interpolate_aw() fonctionne également avec des variables spatialement intensives : mettez le paramètre extensive à FALSE et il utilisera une moyenne plutôt qu’une fonction de somme pour faire l’agrégation.
4.2.8 Les relations de distance
Alors que les relations topologiques sont binaires — une caractéristique est soit en intersection avec une autre ou non — les relations de distance sont continues.
La distance entre deux objets est calculée avec la fonction st_distance().
Ceci est illustré dans l’extrait de code ci-dessous, qui trouve la distance entre le point le plus élevé de Nouvelle-Zélande et le centroïde géographique de la région de Canterbury, créé dans la section ?? :
nz_highest = nz_height |> slice_max(n = 1, order_by = elevation)
canterbury_centroid = st_centroid(canterbury)
st_distance(nz_highest, canterbury_centroid)
#> Units: [m]
#> [,1]
#> [1,] 115540Il y a deux choses potentiellement surprenantes dans ce résultat :
- Il a des
unités, ce qui nous indique que la distance est de 100 000 mètres, et non de 100 000 pouces, ou toute autre mesure de distance. - Elle est retournée sous forme de matrice, même si le résultat ne contient qu’une seule valeur.
Cette deuxième caractéristique laisse entrevoir une autre fonctionnalité utile de st_distance(), sa capacité à retourner des matrices de distance entre toutes les combinaisons de caractéristiques dans les objets x et y.
Ceci est illustré dans la commande ci-dessous, qui trouve les distances entre les trois premières caractéristiques de nz_height et les régions d’Otago et de Canterbury en Nouvelle-Zélande représentées par l’objet co.
co = filter(nz, grepl("Canter|Otag", Name))
st_distance(nz_height[1:3, ], co)
#> Units: [m]
#> [,1] [,2]
#> [1,] 123537 15498
#> [2,] 94283 0
#> [3,] 93019 0Remarquez que le distance entre les deuxième et troisième éléments de nz_height et le deuxième élément de co est de zéro.
Cela démontre le fait que les distances entre les points et les polygones se réfèrent à la distance à n’importe quelle partie du polygone :
Les deuxième et troisième points dans nz_height sont dans Otago, ce qui peut être vérifié en les traçant (résultat non montré) :
plot(st_geometry(co)[2])
plot(st_geometry(nz_height)[2:3], add = TRUE)4.3 Opérations spatiales sur les données raster
Cette section s’appuie sur la section ??, qui met en évidence diverses méthodes de base pour manipuler des jeux de données raster. Elle illustre des opérations raster plus avancées et explicitement spatiales, et utilise les objets elev et grain créés manuellement dans la section ??.
Pour la commodité du lecteur, ces jeux de données se trouvent également dans le paquet spData.
4.3.1 Sélection spatiale
Le chapitre précédent (Section ??) a montré comment extraire les valeurs associées à des ID de cellules spécifiques ou à des combinaisons de lignes et de colonnes.
Les objets raster peuvent également être extraits par leur emplacement (coordonnées) et via d’autres objets spatiaux.
Pour utiliser les coordonnées pour la sélection, on peut “traduire” les coordonnées en un ID de cellule avec la fonction terra cellFromXY().
Une alternative est d’utiliser terra::extract() (attention, il existe aussi une fonction appelée extract() dans le tidyverse) pour extraire des valeurs.
Les deux méthodes sont démontrées ci-dessous pour trouver la valeur de la cellule qui couvre un point situé aux coordonnées 0,1, 0,1.
id = cellFromXY(elev, xy = matrix(c(0.1, 0.1), ncol = 2))
elev[id]
# the same as
terra::extract(elev, matrix(c(0.1, 0.1), ncol = 2))Les objets raster peuvent également être sélectionnés avec un autre objet raster, comme le montre le code ci-dessous :
clip = rast(xmin = 0.9, xmax = 1.8, ymin = -0.45, ymax = 0.45,
resolution = 0.3, vals = rep(1, 9))
elev[clip]
# on peut aussi utiliser extract
# terra::extract(elev, ext(clip))Cela revient à récupérer les valeurs du premier objet raster (dans ce cas, elev) qui se trouvent dans l’étendue d’un second objet raster (ici : clip), comme illustré dans la figure 4.10.
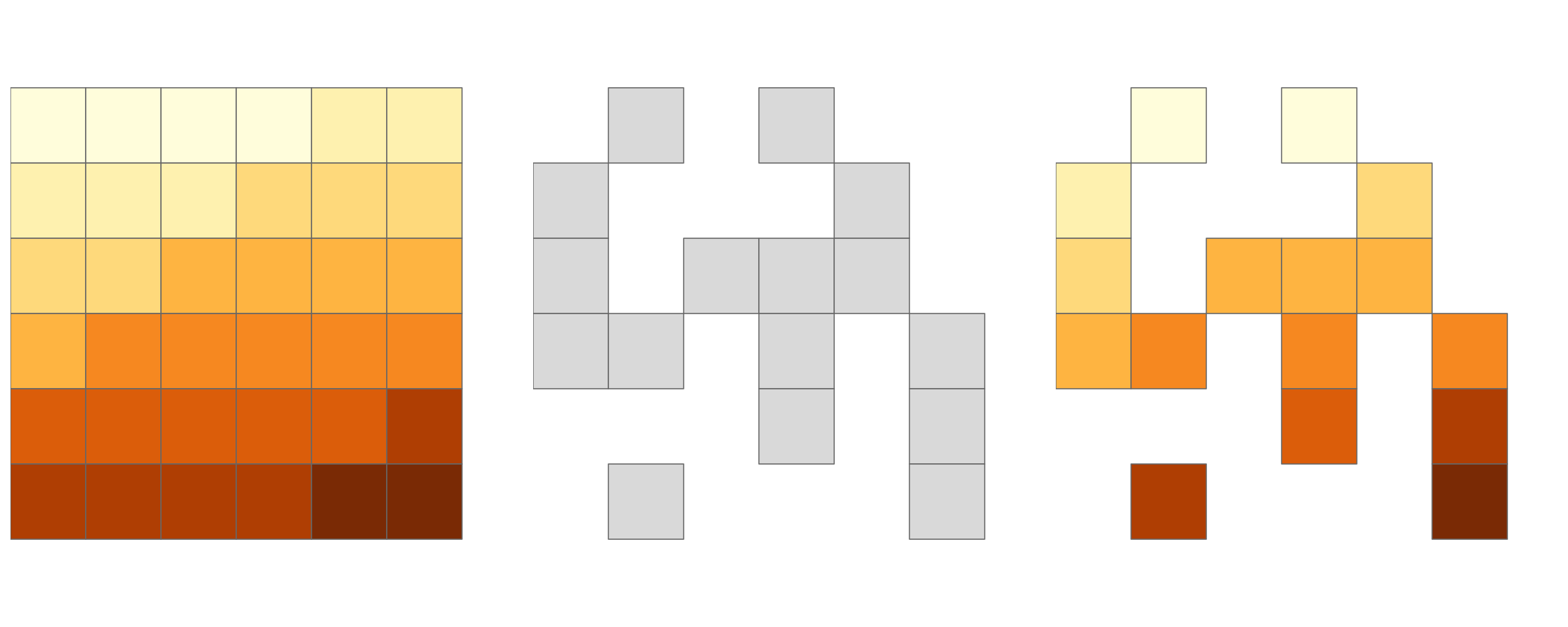
FIGURE 4.10: Raster originale (à gauche). Masque raster (au milieu). Résultat du clip (à droite).
L’exemple ci-dessus a retourné les valeurs de cellules spécifiques, mais dans de nombreux cas, ce sont des sorties spatiales qui sont nécessaires.
Cela peut être fait en utilisant l’opérateur [, avec drop = FALSE, comme indiqué dans la section ??, qui montre également comment les objets raster peuvent être sélectionnés par divers objets.
Le code ci-dessous en est un exemple en retournant les deux premières cellules (de la ligne supérieure) de elev en tant qu’objet raster (seules les 2 premières lignes de la sortie sont montrées) :
elev[1:2, drop = FALSE] # sélection spatiale par ID
#> class : SpatRaster
#> dimensions : 1, 2, 1 (nrow, ncol, nlyr)
#> ...Un autre cas d’utilisation courante de sélection spatiale est celle où une image raster avec des valeurs logiques (ou NA) est utilisée pour masquer une autre image raster avec la même étendue et la même résolution, comme illustré dans la Figure 4.10.
Dans ce cas, les fonctions [ et mask() peuvent être utilisées (résultats non montrés) :
Dans le morceau de code ci-dessus, nous avons créé un objet masque appelé rmask avec des valeurs assignées aléatoirement à NA et TRUE.
Ensuite, nous voulons garder les valeurs de elev qui sont TRUE dans rmask.
En d’autres termes, nous voulons masquer elev avec rmask.
# sélection spatiale
elev[rmask, drop = FALSE] # avec l'opérateur [
mask(elev, rmask) # avec mask()L’approche ci-dessus peut également être utilisée pour remplacer certaines valeurs (par exemple, celles qui seraient fausses) par NA.
elev[elev < 20] = NACes opérations sont en fait des opérations booléennes locales puisque nous comparons deux rasters par cellule. La sous-section suivante explore ces opérations et d’autres opérations connexes plus en détail.
4.3.2 Algèbre raster
Le terme “algèbre raster” a été inventé à la fin des années 1970 pour décrire un “ensemble de conventions, de capacités et de techniques” pour l’analyse des données géographiques raster et (bien que moins marquées) vectorielles (Tomlin 1994). Dans ce contexte, nous définissons l’algèbre raster plus strictement, comme des opérations qui modifient ou résument les valeurs des cellules raster, en référence aux cellules environnantes, aux zones ou aux fonctions statistiques s’appliquant à chaque cellule.
Les opérations d’algèbre raster ont tendance à être rapides, car les jeux de données raster ne stockent qu’implicitement les coordonnées, d’où le vieil adage “raster is faster but vector is corrector”. La position des cellules dans les jeux de données raster peut être calculée à l’aide de leur position matricielle, de la résolution et de l’origine du jeu de données (stockées dans l’en-tête). Pour le traitement, cependant, la position géographique d’une cellule n’est guère pertinente tant que nous nous assurons que la position de la cellule est toujours la même après le traitement. De plus, si deux ou plusieurs jeux de données raster partagent la même étendue, projection et résolution, on peut les traiter comme des matrices pour le traitement.
C’est de cette manière que l’algèbre raster fonctionne avec le paquet terra. Premièrement, les en-têtes des jeux de données raster sont interrogés et (dans les cas où les opérations d’algèbre raster fonctionnent sur plus d’un ensemble de données) vérifiés pour s’assurer que les jeux de données sont compatibles. Deuxièmement, l’algèbre raster conserve ce que l’on appelle la correspondance de localisation une à une, ce qui signifie que les cellules ne peuvent pas se déplacer. Cela diffère de l’algèbre matricielle, dans laquelle les valeurs changent de position, par exemple lors de la multiplication ou de la division de matrices.
L’algèbre raster (ou modélisation cartographique avec des données raster) divise les opérations sur des rasters en quatre sous-classes (Tomlin 1990), chacune travaillant sur une ou plusieurs grilles simultanément :
- Opérations locales ou par cellule
- Les opérations Focales ou de voisinage. Le plus souvent la valeur de la cellule de sortie est le résultat d’un bloc de cellules d’entrée de 3 x 3 cellules
- Les opérations Zonales sont similaires aux opérations focales, mais la grille de pixels environnante sur laquelle les nouvelles valeurs sont calculées peut avoir des tailles et des formes irrégulières.
- Les opérations Globales ou par-raster. Ici la cellule de sortie dérive potentiellement sa valeur d’un ou de plusieurs rasters entiers.
Cette typologie classe les opérations d’algèbre raster en fonction du nombre de cellules utilisées pour chaque étape de traitement des pixels et du type de sortie. Par souci d’exhaustivité, nous devons mentionner que les opérations sur des rasters peuvent également être classées par discipline, comme le terrain, l’analyse hydrologique ou la classification des images. Les sections suivantes expliquent comment chaque type d’opérations d’algèbre raster peut être utilisé, en se référant à des exemples documentés.
4.3.3 Opérations locales
Les opérations locales comprennent toutes les opérations cellule par cellule dans une ou plusieurs couches. Elles ont un cas typique d’algèbre raster et comprennent l’ajout ou la soustraction de valeurs d’une image raster, l’élévation au carré et la multiplication d’images raster. L’algèbre raster permet également des opérations logiques telles que la recherche de toutes les cellules qui sont supérieures à une valeur spécifique (5 dans notre exemple ci-dessous). Le paquet terra prend en charge toutes ces opérations et bien plus encore, comme le montre la figure ci-dessous (4.11):
elev + elev
elev^2
log(elev)
elev > 5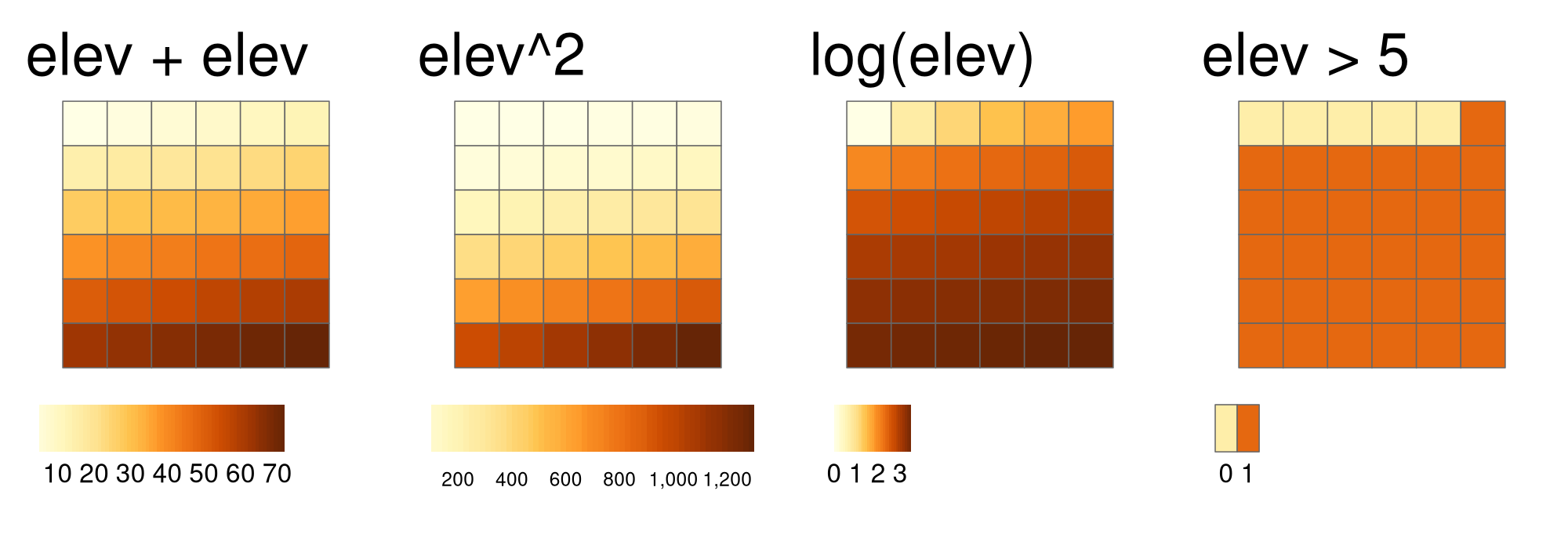
FIGURE 4.11: Exemples de différentes opérations locales de l’objet raster elev : additionner deux rasters, élever au carré, appliquer une transformation logarithmique et effectuer une opération logique.
Un autre bon exemple d’opérations locales est la classification d’intervalles de valeurs numériques en groupes, comme le regroupement d’un modèle numérique d’élévation en altitudes basses (classe 1), moyennes (classe 2) et hautes (classe 3).
En utilisant la commande classify(), nous devons d’abord construire une matrice de classification, où la première colonne correspond à l’extrémité inférieure et la deuxième colonne à l’extrémité supérieure de la classe.
La troisième colonne représente la nouvelle valeur pour les plages spécifiées dans les colonnes un et deux.
rcl = matrix(c(0, 12, 1, 12, 24, 2, 24, 36, 3), ncol = 3, byrow = TRUE)
rcl
#> [,1] [,2] [,3]
#> [1,] 0 12 1
#> [2,] 12 24 2
#> [3,] 24 36 3Ici, nous affectons les valeurs du raster dans les plages 0–12, 12–24 et 24–36 et les reclassons pour prendre les valeurs 1, 2 et 3, respectivement.
recl = classify(elev, rcl = rcl)La fonction classify() peut également être utilisée lorsque nous voulons réduire le nombre de classes dans nos rasters catégorisés.
Nous effectuerons plusieurs reclassements supplémentaires dans le chapitre ??’.
En dehors des opérateurs arithmétiques, on peut aussi utiliser les fonctions app(), tapp() et lapp().
Elles sont plus efficaces, et donc préférables pour les grands jeux de données raster.
De plus, elles vous permettent d’enregistrer directement un fichier de sortie.
La fonction app() applique une fonction à chaque cellule d’une couche matricielle et est utilisée pour résumer (par exemple, en calculant la somme) les valeurs de plusieurs couches en une seule couche.
tapp() est une extension de app(), nous permettant de sélectionner un sous-ensemble de couches (voir l’argument index) pour lesquelles nous voulons effectuer une certaine opération.
Enfin, la fonction lapp() permet d’appliquer une fonction à chaque cellule en utilisant les couches comme arguments – une application de lapp() est présentée ci-dessous.
Le calcul du normalized difference vegetation index (NDVI) est une opération raster locale (pixel par pixel) bien connue. Elle produit un raster dont les valeurs sont comprises entre -1 et 1 ; les valeurs positives indiquent la présence de plantes vivantes (le plus souvent > 0,2). Le NDVI est calculé à partir des bandes rouge et proche infrarouge (NIR) d’images de télédétection, généralement issues de systèmes satellitaires tels que Landsat ou Sentinel. La végétation absorbe fortement la lumière dans le spectre de la lumière visible, et surtout dans le canal rouge, tout en réfléchissant la lumière NIR, ce qui explique la formule du NDVI :
\[ \begin{split} NDVI&= \frac{\text{NIR} - \text{Red}}{\text{NIR} + \text{Red}}\\ \end{split} \]
Calculons le NDVI pour l’image satellite multispectrale du parc National de Zion.
multi_raster_file = system.file("raster/landsat.tif", package = "spDataLarge")
multi_rast = rast(multi_raster_file)L’objet raster comporte quatre bandes de satellite - bleu, vert, rouge et proche infrarouge (NIR). Notre prochaine étape va être d’implémenter la formule NDVI dans une fonction R :
ndvi_fun = function(nir, red){
(nir - red) / (nir + red)
}Cette fonction accepte deux arguments numériques, nir et red, et retourne un vecteur numérique avec les valeurs NDVI.
Elle peut être utilisée comme argument fun de lapp().
Nous devons juste nous rappeler que notre fonction n’a besoin que de deux bandes (et non de quatre comme dans le raster original), et qu’elles doivent être dans l’ordre NIR puis red.
C’est pourquoi nous sélection la grille d’entrée avec multi_rast[[c(4, 3)]] avant d’effectuer tout calcul.
Le résultat, présenté sur le panneau de droite de la figure 4.12, peut être comparé à l’image RVB de la même zone (panneau de gauche de la même figure). Il nous permet de constater que les plus grandes valeurs de NDVI sont liées aux zones de forêt dense dans les parties nord de la zone, tandis que les valeurs les plus faibles sont liées au lac au nord et aux crêtes montagneuses enneigées.

FIGURE 4.12: Image RVB (à gauche) et valeurs NDVI (à droite) calculées pour l’exemple de l’image satellite du parc National de Zion.
La cartographie prédictive est une autre application intéressante des opérations raster locales.
La variable de réponse correspond à des points mesurés ou observés dans l’espace, par exemple, la richesse des espèces, la présence de glissements de terrain, les maladies des arbres ou le rendement des cultures.
Par conséquent, nous pouvons facilement récupérer des variables prédictives spatiales ou aériennes à partir de divers rasters (élévation, pH, précipitations, température, couverture végétale, classe de sol, etc.)
Ensuite, nous modélisons notre réponse en fonction de nos prédicteurs en utilisant lm(), glm(), gam() ou une technique d’apprentissage automatique.
Les prédictions spatiales sur les objets raster peuvent donc être réalisées en appliquant des coefficients estimés aux valeurs de chaque cellule, et en additionnant les valeurs raster de sortie (voir chapitre ??).
4.3.4 Operations focales
Alors que les fonctions locales opèrent sur une cellule, bien que pouvant provenir de plusieurs couches, les opérations focales prennent en compte une cellule centrale (focale) et ses voisines. Le voisinage (également appelé noyau, filtre ou fenêtre mobile) utilisé est généralement de le taille 3 par 3 cellules (c’est-à-dire la cellule centrale et ses huit voisines), mais peut prendre toute autre forme (pas nécessairement rectangulaire) définie par l’utilisateur. Une opération focale applique une fonction d’agrégation à toutes les cellules du voisinage spécifié, utilise la sortie correspondante comme nouvelle valeur pour la cellule centrale, puis passe à la cellule centrale suivante (figure 4.13). Cette opération est également appelée filtrage spatial et convolution (Burrough, McDonnell, and Lloyd 2015).
Dans R, nous pouvons utiliser la fonction focal() pour effectuer un filtrage spatial.
Nous définissons la forme de la fenêtre mobile avec une matrice dont les valeurs correspondent aux poids (voir le paramètre w dans le code ci-dessous).
Ensuite, le paramètre fun nous permet de spécifier la fonction que nous souhaitons appliquer à ce voisinage.
Ici, nous choisissons le minimum, mais toute autre fonction de résumé, y compris sum(), mean(), ou var() peut être utilisée.
Cette fonction accepte également des arguments supplémentaires, par exemple, si elle doit supprimer les NAs dans le processus (na.rm = TRUE) ou non (na.rm = FALSE).
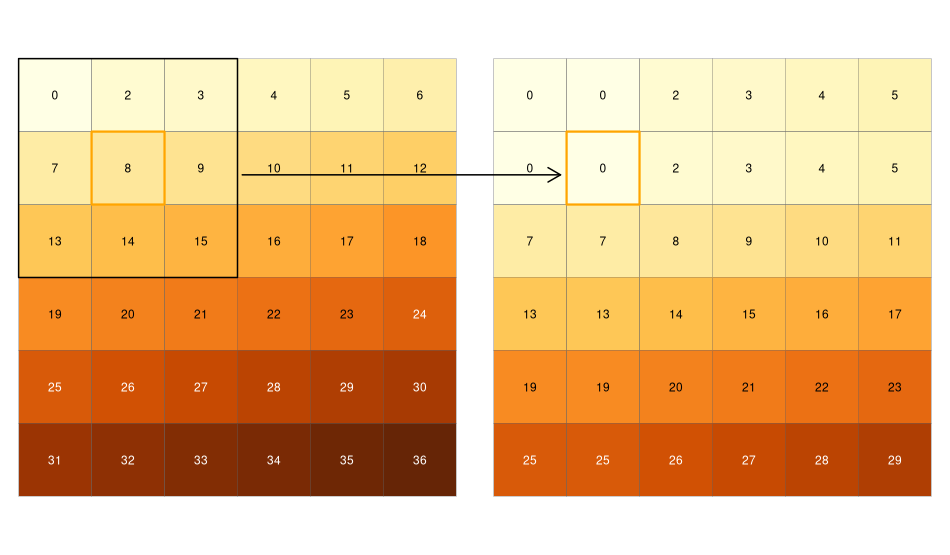
FIGURE 4.13: Raster d’entrée (gauche) et raster de sortie (droite) suite à une opération focale - trouver la valeur minimale dans des fenêtres mobiles 3 par 3.
Nous pouvons rapidement vérifier si le résultat correspond à nos attentes. En effet, dans notre exemple, la valeur minimale doit toujours se situer dans le coin supérieur gauche de la fenêtre mobile (rappelez-vous que nous avons créé le raster d’entrée en incrémentant les valeurs des cellules d’une unité par ligne, en commençant par le coin supérieur gauche). Dans cet exemple, la matrice de pondération est composée uniquement de 1, ce qui signifie que chaque cellule a le même poids sur la sortie, mais cela peut être modifié.
Les fonctions ou filtres focaux jouent un rôle dominant dans le traitement des images.
Les filtres “passe-bas” (low-pass) ou de lissage utilisent la fonction moyenne pour éliminer les valeurs extrêmes.
Dans le cas de données catégorielles, on peut remplacer la moyenne par le mode, qui est la valeur la plus courante.
En revanche, les filtres “passe-haut” accentuent les entités.
Les filtres Laplace et Sobel de détection de lignes peuvent servir d’exemple ici.
Consultez la page d’aide focal() pour savoir comment les utiliser dans R (ils seront également utilisés dans les exercices à la fin de ce chapitre).
Le traitement des données numériques de terrain, le calcul des caractéristiques topographiques telles que la pente, l’aspect et les directions d’écoulement, repose sur des fonctions focales.
La fonction de terra terrain() peut être utilisé pour calculer ces métriques, bien que certains algorithmes de traitement des données numériques de terrain, y compris la méthode de Zevenbergen et Thorne pour calculer la pente, n’y soient pas implémentés.
De nombreux autres algorithmes — notamment les courbures, les zones contributives et les indices d’humidité — sont mis en œuvre dans des logiciels libres de systèmes d’information géographique (SIG) de bureau.
Le chapitre ?? montre comment accéder à ces fonctionnalités SIG à partir de R.
4.3.5 Opérations Zonales
Tout comme les opérations focales, les opérations zonales appliquent une fonction d’agrégation à plusieurs cellules.
Cependant, un deuxième raster, généralement avec des valeurs catégorielles, définit les filtres zonaux (ou ‘zones’) dans le cas des opérations zonales, en opposition à une fenêtre de voisinage prédéfinie dans le cas de l’opération focale.
Par conséquent, les cellules définissant le filtre zonal ne doivent pas nécessairement être voisines.
Notre raster grain en est un bon exemple, comme l’illustre le panneau de droite de la figure 3.2 : différentes tailles de granulométrie sont réparties de manière irrégulière dans le raster.
Enfin, le résultat d’une opération zonale est un tableau récapitulatif groupé par zone, c’est pourquoi cette opération est également connue sous le nom de statistiques zonales dans le monde des SIG.
Ceci est à l’opposé des opérations focales qui retournent un objet matriciel.
Le code suivant utilise la fonction zonal() pour calculer l’altitude moyenne associée à chaque classe de taille de grain.
z = zonal(elev, grain, fun = "mean")
z
#> grain elev
#> 1 clay 14.8
#> 2 silt 21.2
#> 3 sand 18.7ceci renvoie les statistiques pour chaque catégorie, ici l’altitude moyenne pour chaque classe de granulométrie.
Remarque : il est aussi possible d’obtenir un raster avec les statistiques calculées pour chaque zone en mettant l’argument as.raster à TRUE.
4.3.6 Opérations globales et distances
Les opérations globales sont un cas particulier des opérations zonales, l’ensemble des données raster représentant une seule zone. Les opérations globales les plus courantes sont des statistiques descriptives pour l’ensemble des données raster, telles que le minimum ou le maximum, que nous avons déjà abordées dans la section ??.
En dehors de cela, les opérations globales sont également utiles pour le calcul des rasters de distance et de poids.
Dans le premier cas, on peut calculer la distance entre chaque cellule et une cellule cible spécifique.
Par exemple, on peut vouloir calculer la distance à la côte la plus proche (voir aussi terra::distance()).
On peut aussi vouloir prendre en compte la topographie, c’est-à-dire qu’on n’est pas seulement intéressé par la distance pure mais qu’on voudrait aussi éviter de traverser des chaînes de montagnes en allant vers la côte.
Pour ce faire, nous pouvons pondérer la distance par l’altitude de sorte que chaque mètre d’altitude supplémentaire “prolonge” la distance euclidienne.
Les calculs de visibilité et de bassin visuel appartiennent également à la famille des opérations globales (dans les exercices du chapitre ??, vous calculerez un raster de bassin visuel).
4.3.7 Les contreparties de l’algèbre raster dans le traitement vectoriel
De nombreuses opérations d’algèbre raster ont une contrepartie dans le traitement vectoriel (Liu and Mason 2009).
Le calcul d’une distance raster (opération globale) en ne considérant qu’une distance maximale (opération focale logique) est l’équivalent d’une opération de mise en mémoire tampon vectorielle (section 5.2.5).
Le reclassement de données raster (fonction locale ou zonale selon l’entrée) est équivalent à la dissolution de données vectorielles (section ??).
La superposition de deux données matricielles (opération locale), dont l’une contient des valeurs NULL ou NA représentant un masque, est similaire au découpage vectoriel (Section `(ref?)(clipping)).
L’intersection de deux couches est tout à fait similaire au détourage spatial (section ??).
La différence est que ces deux couches (vectorielles ou matricielles) partagent simplement une zone de chevauchement (voir la figure 5.8 pour un exemple).
Cependant, faites attention à la formulation.
Parfois, les mêmes mots ont des significations légèrement différentes pour les modèles de données rasters et vectorielles.
Dans le cas des données vectorielles, l’agrégation consiste à dissoudre les polygones, tandis que dans le cas des données rasters, elle consiste à augmenter la résolution.
En fait, on pourrait considérer que dissoudre ou agréger des polygones revient à diminuer la résolution.
Cependant, les opérations zonales semble être le meilleur équivalent raster par rapport à la modification de la résolution des cellules.
Les opérations zonales peuvent dissoudre les cellules d’un raster en fonction des zones (catégories) d’un autre raster en utilisant une fonction d’agrégation (voir ci-dessus).
4.3.8 Fusionner des rasters
Supposons que nous voulions calculer le NDVI (voir la section ??), et que nous voulions en plus calculer les attributs du terrain à partir des données d’altitude pour des observations dans une zone d’étude.
Ces calculs reposent sur des informations de télédétection.
L’imagerie correspondante est souvent divisée en tuiles couvrant une étendue spatiale spécifique, et fréquemment, une zone d’étude couvre plus d’une tuile.
Dans ce cas, nous devons fusionner les tuiles couvertes par notre zone d’étude.
Le plus simple est alors de fusionner ces scènes, c’est-à-dire les mettre côte à côte.
Cela est possible, par exemple, avec les données numériques d’altitude (SRTM, ASTER).
Dans l’extrait de code suivant, nous téléchargeons d’abord les données d’élévation SRTM pour l’Autriche et la Suisse (pour les codes pays, voir la fonction geodata country_codes()).
Dans une seconde étape, nous fusionnons les deux rasters en un seul.
aut = geodata::elevation_30s(country = "AUT", path = tempdir())
ch = geodata::elevation_30s(country = "CHE", path = tempdir())
aut_ch = merge(aut, ch)La commande merge() de terra combine deux images, et dans le cas où elles se chevauchent, elle utilise la valeur du premier raster.
cette approche de fusion est peu utile lorsque les valeurs qui se chevauchent ne correspondent pas les unes aux autres.
C’est souvent le cas lorsque vous voulez combiner des images spectrales provenant de scènes qui ont été prises à des dates différentes.
La commande merge() fonctionnera toujours mais vous verrez une frontière nette dans l’image résultante.
D’autre part, la commande mosaic() vous permet de définir une fonction pour la zone de recouvrement.
Par exemple, nous pourrions calculer la valeur moyenne – cela pourrait lisser la bordure claire dans le résultat fusionné, mais ne la fera probablement pas disparaître.
Pour une introduction plus détaillée à la télédétection avec R, il est possible de consulter Wegmann, Leutner, and Dech (2016).
4.4 Exercises
E1. Il a été établi dans la section 4.2 que Canterbury était la région de Nouvelle-Zélande contenant la plupart des 100 points les plus élevés du pays. Combien de ces points culminants en contient-elle ?
Bonus: Représentez le résultat en utilisant la fonction plot() en montrant toute la Nouvelle-Zélande, la région canterbury surlignée en jaune, les points hauts de Canterbury représentés par des points noirs
E2. Dans quelle région se trouve le deuxième plus grand nombre de points nz_height, et combien en compte-t-elle ?
E3. En généralisant la question à toutes les régions : combien les 16 régions de la Nouvelle-Zélande contiennent des points qui font partie des 100 plus hauts points du pays ? Quelles régions ?
- Bonus: créer un tableau listant ces régions dans l’ordre du nombre de points et de leurs noms.
E4. Testez vos connaissances des prédicats spatiaux en découvrant et en représentant graphiquement les relations entre les États américains et d’autres objets spatiaux.
Le point de départ de cet exercice est de créer un objet représentant l’état du Colorado aux USA. Faites-le avec la commande
colorado = us_states[us_states$NAME == "Colorado",] (base R) ou avec la fonction filter() (tidyverse) et affichez l’objet résultant dans le contexte des états américains.
- Créez un nouvel objet représentant tous les états qui ont une intersection géographique avec le Colorado et tracez le résultat (astuce : la façon la plus concise de le faire est d’utiliser la méthode de sous-ensemble
[). - Créez un autre objet représentant tous les objets qui touchent (ont une frontière commune avec) le Colorado et tracez le résultat (conseil : n’oubliez pas que vous pouvez utiliser l’argument
op = st_intersectset d’autres relations spatiales pendant les opérations de sous-ensembles spatiaux dans R de base). - Bonus : créez une ligne droite du centroïde du District de Columbia, près de la côte Est, au centroïde de la Californie, près de la côte Ouest des Etats-Unis (astuce : les fonctions
st_centroid(),st_union()etst_cast()décrites au Chapitre 5 peuvent vous aider) et identifiez les états que cette longue ligne Est-Ouest traverse.
E5. Utilisez le dem = rast(system.file("raster/dem.tif", package = "spDataLarge")), et reclassifiez l’altitude en trois classes : basse (<300), moyenne et haute (>500).
Ensuite, Chargez le raster NDVI (ndvi = rast(system.file("raster/ndvi.tif", package = "spDataLarge"))) et calculez le NDVI moyen et l’altitude moyenne pour chaque classe altitudinale.
E6. Appliquez un filtre de détection de ligne à rast(system.file("ex/logo.tif", package = "terra")).
Affichez le résultat.
Astuce : lisez ?terra::focal().
E7. Calculez l’indice Normalized Difference Water Index (NDWI ; (green - nir)/(green + nir)) d’une image Landsat.
Utilisez l’image Landsat fournie par le paquet spDataLarge (system.file("raster/landsat.tif", package = "spDataLarge")).
Calculez également une corrélation entre le NDVI et le NDWI pour cette zone.
E8. Un billet de StackOverflow montre comment calculer les distances à la côte la plus proche en utilisant raster::distance().
Essayez de faire quelque chose de similaire mais avec terra::distance() : récupérez le modèle numérique de terrain espagnole, et obtenez un raster qui représente les distances à la côte à travers le pays (astuce : utilisez geodata::elevation_30s()).
Convertissez les distances résultantes de mètres en kilomètres.
Remarque : il peut être judicieux d’augmenter la taille des cellules de l’image matricielle d’entrée pour réduire le temps de calcul pendant cette opération.
E9. Essayez de modifier l’approche utilisée dans l’exercice ci-dessus en pondérant le raster de distance avec le raster d’altitude ; chaque 100 mètres d’altitude devrait augmenter la distance à la côte de 10 km. Ensuite, calculez et visualisez la différence entre le raster créé en utilisant la distance euclidienne (E7) et le raster pondéré par l’altitude.